In real-world software development, design patterns offer reusable solutions and, most prominently, make code easier to maintain.
The Event Bus idea is generally associated with the Publish-subscribe pattern:
Publish–subscribe is a messaging pattern through which message senders, called "publishers", do not program the messages to be sent directly to specific receivers, called "subscribers". Instead, they classify published messages without knowledge of which subscribers sent them.
In other words, an Event Bus can be considered as a global way to transport messages or events to make them accessible from any place within the application.
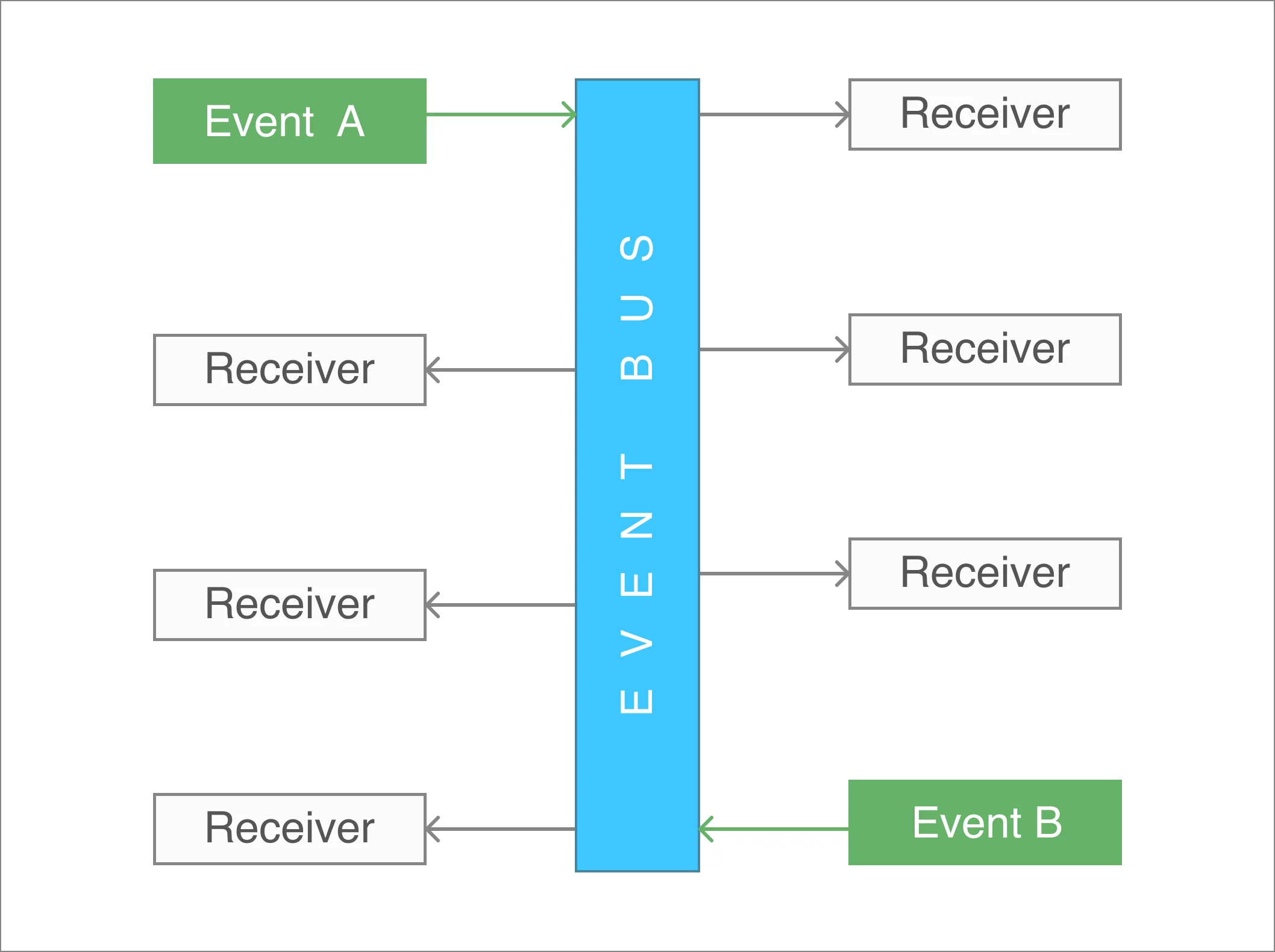
In this blog post, we'll use TypeScript to implement a general-purpose Event Bus for JavaScript applications.
Inspiration
The concept of an Event Bus comes from the Bus Topology or Bus Network, in which nodes are directly connected to a common half-duplex link called a "bus". Every station will receive all network traffic as seen in the image below.
