The plugin architecture is a well-known software design pattern used for its flexibility, extensibility, and isolation. It consists of a core system and several separate plugin modules.
We will cover how to create a plugin-based architecture in Angular using its Dependency Injection system and why this is an excellent tool to have in our Engineers belt.
Plugin Architecture
The Plugin Architecture concept is simple: the Core System manages the essential functionalities and orchestrates the Plugins, but it is agnostic of its behavior. The Plugins implement the use-case-specific functionalities, and they are agnostic of other plugins and the system behavior.
The Core System is responsible for defining the contract used by itself and the Plugins to communicate.

Plugins aren't necessarily designed for a particular Core System, but in those cases, an adapter is required to make the Plugins follow the contract.
The main principles related to this kind of Architecture are the Inversion of Control (IoC) Principle and the Dependency Inversion Principle (DIP, the D from the SOLID principles)
While the Plugins follow the IoC by extracting behavior and control from the main flow or Core System, the DIP is necessary for avoiding coupling and establishing the contract.
Dependency Injection is not the only design pattern that allows building a Plugin Architecture or follow the IoC Principle; callbacks, schedulers, event loops, and message queues are also valid options.
If you are interested in learning more about Plugin Architecture, check the following links
Plugin-based Angular Libraries
The Angular community is big and healthy, every day, new packages get published, and our favorite tools get renewed.
In this constellation, not all libraries are built using a Plugin Architecture, and with a good reason. This pattern is NOT a silver bullet, and you should not try to design all your libraries using Plugins.
But there are some scenarios where the Plugin Architecture provides outstanding flexibility and relief maintainers from creating all possible features for a given domain. For example, in Components libraries, using content projection is a great way to achieve IoC. From there, it is pretty easy to build plugins that extend your core Component functionality or customize the UI.
In this article, we will focus on another of the design patterns implemented in Angular, the Dependency Injection (DI) pattern.
Implementing a Plugin Architecture with Dependency Injection
As described previously, the Plugin Architecture has two components. The Core System and the Plugins.
The Plugins depend on the Core System, but not the other way around. Therefore, we should start designing the Core System first.
The minimum elements we are going to need are
- PluginContract, this is the contract that our Plugins will implement and that the Core System uses for communication.
- PluginInjectionToken, in some technologies, the
- PluginContract would be used as the injection token. Still, since interfaces are not genuine artifacts in typescript and they disappear at build time, we have to define an additional token. It is good to notice that this splitting also contributes to the separation of concerns.
