
How to configure and optimize a new Serverless Framework project with TypeScript If you’re trying to ship some serverless functions to the cloud quickly, Serverless Framework is a great way to deploy to AWS Lambda quickly. It allows you to deploy APIs, schedule tasks, build workflows, and process cloud events through a code configuration. Serverless Framework supports all the same language runtimes as Lambda, so you can use JavaScript, Ruby, Python, PHP, PowerShell, C#, and Go. When writing JavaScript though, TypeScript has emerged as a popular choice as it is a superset of the language and provides static typing, which many developers have found invaluable. In this post, we will set up a new Serverless Framework project that uses TypeScript and some of the optimizations I recommend for collaborating with teams. These will be my preferences, but I’ll mention other great alternatives that exist as well.
Starting a New Project
The first thing we’ll want to ensure is that we have the serverless framework installed locally so we can utilize its commands. You can install this using npm:
npm install -g serverless
From here, we can initialize the project our project by running the serverless command to run the CLI. You should see a prompt like the following:

We’ll just use the Node.js - Starter for this demo since we’ll be doing a lot of our customization, but you should check out the other options. At this point, give your project a name. If you use the Serverless Dashboard, select the org you want to use or skip it. For this, we’ll skip this step as we won’t be using the dashboard. We’ll also skip deployment, but you can run this step using your default AWS profile.
You’ll now have an initialized project with 4 files:
.gitignore
index.js - this holds our handler that is configured in the configuration
README.md - this has some useful framework commands that you may find useful
serverless.yml - this is the main configuration file for defining your serverless infrastructure
We’ll cover these in more depth in a minute, but this setup lacks many things. First, I can’t write TypeScript files. I also don’t have a way to run and test things locally. Let’s solve these.
Enabling TypeScript and Local Dev
Serverless Framework’s most significant feature is its rich plugin library. There are 2 packages I install on any project I’m working on:
Serverless Offline emulates AWS features so you can test your API functions locally. There aren’t any alternatives to this for Serverless Framework, and it doesn’t handle everything AWS can do. For instance, authorizer functions don’t work locally, so offline development may not be on the table for you if this is a must-have feature. There are some other limitations, and I’d consult their issues and READMEs for a thorough understanding, but I’ve found this to be excellent for 99% of projects I’ve done with the framework.
Serverless Esbuild allows you to use TypeScript and gives you extremely fast bundler and minifier capabilities. There are a few alternatives for TypeScript, but I don’t like them for a few reasons. First is Serverless Bundle, which will give you a fully configured webpack-based project with other features like linters, loaders, and other features pre-configured. I’ve had to escape their default settings on several occasions and found the plugin not to be as flexible as I wanted. If you need that advanced configuration but want to stay on webpack, Serverless Webpack allows you to take all of what Bundle does and extend it with your customizations. If I’m getting to this level, though, I just want a zero-configuration option which esbuild can be, so I opt for it instead. Its performance is also incredible when it comes to bundle times. If you want just TypeScript, though, many people use serverless-plugin-typescript, but it doesn’t support all TypeScript features out of the box and can be hard to configure.
To configure my preferred setup, do the following:
- Install the plugins by setting up your package.json. I’m using
yarnbut you can use your preferred package manager.
yarn add --dev serverless serverless-esbuild esbuild serverless-offline
Note: I’m also installing serverless here, so I have a local copy that can be used in package.json scripts. I strongly recommend doing this.
- In our serverless.yml, let’s install the plugins and configure them. When done, our configuration should look like this:
service: serverless-setup-demo
frameworkVersion: "3"
plugins:
- serverless-esbuild
- serverless-offline
custom:
esbuild:
bundle: true
minify: false
provider:
name: aws
runtime: nodejs18.x
functions:
function1:
handler: index.handler
- Now, in our newly created
package.json, let’s add a script to run the local dev server. Our package.json should now look like this:
{
"scripts": {
"dev": "sls offline start"
},
"devDependencies": {
"esbuild": "^0.19.8",
"serverless": "^3.38.0",
"serverless-esbuild": "^1.49.0",
"serverless-offline": "^13.3.0"
}
}
We can now run yarn dev in our project root and get a running server 🎉
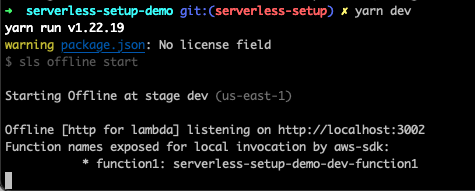
But our handler is still in JavaScript. We’ll want to pull in some types and set our tsconfig.json to fix this. For the types, I use aws-lambda and @types/serverless, which can be installed as dev dependencies. For reference, my tsconfig.json looks like this:
{
"compileOnSave": false,
"compilerOptions": {
"rootDir": ".",
"sourceMap": true,
"declaration": false,
"moduleResolution": "NodeNext",
"emitDecoratorMetadata": true,
"experimentalDecorators": true,
"importHelpers": false,
"target": "ES2018",
"module": "NodeNext",
"skipLibCheck": true,
"skipDefaultLibCheck": true,
"baseUrl": "."
