Tag and Release your project with GitHub Actions Workflows
GitHub Actions is a powerful automation tool that enables developers to automate various workflows in their repositories. One common use case is to automate the process of tagging and releasing new versions of a project. This ensures that your project's releases are properly versioned, documented, and published in a streamlined manner. In this blog post, we will walk you through two GitHub Actions workflows that can help you achieve this.
Understanding GitHub Tags and Releases
GitHub tags and releases are essential features that help manage and communicate the progress and milestones of a project. Let's take a closer look at what they are, why they are useful, and how they can be used effectively.
GitHub Tags
A GitHub tag is a specific reference point in a repository's history that marks a significant point of development, such as a release or a specific commit. Tags are typically used to identify specific versions of a project. They are lightweight and do not contain any additional metadata by default.
Tags are useful for several reasons:
-
Versioning: Tags allow you to assign meaningful version numbers to your project, making it easier to track and reference specific releases.
-
Stability: By tagging stable versions of your project, you can provide users with a reliable and tested codebase.
-
Collaboration: Tags enable contributors to work on specific versions of the project, ensuring that everyone is on the same page.
GitHub Releases
GitHub releases are a way to package and distribute specific versions of your project to users. A release typically includes the source code, compiled binaries, documentation, and release notes. Releases provide a convenient way for users to access and download specific versions of your project.
Releases offer several benefits:
-
Communication: Releases allow you to communicate important information about the changes, improvements, and bug fixes included in a specific version.
-
Distribution: By packaging your project into a release, you make it easier for users to download and use your software.
-
Documentation: Including release notes in a release helps users understand the changes made in each version and any potential compatibility issues.
Effective Use of Tags and Releases
To make the most of GitHub tags and releases, consider the following tips:
-
Semantic Versioning: Follow a consistent versioning scheme, such as semantic versioning (e.g., MAJOR.MINOR.PATCH), to clearly communicate the nature of changes in each release.
-
Release Notes: Provide detailed and concise release notes that highlight the key changes, bug fixes, and new features introduced in each version. This helps users understand the impact of the changes and make informed decisions.
-
Release Automation: Automate the release process using workflows, like the one described in this blog post, to streamline the creation of tags and releases. This saves time and reduces the chances of human error.
By leveraging GitHub tags and releases effectively, you can enhance collaboration, improve communication, and provide a better experience for users of your project.
The Goal
The idea is to have a GitHub action that, once triggered, updates our project's version, creates a new tag for our repository, and pushes the updates to the main branch. Unfortunately, the main branch is a protected branch, and it's not possible to directly push changes to a protected branch through a GitHub action. Therefore, we need to go through a pull request on the main branch, which, once merged, will apply the changes due to the version update to the main branch.
We had to split the workflow into two different GitHub actions: one that creates a pull request towards the main branch with the necessary code changes to update the repository's version, and another one that creates a new tag and releases the updated main branch. This way, we have one additional click to perform (the one required to merge the PR), but we also have an intermediate step where we can verify that the version update has been carried out correctly.
Let’s dive into these two workflows.
Update version and create Release's PR Workflow
name: Update version and create Release's PR Workflow
on:
workflow_dispatch:
inputs:
version:
description: 'Version name'
required: true
default: 'minor'
type: choice
options:
- major
- minor
- patch
jobs:
version:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Setup Node.js
uses: actions/setup-node@v3
with:
node-version: "16.x"
- name: Install dependencies
run: npm install
- name: Set up Git
run: |
git config user.name "Your GitHub User Name"
git config user.email "Your GitHub User Email"
- name: Update the version
id: update_version
run: |
echo "version=$(npm version ${{ github.event.inputs.version }} --no-git- tag-version)" >> $GITHUB_OUTPUT
- name: Update Changelog
id: update_changelog
run: |
sed -i 's/Unreleased/${{ steps.update_version.outputs.version }}/g' CHANGELOG.md
- name: Create pull request
id: create_pr
uses: peter-evans/create-pull-request@v5
with:
token: ${{ secrets.GITHUB_TOKEN }}
branch: release/${{ steps.update_version.outputs.version }}
title: "Release: ${{ steps.update_version.outputs.version }} Pull Request"
body: "This pull request contains the updated package.json with the new release version"
base: main
Walkthrough:
Step 1: Define the Workflow
The workflow starts with specifying the workflow name and the event that triggers it using the on keyword. In this case, the workflow is triggered manually using the "workflow_dispatch" event, which means it can be run on-demand by a user. Additionally, the workflow accepts an input parameter called "version," which allows the user to specify the type of version bump (major, minor, or patch). The workflow_dispatch event allows the user to set the "version" input when running the workflow.