- OrchestrationService will gather all the plugins, orchestrate their behavior, and provide error resolution.
We will also have some configuration elements, optional for small and straightforward systems but instrumental in building flexible libraries.
- PluginConfiguration contains information about the integration of the Plugin with the Core system. The OrchestrationService uses it to identify if it should execute a Plugin and how. The Plugin can extend it to configure internal Plugin behavior. The core system can provide a default configuration for the Plugins.
- PluginConfigurationToken, injection token for the PluginConfiguration
- CoreConfiguration provides configuration at a Core level, makes the overall system execute in a certain way.
- CoreConfigurationToken, injection token for the CoreConfiguration
The dependency flow would look like Fig.2.
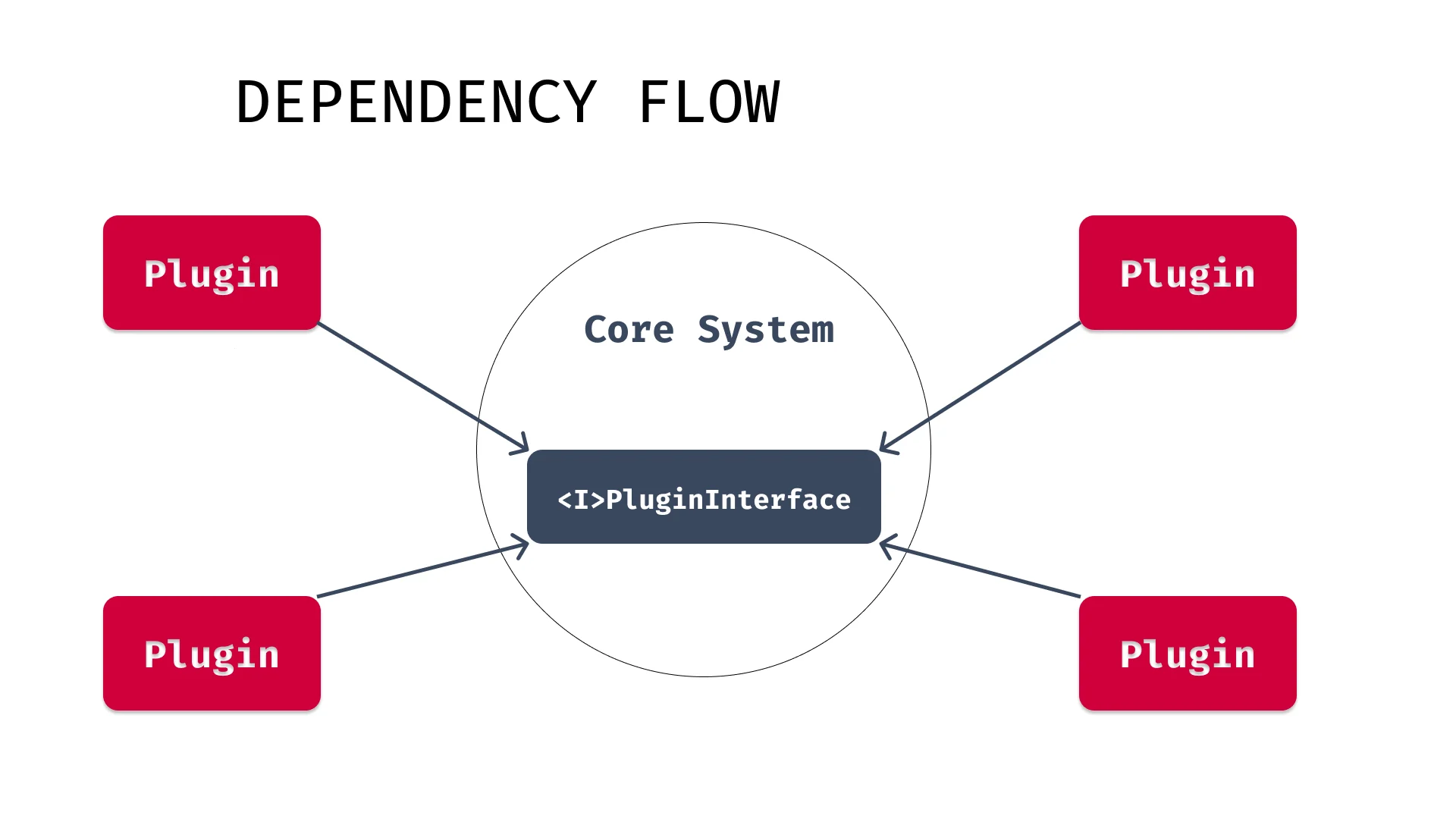
The Angular code
Now that we have a big picture of our architectural design let's jump into the details and learn how to implement our library following this pattern.
The core system
The first thing we need is the contract that our plugins need to implement to communicate with the core system.
import { PluginConfig } from './plugin.config';
export interface SystemPlugin {
config: PluginConfig; // 👈
operationA(...args: unknown[]): unknown;
operationB(...args: unknown[]): unknown;
operationZ(...args: unknown[]): unknown;
}
This contract could have any signature; it is up to the library that you are building. The only remarkable element is the config. We are forcing the Plugin to have it since the Core System needs it to handle the Plugin correctly.
The config itself is very basic and generic for our demonstrational purpose. Still, the idea is to define in the PluginConfig everything that we want to make adjustable in our Plugin behavior. This config can serve both the Plugin and the Core System.
export interface PluginConfig {
optionA: unknown;
optionB: unknown;
optionZ: unknown;
}
Of course, we need some injectors here since we cannot use the interfaces with Angular Dependency Injection. Let's add those.
import { InjectionToken } from '@angular/core';
import { SystemPlugin } from './plugin';
export const pluginToken: InjectionToken<SystemPlugin> = new InjectionToken(
'__PLUGIN_TOKEN__'
);
and
import { InjectionToken } from '@angular/core';
import { PluginConfig } from './plugin.config';
export const pluginConfigToken: InjectionToken<PluginConfig> = new InjectionToken(
'__PLUGIN_CONFIG_TOKEN__'
);
The next thing we are going to implement is our Core System configuration.
export interface CoreConfig {
coreOptionsA: unknown;
coreOptionsB: unknown;
coreOptionsZ: unknown;
}
The CoreConfig, like all other elements of this example, should be implemented accordingly with your library. For simplicity, let's imagine it represents all the different configurable tweaks we can make to our Core System. Occasionally, part of the configuration options of the CoreConfig are used as global defaults for not required configuration options in the PluginConfig.
