Background
Our team was building a Serverless Framework API for a client that wanted to use the Serverless Dashboard for deployment and monitoring. Based on some challenges from last year, we agreed with the client that using a monorepo tool like Nx would be beneficial moving forward as we were potentially shipping multiple Serverless APIs and frontend applications. Unfortunately, we discovered several challenges integrating with the Serverless Dashboard, and eventually opted into custom CI/CD with GitHub Actions. We’ll cover the challenges we faced, and the solution we created to mitigate our problems and generate a solution.
Serverless Configuration Restrictions
By default, the Serverless Framework does all its configuration via a serverless.yml file. However, the framework officially supports alternative formats including .json, .js, and .ts.
Our team opted into the TypeScript format as we wanted to setup some validation for our engineers that were newer to the framework through type checks. When we eventually went to configure our CI/CD via the Serverless Dashboard UI, the dashboard itself restricted the file format to just the YAML format. This was unfortunate, but we were able to quickly revert back to YAML as configuration was relatively simple, and we were able to bypass this hurdle.

Prohibitive Project Structures
With our configuration now working, we were able to select the project, and launch our first attempt at deploying the app through the dashboard. Immediately, we ran into a build issue:
Build step: serverless deploy --stage dev --region us-west-1 --force --org my-org --app my-app --verbose
Environment: linux, node 14.19.2, framework 3.21.0 (local), plugin 6.2.2, SDK 4.3.2
Docs: docs.serverless.com
Support: forum.serverless.com
Bugs: github.com/serverless/serverless/issues
Error:
Serverless plugin "serverless-esbuild" not found. Make sure it's installed and listed in the "plugins" section of your serverless config file. Run "serverless plugin install -n serverless-esbuild" to install it.
Build step failed: serverless deploy --stage dev --region us-west-1 --force --org my-org --app my-app --verbose
What we found was having our package.json in a parent directory of our serverless app prevented the dashboard CI/CD from being able to appropriately detect and resolve dependencies prior to deployment. We had been deploying using an Nx command: npx nx run api:deploy --stage=dev which was able to resolve our dependency tree which looked like:
To resolve, we thought maybe we could customize the build commands utilized by the dashboard. Unfortunately, the only way to customize these commands is via the package.json of our project. Nx allows for package.json per app in their structure, but it defeated the purpose of us opting into Nx and made leveraging the tool nearly obsolete.
Moving to GitHub Actions with the Serverless Dashboard
We thought to move all of our CI/CD to GitHub Actions while still proxying the dashboard for deployment credentials and monitoring. In the dashboard docs, we found that you could set a SERVERLESS_ACCESS_KEY and still deploy through the dashboard. It took us a few attempts to understand exactly how to specify this key in our action code, but eventually, we discovered that it had to be set explicitly in the .env file due to the usage of the Nx build system to deploy. Thus the following actions were born:
api-ci.yml
name: API Linting, Testing, and Deployment
on:
push:
branches: [main]
pull_request:
workflow_dispatch:
jobs:
api-deploy:
runs-on: ubuntu-latest
strategy:
matrix:
node-version: [14.x]
steps:
- name: Checkout Repo
uses: actions/checkout@v3
- name: Configure Node
uses: actions/setup-node@v3
with:
node-version: '14.x'
cache: 'yarn'
- name: Install packages
run: yarn install --frozen-lockfile
- name: Create .env file for testing
run: |
cp .env.example .env.test
- name: Run tests
run: npx nx run api:test
- name: Create .env file for deployment
run: |
touch .env
echo SERVERLESS_ACCESS_KEY=${{ secrets.SERVERLESS_ACCESS_KEY }} >> .env
cat .env
- name: Deploy SLS Preview
if: github.ref != 'refs/heads/main'
run: npx nx run api:deploy --stage=${GITHUB_HEAD_REF}
- name: Deploy SLS Dev
if: github.ref == 'refs/heads/main'
run: npx nx run api:deploy --stage=dev
api-clean.yml
name: API Clean Up
# When pull requests are closed the associated
# branch will be removed from SLS deploy
on:
pull_request:
types: [closed]
jobs:
tear-down:
runs-on: ubuntu-latest
strategy:
matrix:
node-version: [14.x]
steps:
- name: Checkout Repo
uses: actions/checkout@v3
- name: Configure Node
uses: actions/setup-node@v3
with:
node-version: '14.x'
cache: 'yarn'
- name: Install packages
run: yarn install --frozen-lockfile
- name: Create .env file for teardown
run: |
touch .env
echo SERVERLESS_ACCESS_KEY=${{ secrets.SERVERLESS_ACCESS_KEY }} >> .env
cat .env
- name: Deploy SLS
run: npx nx run api:teardown --stage=${GITHUB_HEAD_REF}
These actions ran smoothly and allowed us to leverage the dashboard appropriately. All in all this seemed like a success.