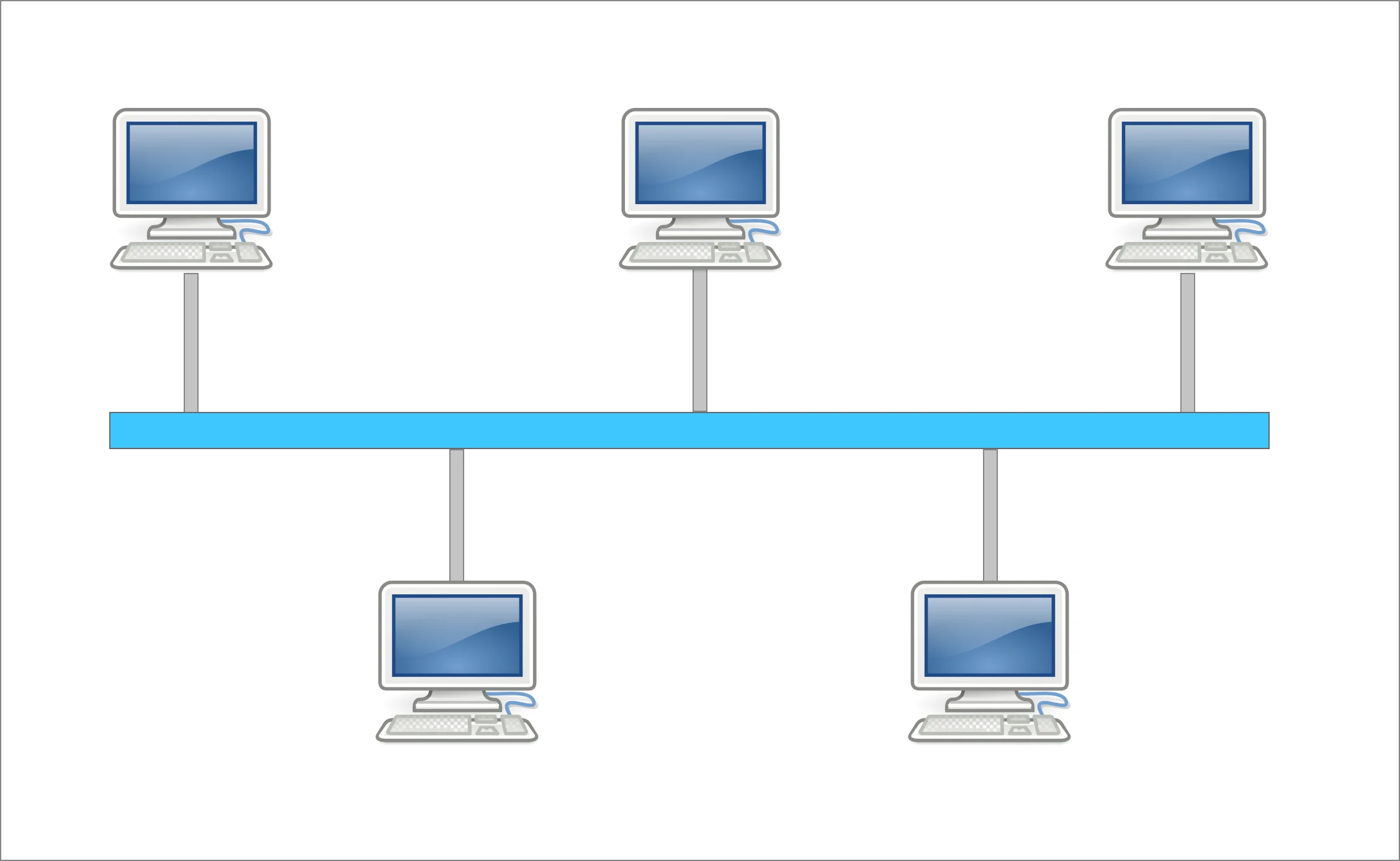
In a software context, you can assume an object instead of a computer. Then, a message can be triggered from any object through the Bus, and it can be sent using an event, even including some data.
Let's move forward with a TypeScript implementation of this pattern.
Project Setup
Prerequisites
You'll need to have installed the following tools in your local environment:
- Node.js. Preferably the latest LTS version.
- A package manager. You can use either NPM or Yarn. This tutorial will use NPM.
Initialize the Project
Let's create the project from scratch. First, create a new folder using event-bus-typescript as the name:
mkdir event-bus-typescript
Next, let's initialize the project using NPM, and basic TypeScript configurations:
npm init -y
tsc --init
Update the scripts section from the package.json file:
{
"scripts": {
"start": "tsc && node dist/main.js"
},
}
Proceed to update the tsconfig.json file with the configurations listed below.