},
"exclude": ["node_modules", "tmp"]
}
And I’ve updated our index.js to index.ts and updated it to read as follows:
import type { APIGatewayProxyHandler } from "aws-lambda";
export const handler: APIGatewayProxyHandler = async (event) => {
return {
statusCode: 200,
body: JSON.stringify(
{
message: "Go Serverless v3.0! Your function executed successfully!",
input: event,
},
null,
2
),
};
};
With this, we now have TypeScript running and can do local development. Our function doesn’t expose an HTTP route making it harder to test so let’s expose it quickly with some configuration:
functions:
function1:
handler: index.handler
events:
- httpApi:
path: "/healthcheck"
method: "get"
So now we can point our browser to http://localhost:3000/healthcheck and see an output showing our endpoint working!
Making the Configuration DX Better
ion DX Better Many developers don’t love YAML because of its strict whitespace rules. Serverless Framework supports JavaScript or JSON configurations out of the box, but we want to know if our configuration is valid as we’re writing it. Luckily, we can now use TypeScript to generate a type-safe configuration file! We’ll need to add 2 more packages to make this work to our dev dependencies:
yarn add -D typescript ts-node
Now, we can change our serverless.yml to serverless.ts and rewrite it with type safety!
import type { Serverless } from "serverless/aws";
const serverlessConfiguration: Serverless = {
service: "serverless-setup-demo",
frameworkVersion: "3",
plugins: ["serverless-esbuild", "serverless-offline"],
custom: {
esbuild: {
bundle: true,
minify: false,
},
},
provider: {
name: "aws",
runtime: "nodejs18.x",
},
functions: {
healthcheck: {
handler: "index.handler",
events: [
{
httpApi: {
path: "/healthcheck",
method: "get",
},
},
],
},
},
};
module.exports = serverlessConfiguration;
Note that we can’t use the export keyword for our configuration and need to use module.exports instead.
Further Optimization
There are a few more settings I like to enable in serverless projects that I want to share with you.
AWS Profile
In the provider section of our configuration, we can set a profile field. This will relate to the AWS configured profile we want to use for this project. I recommend this path if you’re working on multiple projects to avoid deploying to the wrong AWS target. You can run aws configure –profile <PROFILE_NAME> to set this up. The profile name specified should match what you put in your Serverless Configuration.
Individual Packaging
Cold starts are a big problem in serverless computing. We need to optimize to make them as small as possible and one of the best ways is to make our lambda functions as small as possible. By default, serverless framework bundles all functions configured into a single executable that gets uploaded to lambda, but you can actually change that setting by specifying you want each function bundled individually. This is a top-level setting in your serverless configuration and will help reduce your function bundle sizes leading to better performance on cold starts.
package: {
individually: true,
},
Memory & Timeout
Lambda charges you based on an intersection of memory usage and function runtime. They have some limits to what you can set these values to but out of the box, the values are 128MB of memory and 3s for timeout. Depending on what you’re doing, you’ll want to adjust these settings. API Gateway has a timeout window of 30s so you won’t be able to exceed that timeout window for HTTP events, but other Lambdas have a 15-minute timeout window on AWS. For memory, you’ll be able to go all the way to 10GB for your functions as needed. I tend to default to 512MB of memory and a 10s timeout window but make sure you base your values on real-world runtime values from your monitoring.
Monitoring
Speaking of monitoring, by default, your logs will go to Cloudwatch but AWS X-Ray is off by default. You can enable this using the tracing configuration and setting the services you want to trace to true for quick debugging.
You can see all these settings in my serverless configuration in the code published to our demo repo: https://github.com/thisdot/blog-demos/tree/main/serverless-setup-demo
Other Notes
Two other important serverless features I want to share aren’t as common in small apps, but if you’re trying to build larger applications, this is important. First is the useDotenv feature which I talk more about in this blog post. Many people still use the serverless-dotenv-plugin which is no longer needed for newer projects with basic needs. The second is if you’re using multiple cloud services. By default, your lambdas may not have permission to access the other resources it needs. You can read more about this in the official serverless documentation about IAM permissions.
Conclusion
If you’re interested in a new serverless project, these settings should help you get up and running quickly to make your project a great developer experience for you and those working with you. If you want to avoid doing these steps yourself, check out our starter.dev serverless kit to help you get started.
About the author