As before, we will also create the coreConfigToken to inject the CoreConfig.
import { InjectionToken } from '@angular/core';
import { CoreConfig } from './core.config';
export const coreConfigToken: InjectionToken<CoreConfig> = new InjectionToken(
'__CORE_CONFIG_TOKEN__'
);
Next, let's take a look at our OrchestratorService, the heart of our library. In our example, the OrchestratorService will also be the entry point to our library, but this is not required. The library entry points can vary from a directive to a secondary service that uses the orchestrator service to any other communication form between the client code and our library.
import { Inject, Injectable, Optional } from '@angular/core';
import { coreConfigToken } from './core-config.token';
import { CoreConfig } from './core.config';
import { SystemPlugin } from './plugin';
import { pluginToken } from './plugin.token';
@Injectable({ providedIn: 'root' })
export class OrchestratorService {
private readonly plugins: SystemPlugin[];
constructor(
@Optional()
@Inject(pluginToken)
plugins: SystemPlugin[],
@Inject(coreConfigToken) private config: CoreConfig
) {
plugins = plugins || [];
this.plugins = Array.isArray(plugins) ? plugins : [plugins];
}
coreOperationA(...args: any[]): unknown {
// just a demonstration of what can be done
return this.plugins
.filter((plugin) => this.canPluginExecute(plugin))
.reduce<unknown>((acc, plugin) => plugin.operationA(acc), null);
}
private canPluginExecute(plugin: SystemPlugin): boolean {
// implement any validation to determine whether the plugin should be executed or not
// use the core config and/or the driver config
// just a demonstration of what can be done
return (
(this.config.coreOptionsA as boolean) &&
(plugin.config.optionA as boolean)
);
}
}
Wow, a lot is going on in there. Since this service is larger than the other files, let's split it to understand what is going on.
constructor(
@Optional()
@Inject(pluginToken)
plugins: SystemPlugin[],
@Inject(coreConfigToken) private config: CoreConfig
) {
plugins = plugins || [];
this.plugins = Array.isArray(plugins) ? plugins : [plugins];
}
The first thing we need to do is inject what we are going to need.
The key elements are the Plugins, and I want to emphasize the plural, Plugins. We are receiving an Array of Plugins. However, it is possible that we only received a single Plugin or none plugin at all. In such cases, we need to transform the data to a suitable form, to an Array.
But, how is it possible to receive multiple instances of the same Injection token? That's one of the critical ingredients when using Angular's Dependency Injection as the Plugin Architecture mechanism. We will go over this feature when we provide our Plugins, but the key is in the multi options of Angular's StaticProvider.
coreOperationA(...args: any[]): unknown {
// just a demonstration of what can be done
return this.plugins
.filter((plugin) => this.canPluginExecute(plugin))
.reduce<unknown>((acc, plugin) => plugin.operationA(acc), null);
}
The coreOperationA is an example of how the client code could use our library and how the OrchestratorService handles our plugins.
The example implementation shows how we can filter which plugins are configured to execute at a given moment and how to compose the different plugins to build a response. Real-world implementations could differ significantly, but the point is that we can access all the configured plugins and make decisions about them in our orchestrator.
Finally, we use our canPluginExecute method to determine if a Plugin should be used or not based on both the CoreConfig and the PluginConfig.
private canPluginExecute(plugin: SystemPlugin): boolean {
// implement any validation to determine whether the plugin should be executed or not
// use the core config and/or the driver config
// just a demonstration of what can be done
return (
(this.config.coreOptionsA as boolean) &&
(plugin.config.optionA as boolean)
);
}
And that's it. That is our Core System, well almost, we still need a module to configure everything. Let's see how we can do that.
import { ModuleWithProviders, NgModule } from '@angular/core';
import { CoreConfig } from './core.config';
import { coreConfigToken } from './core-config.token';
@NgModule()
export class CoreSystemModule {
static forRoot(config: CoreConfig): ModuleWithProviders<CoreSystemModule> {
return {
ngModule: CoreSystemModule,
providers: [{ provide: coreConfigToken, useValue: config }],
};
}
}
We are using the static method forRoot to received the CoreConfig configuration from the client code and then provided it to the DI system. Otherwise, we might not need to have a module, but this is a well-known pattern.
The Plugins
The Core System exports everything we need, and possibly it could execute independently, but a Plugin Architecture makes little sense without plugins.