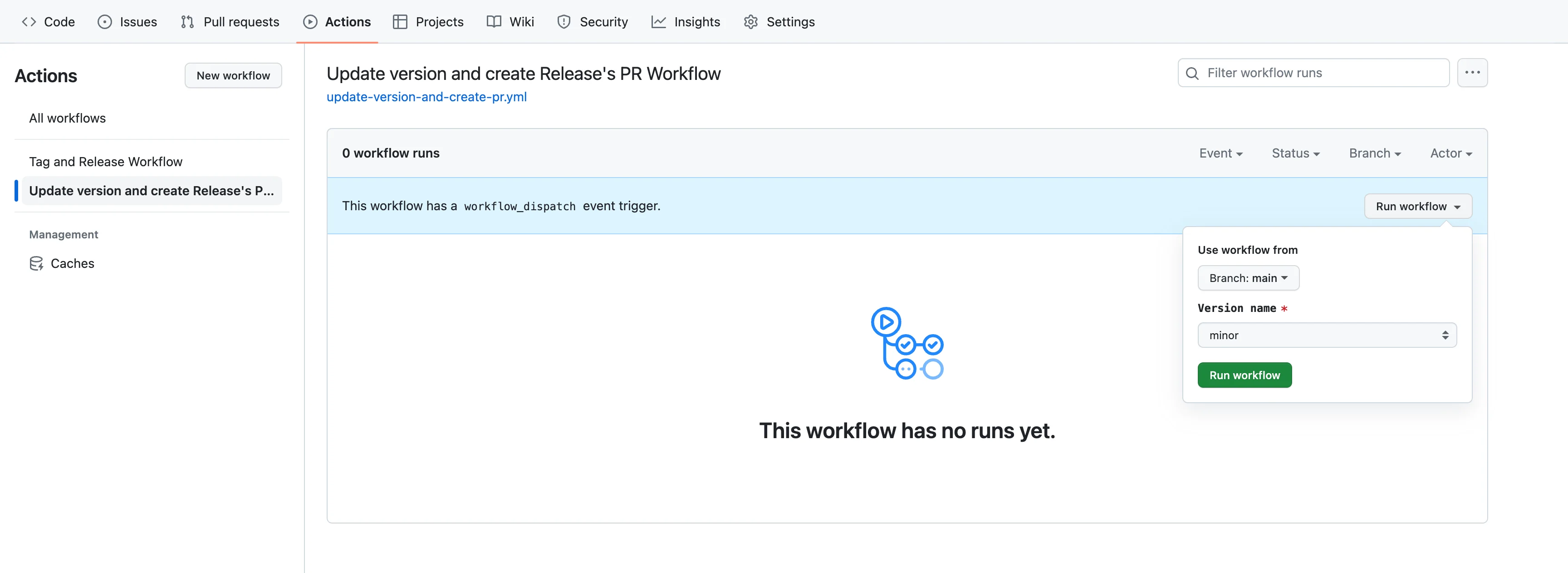
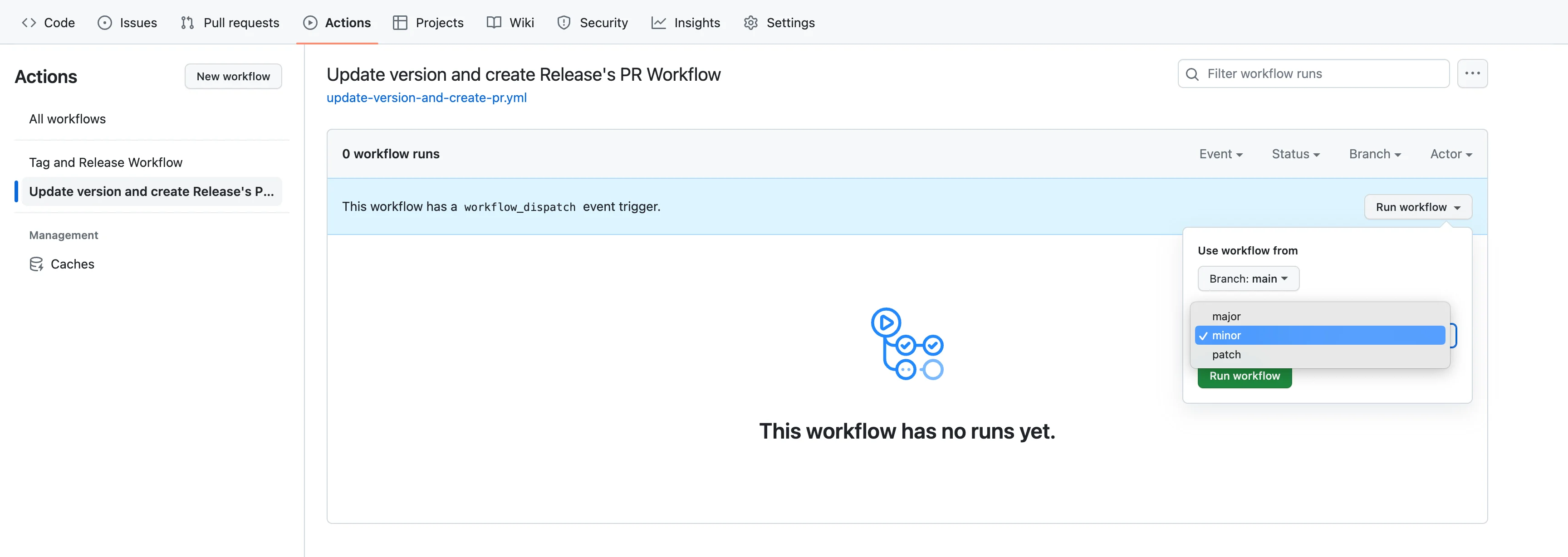
Step 2: Prepare the Environment
The workflow will run on an Ubuntu environment (ubuntu-latest) using a series of steps under the jobs section. The first job is named "version."
Step 3: Checkout the Code
The workflow starts by checking out the code of the repository using the actions/checkout@v3 action. This step ensures that the workflow has access to the latest codebase before making any modifications.
Step 4: Set up Node.js
Next, the workflow sets up the Node.js environment using the actions/setup-node@v3 action and specifying the Node.js version 16.x. It's essential to use the appropriate Node.js version required by your project to avoid compatibility issues.
Step 5: Install Dependencies
To ensure the project's dependencies are up-to-date, the workflow runs npm install to install the necessary packages as defined in the package.json file.
Step 6: Configure Git
To perform version bump and create a pull request, the workflow configures Git with a user name and email. This allows Git to identify the author when making changes in the repository.
Step 7: Update the Version
The workflow now performs the actual version bump using the npm version command. The new version is determined based on the "version" input provided when running the workflow. The updated version number is stored in an output variable named update_version, which can be referenced later in the workflow.
Step 8: Update the Changelog
After bumping the version, the workflow updates the CHANGELOG.md file to reflect the new release version. It replaces the placeholder "Unreleased" with the updated version using the sed command. [We will return to this step later]
Step 9: Create a Pull Request
Finally, the workflow creates a pull request using the peter-evans/create-pull-request@v5 action. This action automatically creates a pull request with the changes made in the workflow. The pull request will have a branch name following the pattern "release/<version> corresponds to the updated version number.
