
Taming Forms With react-hook-form
After some time of doing repetitive tasks like handling forms in React.js, you will notice that there is a lot of boilerplate code that can be abstracted into reusable custom hooks. Luckily, there is plenty of existing Open Source solutions. In this case, we will be using react-hook-form.
What is react-hook-form
react-hook-form is a performant, flexible, and extensible form handling library built for React. It exports a custom hook that you can call within your Functional Components, and returns both a register function that you pass as a ref to your input components, and a handleSubmit function to wrap your submit callback.
By returning a register function that will be added to the input component, we can leverage the Uncontrolled Component pattern to make our application faster and more performant, by avoiding unnecessary re-renders.
What are we going to build?
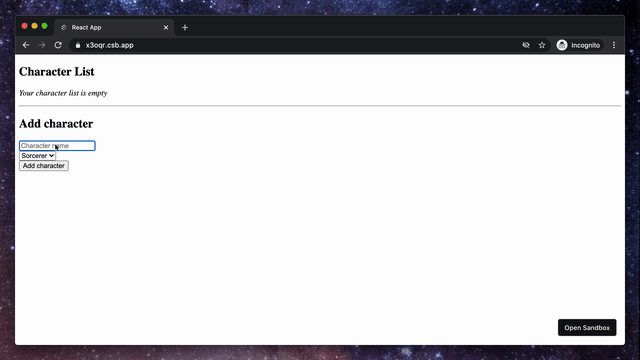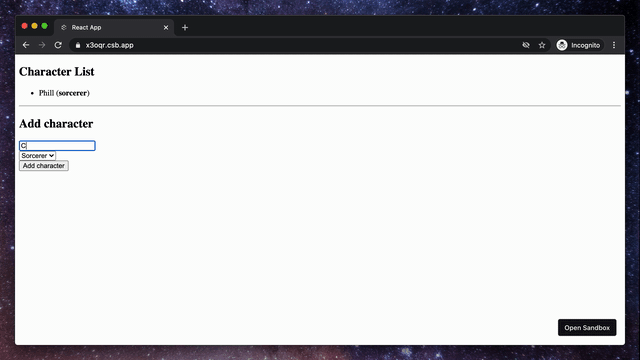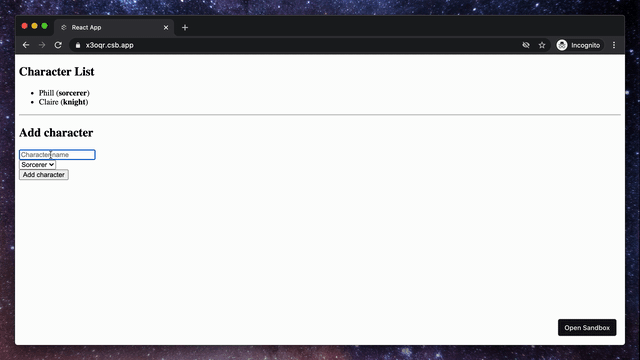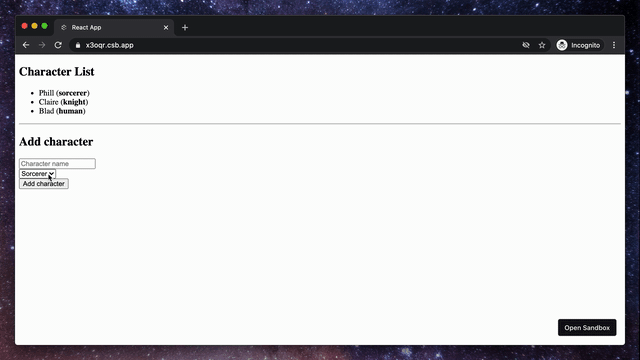
To get a better understanding of what react-hook-form can do, we will build a simple application showing a list of characters and a form to add them to our list.
Application Setup
Before going right into react-hook-form, we will need to prepare our application with the basic file structure and functionality. For this, we will create a new react application (you can either use your preferred starter or cloud IDE).
If you want to skip the application setup, you can go ahead and fork this CodeSandbox, but I highly recommend you at least read this section to have a better understanding of what the app does.
1. Characters List
Let's start by creating a new component where we will display our characters.
character-list.js
import React from "react";
function CharacterList({ characters }) {
return (
<div>
<h2>Character List</h2>
{characters.length === 0 ? (
<p>
<em>Your character list is empty</em>
</p>
) : (
<ul>
{characters.map((character, id) => (
<li key={id}>
{character.name} (<strong>{character.species}</strong>)
</li>
))}
</ul>
)}
</div>
);
}
export default CharacterList;
If you have a basic understanding of React, you will notice our CharacterList component will receive a characters prop, which is an array of objects with the properties name and species. If the array is empty, we will render a placeholder. Elsewhere, we will render the list.
2. Add Character Form
The second step is to create a component that will render the form to add a new character to our list.
character-form.js
import React from "react";
function CharacterForm({ addCharacter }) {
const onSubmit = (data) => {
addCharacter(data);
};
return (
<div>
<h2>Add character</h2>
<form onSubmit={onSubmit}>
<div>
<input name="name" placeholder="Character name" />
</div>
<div>
<select name="species">
<option value="sorcerer">Sorcerer</option>
<option value="knight">Knight</option>
<option value="human">Human</option>
</select>
</div>
<div>
<button type="submit">Add character</button>
</div>
</form>
</div>
);
}
export default CharacterForm;
By itself, this component won't do anything because we are not doing anything with the collected data, nor validating our fields. This will be the component where we will be working on the next section of this tutorial.