Let's start by implementing our SystemPlugin contract; that's where our unique Plugin logic will leave after all.
import { Inject, Injectable } from '@angular/core';
import {
PluginConfig,
pluginConfigToken,
SystemPlugin,
} from 'projects/core-system/src/public-api';
@Injectable()
export class ExamplePlugin implements SystemPlugin {
constructor(@Inject(pluginConfigToken) readonly config: PluginConfig) {}
operationA(...args: unknown[]): unknown {
throw new Error('Method not implemented.');
}
operationB(...args: unknown[]): unknown {
throw new Error('Method not implemented.');
}
operationZ(...args: unknown[]): unknown {
throw new Error('Method not implemented.');
}
}
We need to inject our PluginConfig and implement the interface; the particular implementation is unique to every Plugin. This example shows non-implemented methods, but the idea is there.
The final piece and essential part is the Plugin configuration.
import { ModuleWithProviders, NgModule } from '@angular/core';
import {
PluginConfig,
pluginConfigToken,
pluginToken,
} from 'projects/core-system/src/public-api';
import { ExamplePlugin } from './example.plugin';
export function examplePluginFactory(config: PluginConfig): ExamplePlugin {
return new ExamplePlugin(config);
}
@NgModule()
export class ExamplePluginModule {
static forRoot(
config: PluginConfig
): ModuleWithProviders<ExamplePluginModule> {
return {
ngModule: ExamplePluginModule,
providers: [
{ provide: pluginConfigToken, useValue: config },
{
provide: pluginToken,
useFactory: examplePluginFactory,
deps: [pluginConfigToken],
multi: true,
},
],
};
}
}
Firstly, we are receiving the PluginConfig from the client code and providing it to the Dependency Injection system. Then it is time to provide our Plugin.
Since our Plugin depends on the provided PluginConfig we need to use a factory function combined with the deps property.
The critical part is the multi options. If missed, that single configuration can make the whole system fail because it can overwrite all other plugins and only provide the one without multi. When set to true, it enables the power of importing multiple artifacts using a single injection token, in this case, our Plugins.
And that's all we need! Now we can start using our Plugin-based library.
Usage
Like with any other Angular library, we have to import it and configure its module.
import { NgModule } from '@angular/core';
import { BrowserModule } from '@angular/platform-browser';
import { CoreSystemModule } from 'projects/core-system/src/public-api';
import { AppComponent } from './app.component';
@NgModule({
declarations: [AppComponent],
imports: [
BrowserModule,
CoreSystemModule.forRoot({
coreOptionsA: '_A_',
coreOptionsB: '_B_',
coreOptionsZ: '_Z_',
}),
],
bootstrap: [AppComponent],
})
export class AppModule {}
Now we can start using our OrchestratorService or any other communication form we have in place in our library.
However, we will not go far if we don't have any Plugins; let's add the one we already implemented.
import { NgModule } from '@angular/core';
import { BrowserModule } from '@angular/platform-browser';
import { CoreSystemModule } from 'projects/core-system/src/public-api';
import { ExamplePluginModule } from 'projects/example-plugin/src/public-api';
import { AppComponent } from './app.component';
@NgModule({
declarations: [AppComponent],
imports: [
BrowserModule,
CoreSystemModule.forRoot({
coreOptionsA: '_A_',
coreOptionsB: '_B_',
coreOptionsZ: '_Z_',
}),
ExamplePluginModule.forRoot({
optionA: '-A-',
optionB: '-B-',
optionZ: '-Z-',
}),
],
bootstrap: [AppComponent],
})
export class AppModule {}
And as simple as that, without letting the CoreSystemModule know anything about our Plugin, we have our system configured.
I hope you can appreciate the simplicity of the configuration of our Plugin Architecture. Exactly as we imported our ExamplePluginModule, we can import as many Plugins as we want, following the same structure. The Core System will access all the imported Plugins and manage its usage for us.
Now we are set up, let's start using our library.
import { Component } from '@angular/core';
import { OrchestratorService } from 'projects/core-system/src/public-api';
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.scss'],
})
export class AppComponent {
title = 'plugins-architecture-demo';
constructor(private orchestrator: OrchestratorService) {
this.orchestrator.coreOperationA();
}
}
The client application or library now only has to inject our library entry point. In our example, it is the OrchestrationService. Then, it can start interacting with the library. Plugins are only a concern of the library. The client code is agnostic to the Plugins' existence except for the configuration part.
Conclusion
The Plugin Architecture pattern is a great pattern to create extensible systems using the Inversion of Control Principle and lifting the focused functionalities of our system to the Plugins.
We have learned how to implement a custom Angular library following a Plugin Architecture using Angular Dependency Injection, while briefly introducing the Angular Dependency Injection elements that allow us to make our Plugins decoupled from our Core System.
You can find the final solution at this repo
And if you want to see a real-world usage of this pattern you can visit Lumberjack