The outcome of this workflow will be a new open PR in the project with package.json and CHANGELOG.md file changed. [we will speak about the changelog file later]
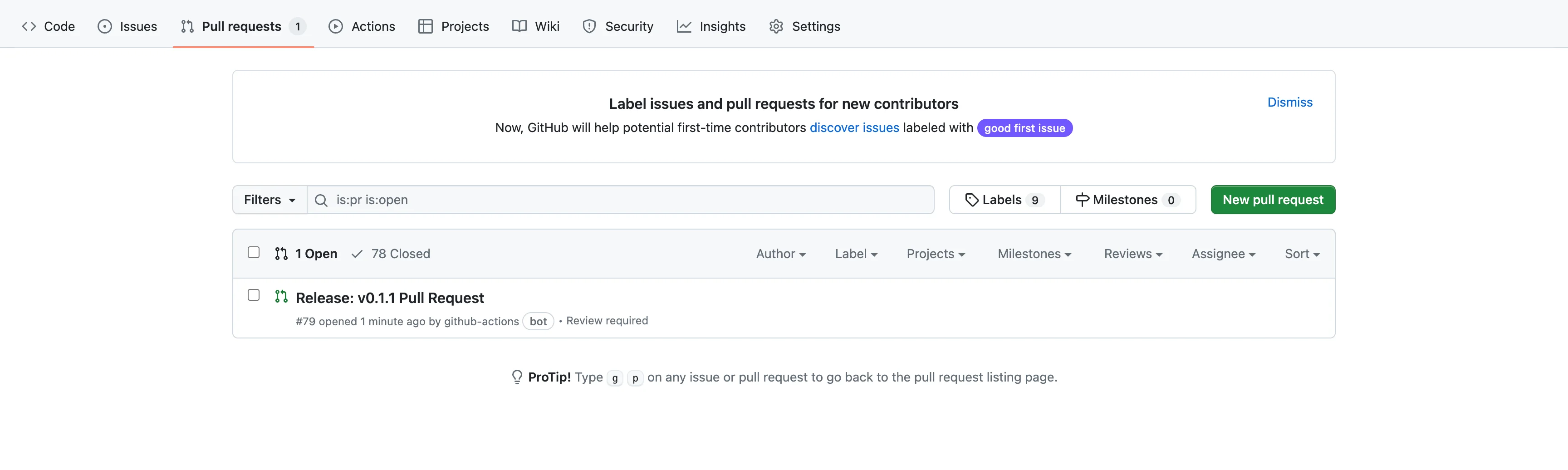
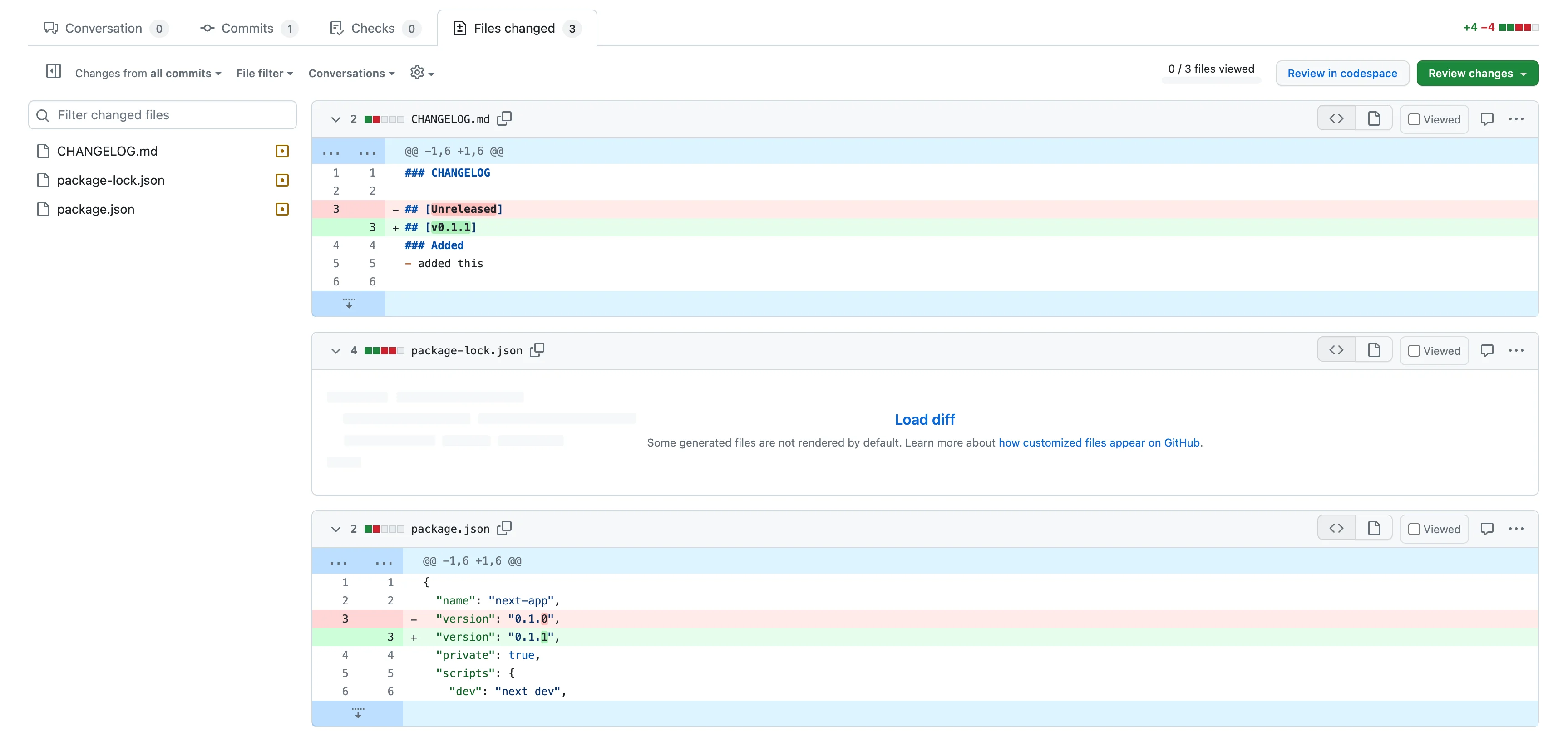
Now we can check if the changes are good, approve the PR and merge it into main. Merge a PR with a title that starts with "Release:" automatically triggers the second workflow
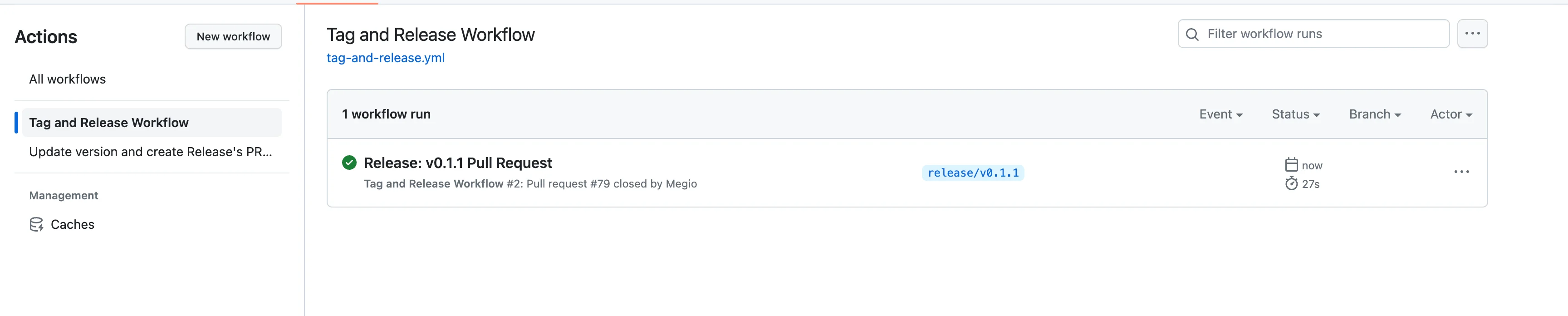
Tag & Release Workflow
name: Tag and Release Workflow
on:
pull_request:
types:
- closed
jobs:
release:
runs-on: ubuntu-latest
if: startsWith(github.event.pull_request.title, 'Release:')
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Setup Node.js
uses: actions/setup-node@v3
with:
node-version: "16.x"
- name: Install dependencies
run: npm install
- name: Build
run: npm run build
- name: Set up Git
run: |
git config user.name "Yout GitHub User name"
git config user.email "Your GitHub User email"
- name: Get tag
id: get_tag
run: |
git branch --show-current
git pull
echo "version=v$(npm pkg get version | tr -d '\"')" >> $GITHUB_OUTPUT
- name: Tag the commit
run: |
next_version=${{ steps.get_tag.outputs.version }}
git tag -a "$next_version" -m "Version $next_version"
git push --follow-tags
- name: Create changelog diff
id: changelog_diff
run: |
sed -n "/^## \[${{ steps.get_tag.outputs.version }}\]/,/^## \[$(git describe --abbrev=0 --tags $(git rev-list --tags --skip=1 --max-count=1))\]/{/^## \[$(git describe --abbrev=0 --tags $(git rev-list --tags --skip=1 --max-count=1))\]/!p;}" CHANGELOG.md > release_notes.md
- name: Create release
id: create_release
uses: actions/create-release@v1
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
with:
tag_name: ${{ steps.get_tag.outputs.version }}
release_name: Release ${{ steps.get_tag.outputs.version }}
body_path: ./release_notes.md
draft: false
prerelease: false
- name: Delete release_notes file
run: rm release_notes.md
Walkthrough:
As you can see we added a check for the PR title before starting the job once the PR is merged and closed. Only the PRs with a title that starts with "Release:" will trigger the workflow. The first three steps are the same as the one described in the previous workflow: we check out the code from the repository, we set up node and we install dependencies. Let's start with:
Step 4: Check formatting
To maintain code quality, we run the npm run format:check command to check if the code adheres to the specified formatting rules. This step helps catch any formatting issues before proceeding further.