3. The App
Now, let's just create the App component where we will render CharacterList and CharacterForm.
app.js
import React from "react";
import CharacterList from "./character-list";
import CharacterForm from "./character-form";
function App() {
const [characters, setCharacters] = React.useState([]);
const addCharacter = (character) => {
setCharacters((characters) => [...characters, character]);
};
return (
<div>
<CharacterList characters={characters} />
<hr />
<CharacterForm addCharacter={addCharacter} />
</div>
);
}
export default App;
We will be saving our character list in characters by using the React.useState hook, and passing them down to CharacterList. Also, we created an addCharacter function that will just add a new character at the end of the characters list, and pass it to CharacterForm via prop.
Let's get to it!
Now that we have our application setup, let's see how can we leverage react-hook-form to take our forms to the next level.
Install react-hook-form
yarn add react-hook-form
Add react-hook-form to your CharacterForm
Here comes the fun. First, let's import useForm from react-hook-form, call the hook in our component, destructure register and handleSubmit methods out of it (don't worry, I will explain what they do just in a while), wrap our onSubmit function with handleSubmit, and pass register as the ref for each one of our form controls.
character-form.js
import React from "react";
+import { useForm } from "react-hook-form";
function CharacterForm({ addCharacter }) {
+ const { register, handleSubmit } = useForm();
+
- const onSubmit = (data) => {
- addCharacter(data);
- };
+ const onSubmit = handleSubmit((data) => {
+ addCharacter(data);
+ });
return (
<div>
<h2>Add character</h2>
<form onSubmit={onSubmit}>
<div>
- <input name="name" placeholder="Character name" />
+ <input ref={register} name="name" placeholder="Character name" />
</div>
<div>
- <select name="species">
+ <select ref={register} name="species">
<option value="sorcerer">Sorcerer</option>
<option value="knight">Knight</option>
<option value="human">Human</option>
</select>
</div>
<div>
<button type="submit">Add character</button>
</div>
</form>
</div>
);
}
export default CharacterForm;
The register method
By attaching the register ref to our form controls, we can start tracking some stuff like the field value, its validation status, and even if the field had been touched or not.
Important: the name prop is required when passing the register ref, and it should be unique. This way, react-hook-form will know where to assign the field value. For more information, check out the register documentation.
The handleSubmit method
This is a function that wraps our submit callback, and passes the actual form values to it. Under the hood, it also calls preventDefault on the form event to avoid full page reloads. It can also be an asynchronous function.
For more information, check out the handleSubmit documentation.
Add some validations
At this point, we have a working form that is able to add characters to our list. However, we are not checking if the field is filled, in order to avoid empty submissions.
With react-hook-form, it is as simple as calling the register function with a configuration object defining the validation rules. For our case, we will make the name field required. Also, we can extract errors from useForm to show the user if the field has errors.
import React from "react";
import { useForm } from "react-hook-form";
function CharacterForm({ addCharacter }) {
- const { register, handleSubmit } = useForm();
+ const { register, handleSubmit, errors } = useForm();
const onSubmit = handleSubmit((data) => {
addCharacter(data);
});
return (
<div>
<h2>Add character</h2>
<form onSubmit={onSubmit}>
<div>
- <input ref={register} name="name" placeholder="Character name" />
+ <input
+ ref={register({ required: true })}
+ name="name"
+ placeholder="Character name"
+ />
+ {errors.name && errors.name.type === "required"
+ ? "Name is required"
+ : null}
</div>
<div>
<select ref={register} name="species">
<option value="sorcerer">Sorcerer</option>
<option value="knight">Knight</option>
<option value="human">Human</option>
</select>
</div>
<div>
<button type="submit">Add character</button>
</div>
</form>
</div>
);
}
export default CharacterForm;
Reset the form status
The final step is to clear our form after successfully adding a character to our character list. For that, we will destructure a new method from the useForm hook: reset, and call it after addCharacter.
import React from "react";
import { useForm } from "react-hook-form";
function CharacterForm({ addCharacter }) {
- const { register, handleSubmit, errors } = useForm();
+ const { register, handleSubmit, errors, reset } = useForm();
const onSubmit = handleSubmit((data) => {
addCharacter(data);
+ reset();
});
console.log(errors.nameRequired);
return (
<div>
<h2>Add character</h2>
<form onSubmit={onSubmit}>
<div>
<input
ref={register({ required: true })}
name="name"
placeholder="Character name"
/>
{errors.name && errors.name.type === "required"
? "Name is required"
: null}
</div>
<div>
<select ref={register} name="species">
<option value="sorcerer">Sorcerer</option>
<option value="knight">Knight</option>
<option value="human">Human</option>
</select>
</div>
<div>
<button type="submit">Add character</button>
</div>
</form>
</div>
);
}
export default CharacterForm;
For more information, check out the reset documentation.
Moving forward
Now that you have a better sense of how to manage your React forms, you have unlocked a new world of possibilities by using battle-tested and community-validated libraries like react-hook-form.
You can take a look at more advanced use cases, additional resources or even take a look at the full API.
If you want a finished code sample, you can check out this CodeSandbox.