{
"compilerOptions": {
"target": "esnext",
"module": "commonjs",
"outDir": "./dist",
"strict": true,
"esModuleInterop": true,
"forceConsistentCasingInFileNames": true
}
}
Finally, create the src folder to contain the source code files.
Project Structure
The previous project already contains the main configurations ready to go with TypeScript. Open it in your favorite code editor, and make sure to have the following project structure:
|- event-bus-typescript
|- src/
|- package.json
|- tsconfig.json
Event Bus Implementation
For the Event Bus implementation, let's create a src/event-bus/event-bus.ts file.
Creating the Model
To ensure robust typing within the TypeScript context, let's make sure to define a couple of Interfaces for the data model.
// event-bus.ts
export interface Registry {
unregister: () => void;
}
export interface Callable {
[key: string]: Function;
}
export interface Subscriber {
[key: string]: Callable;
}
export interface IEventBus {
dispatch<T>(event: string, arg?: T): void;
register(event: string, callback: Function): Registry;
}
Pay attention to the IEventBus interface, which represents a contract for the future Event Bus class implementation.
// event-bus.ts
export class EventBus implements IEventBus {
private subscribers: Subscriber;
private static nextId = 0;
constructor() {
this.subscribers = {};
}
public dispatch<T>(event: string, arg?: T): void {
const subscriber = this.subscribers[event];
if (subscriber === undefined) {
return;
}
Object.keys(subscriber).forEach((key) => subscriber[key](arg));
}
public register(event: string, callback: Function): Registry {
const id = this.getNextId();
if (!this.subscribers[event]) this.subscribers[event] = {};
this.subscribers[event][id] = callback;
return {
unregister: () => {
delete this.subscribers[event][id];
if (Object.keys(this.subscribers[event]).length === 0)
delete this.subscribers[event];
},
};
}
private getNextId(): number {
return EventBus.nextId++;
}
}
Pay attention to the public methods:
- The
dispatchfunction makes use of the TypeScript generics to enable capturing the right type of parameters at the moment the method gets called. An example of its use will be provided at the end of this article. - The
registerfunction receives an event name and a callback function to be invoked. In the end, it returns aRegistryobject to enable a way of unregistering the same event.
The Singleton Pattern
Since the Event Bus can be accessed from any place in the application, it's important to have a unique instance. Then, you can implement the Singleton Pattern in the existing class as follows.
export class EventBus {
private static instance?: EventBus = undefined;
private constructor() {
// initialize attributes here.
}
public static getInstance(): EventBus {
if (this.instance === undefined) {
this.instance = new EventBus();
}
return this.instance;
}
}
Here are the main points of this Singleton class:
- A static instance is defined to have the unique reference of an object of this class.
- The constructor method is private, since creating an object from any place is not allowed.
- The
getInstance()method makes sure to instantiate an object of this class only once.
Using the Event Bus
In order to explain the use of the brand-new Event Bus, we'll need to create a src/main.ts file.
import { EventBus } from './event-bus/event-bus';
EventBus.getInstance().register('hello-world', (name: string) => {
if(name)
console.log('Hello ' + name);
else
console.log('Hello world');
});
EventBus.getInstance().dispatch<string>('hello-world', 'Luis');
EventBus.getInstance().dispatch<string>('hello-world');
EventBus.getInstance().dispatch<string>('hello-world');
Once you run npm run start command, you should see the following output:
Hello Luis
Hello world
Hello world
However, we can have full control of the initial subscription too:
const registry = EventBus.getInstance().register('hello-world', (name: string) => {
if(name)
console.log('Hello ' + name);
else
console.log('Hello world');
});
EventBus.getInstance().dispatch<string>('hello-world', 'Luis');
EventBus.getInstance().dispatch<string>('hello-world');
registry.unregister();
EventBus.getInstance().dispatch<string>('hello-world');
Let's explain what's happening now:
- The first line performs a call to the register method from the Event Bus instance.
- Then, a reference of the
Registryobject is available through theregistryvariable. - Later, it's possible to perform the
registry.unregister()call to avoid dispatching the last "hello world" call.
Here's the output result of those operations:
Hello Luis
Hello world
Live Demo
Wanna play around with this code? Just open the embedded Stackblitz editor:
Source Code of the Project
Find the complete project in this GitHub repository: event-bus-typescript. Do not forget to give it a star ⭐️ and play around with the code.
Feel free to reach out on Twitter if you have any questions. Follow me on GitHub to see more about my work. Be ready for more articles about Lit in this blog.