Step 5: Build
The npm run build command is executed in this step to build the project. This step is particularly useful for projects that require compilation or bundling before deployment.
Step 6: Set up Git
To perform Git operations, such as tagging and pushing changes, we need to configure the Git user's name and email. This step ensures that the correct user information is associated with the Git actions performed later in the workflow.
Step 7: Get tag
In this step, we retrieve the current version of the project from the package.json file. The version is then stored in an output variable called get_tag.outputs.version for later use.
Step 8: Tag the commit
Using the version obtained in the previous step, we create a Git tag for the commit. The tag is annotated with a message indicating the version number. Finally, we push the tag and associated changes to the repository.
Step 9: Create changelog diff
To generate release notes, we extract the relevant changelog entries from the CHANGELOG.md file.
This step helps summarize the changes made since the previous release. (We will return to this step later)
Step 10: Create release
Using the actions/create-release action, we create a new release on GitHub. The release is associated with the tag created in the previous step, and the release notes are provided in the body of the release.
Step 11: Delete release_notes file
Finally, we delete the temporary release_notes.md file created in Step 9. This step helps keep the repository clean and organized.
Once also the second workflow is finished our project is tagged and the new release has been created.
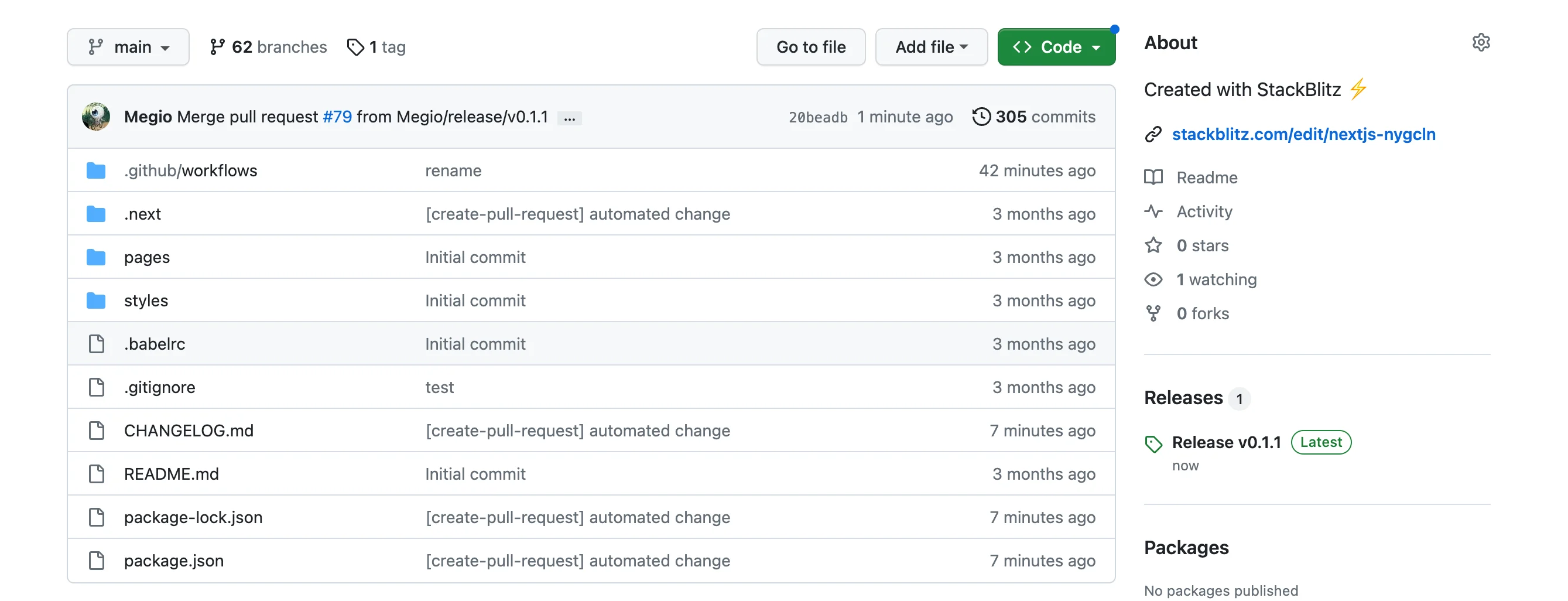
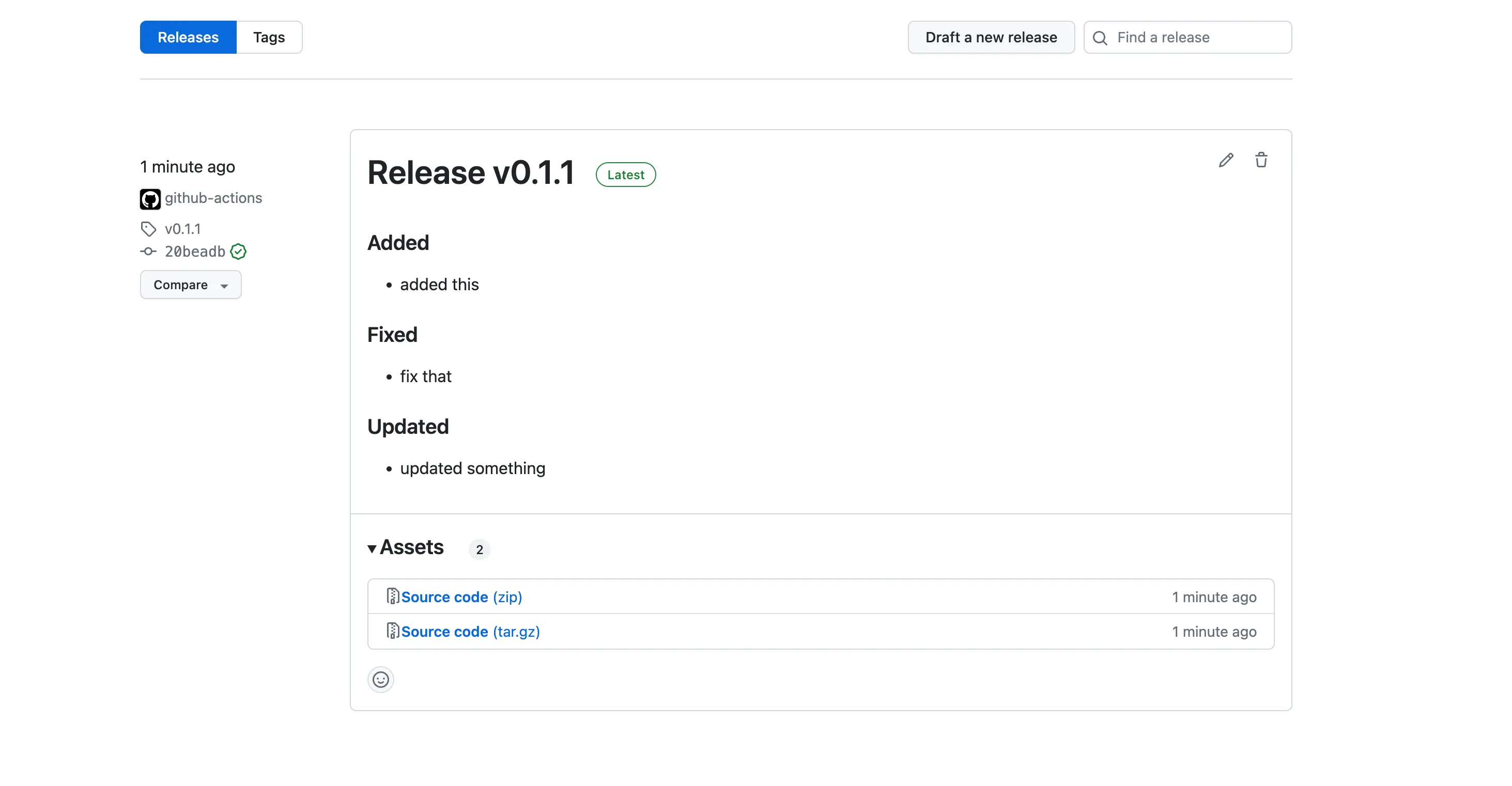
The "Changelog Steps"
As you can see the release notes are automatically filled, with a detailed description of what has been added, fixed, or updated in the project.
This was made possible thanks to the "Changelog steps" in our workflows, but to use them correctly, we need to pay attention to a couple of things while developing our project.