Local Development Problems
The above is a great solution if your team is willing to pay for everyone to have a seat on the dashboard. Unfortunately, our client wanted to avoid the cost of additional seats because the pricing was too high. Why is this a problem? Our configuration looks similar to this (I’ve highlighted the important lines with a comment):
serverless.ts
import type { Serverless } from 'serverless/aws';
const serverlessConfiguration: Serverless = {
service: 'our-service',
app: 'our-app', // NOTE THIS
org: 'our-org', // NOTE THIS
frameworkVersion: '3',
useDotenv: true,
plugins: [...],
custom: { ... },
package: { ... },
provider: {
name: 'aws',
runtime: 'nodejs14.x',
stage: "${opt:stage, 'dev'}",
region: "${opt:region, 'us-east-1'}",
memorySize: 512,
timeout: 29,
httpApi: { cors: true },
environment: {
REGION: '${aws:region}',
SLS_STAGE: '${sls:stage}',
SOME_SECRET: '${param:SOME_SECRET, env:SOME_SECRET}', // NOTE THIS
},
},
functions: {
graphql: {
handler: 'src/handlers/graphql.server',
events: [
{
httpApi: {
method: 'post',
path: '/graphql',
},
},
{
httpApi: {
method: 'get',
path: '/graphql',
},
},
],
},
},
};
module.exports = serverlessConfiguration;
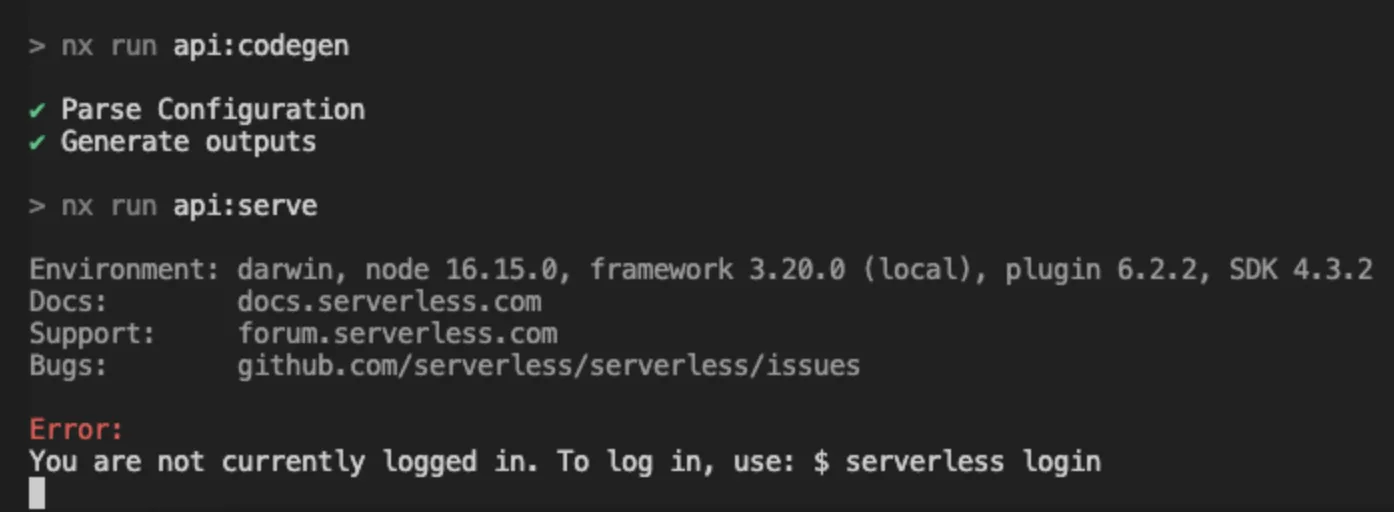
The app and org variables make it so it is required to have a valid dashboard login. This meant our developers working on the API problems couldn’t do local development because the client was not paying for the dashboard logins. They would get the following error:
Resulting Configuration
At this point, we had to opt to bypass the dashboard entirely via CI/CD. We had to make the following changes to our actions and configuration to get everything 100% working:
serverless.ts
- Remove app and org fields
- Remove accessing environment secrets via the
paramoption
import type { Serverless } from 'serverless/aws';
const serverlessConfiguration: Serverless = {
service: 'our-service',
frameworkVersion: '3',
useDotenv: true,
plugins: [...],
custom: { ... },
package: { ... },
provider: {
name: 'aws',
runtime: 'nodejs14.x',
stage: "${opt:stage, 'dev'}",
region: "${opt:region, 'us-east-1'}",
memorySize: 512, // default: 1024MB
timeout: 29,
httpApi: { cors: true },
environment: {
REGION: '${aws:region}',
SLS_STAGE: '${sls:stage}',
SOME_SECRET: '${env:SOME_SECRET}',
},
},
functions: {
graphql: {
handler: 'src/handlers/graphql.server',
events: [
{
httpApi: {
method: 'post',
path: '/graphql',
},
},
{
httpApi: {
method: 'get',
path: '/graphql',
},
},
],
},
},
};
module.exports = serverlessConfiguration;
api-ci.yml
- Add all our secrets to GitHub and include them in the scripts
- Add serverless confg
name: API Linting, Testing, and Deployment
on:
push:
branches: [main]
pull_request:
workflow_dispatch:
jobs:
api-deploy:
runs-on: ubuntu-latest
strategy:
matrix:
node-version: [14.x]
steps:
- name: Checkout Repo
uses: actions/checkout@v3
- name: Configure Node
uses: actions/setup-node@v3
with:
node-version: '14.x'
cache: 'yarn'
- name: Install packages
run: yarn install --frozen-lockfile
- name: Create .env file for testing
run: |
cp .env.example .env.test
- name: Run tests
run: npx nx run api:test
- name: Configure credentials
run: |
npx serverless config credentials --provider aws --key $AWS_ACCESS_KEY_ID --secret $AWS_SECRET_ACCESS_KEY
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
- name: Create .env file for deployment
run: |
touch .env
echo SOME_SECRET=${{ secrets.SOME_SECRET }} >> .env
# other keys here
cat .env
- name: Deploy SLS Preview
if: github.ref != 'refs/heads/main'
run: npx nx run api:deploy --stage=${GITHUB_HEAD_REF}
- name: Deploy SLS Dev
if: github.ref == 'refs/heads/main'
run: npx nx run api:deploy --stage=dev
api-cleanup.yml
- Add serverless config
- Remove secrets
name: API Clean Up
# When pull requests are closed, the associated
# branch will be removed from SLS deploy
on:
pull_request:
types: [closed]
jobs:
tear-down:
runs-on: ubuntu-latest
strategy:
matrix:
node-version: [14.x]
steps:
- name: Checkout Repo
uses: actions/checkout@v3
- name: Configure Node
uses: actions/setup-node@v3
with:
node-version: '14.x'
cache: 'yarn'
- name: Install packages
run: yarn install --frozen-lockfile
- name: Configure credentials
run: |
npx serverless config credentials --provider aws --key $AWS_ACCESS_KEY_ID --secret $AWS_SECRET_ACCESS_KEY
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
- name: Create .env file for teardown
run: |
touch .env
echo SERVERLESS_ACCESS_KEY=${{ secrets.SERVERLESS_ACCESS_KEY }} >> .env
cat .env
- name: Deploy SLS
run: npx nx run api:teardown --stage=${GITHUB_HEAD_REF}
Conclusions
The Serverless Dashboard is a great product for monitoring and seamless deployment in simple applications, but it still has a ways to go to support different architectures and setups while being scalable for teams. I hope to see them make the following changes:
- Add support for different configuration file types
- Add better support custom deployment commands
- Update the framework to not fail on login so local development works regardless of dashboard credentials
The Nx + GitHub actions setup was a bit unnatural as well with the reliance on the .env file existing, so we hope the above action code will help someone in the future. That being said, we’ve been working with this on the team and it’s been a very seamless and positive change as our developers can quickly reference their deploys and know how to interact with Lambda directly for debugging issues already.