Firstly, to the format of the CHANGELOG.md file. This will be our generic template:
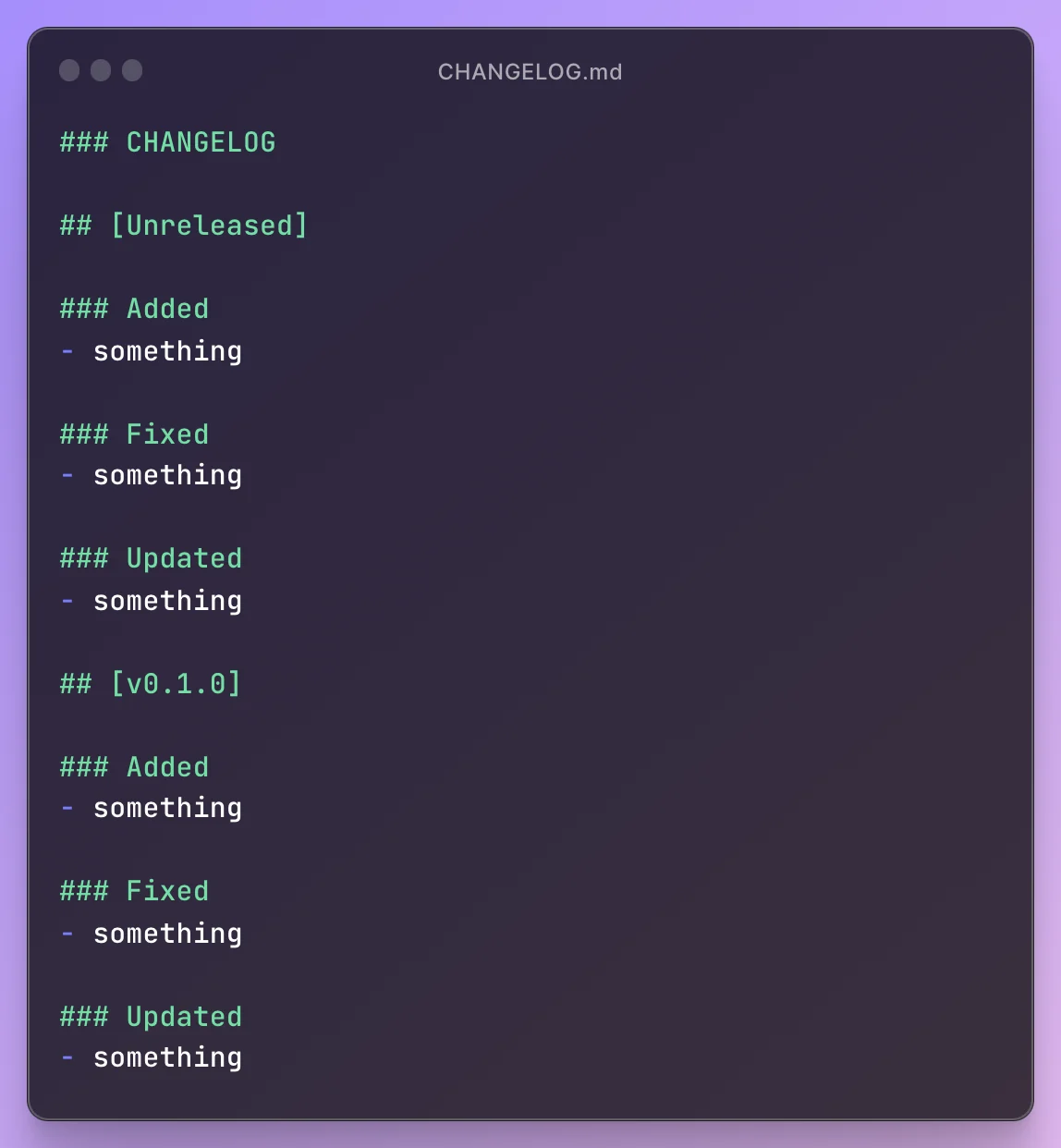
But the most important aspect, in addition to keeping the file up to date during developments by adding the news or improvements we are making to the code under their respective sections, is that every time we start working on a new project release, we begin the paragraph with ## [Unreleased].
This is because, in the first workflow, the step related to the changelog will replace the word "Unreleased" with the newly created project version. In the subsequent workflow, we will create a temporary file (which will then be deleted in the latest step of the workflow), where we will extract the part of the changelog file related to the new version and populate the release notes with it.
Conclusion
Following these Tag and Release Workflows, you can automate the process of creating releases for your GitHub projects. This workflow saves time, ensures consistency, and improves collaboration among team members. Remember to customize the workflow to fit your project's specific requirements and enjoy the benefits of streamlined release management.




