In Part One, you were introduced to GraphQL and shown how to build a GraphQL Server API based on Node.js and GraphQL.js.
In this installment, we will continue from where we left off in Part One and move on to building the GraphQL Angular Client app.
Apollo Client- what is it?
Apollo GraphQL provides the tools and APIs to add a GraphQL Server API to your application. It also offers a collection of Apollo Client libraries that you can use from within your client apps to connect to the GraphQL Server API. GraphQL Client APIs are available for Angular, React, Vue.js, and others. For this article, we are going to use Apollo Angular Client to connect our Angular app to the GraphQL Server API we built. You may browse the Apollo GraphQL Server and Clients to gain an in-depth knowledge of Apollo products.
Build the Angular Client App
The Angular client app we are building in this article uses the Apollo Angular client to connect to our GraphQL Server API.
This is the final result once you finish building this app:
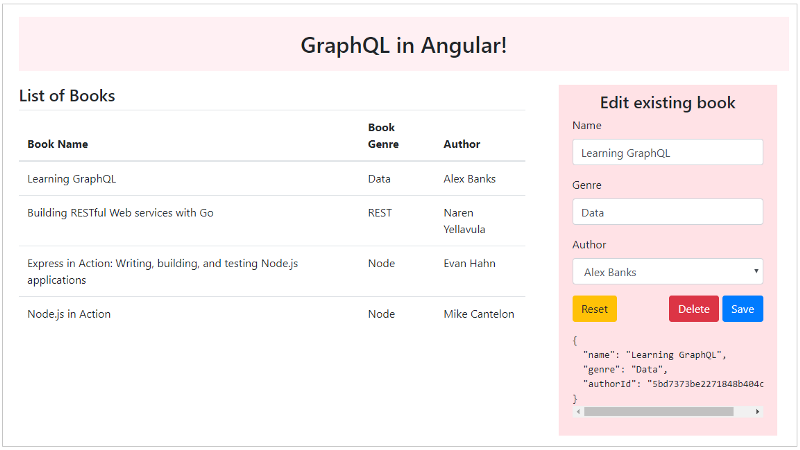
There’s a simple Grid listing the books and a form on the right side to add/delete/edit a book.
Create the app & add necessary NPM packages
To start, let’s create a new Angular app using the Angular CLI.
Then, let’s add some NPM packages to be able to use the Apollo Angular client in our app.
npm install apollo-angular apollo-angular-link-http apollo-cache-inmemory apollo-client --save
In addition, we need to install some GraphQL packages to allow the client app to understand things like GraphQL queries and mutations:
npm install graphql graphql-tag
Define the data structure received from the server
In the src/app folder, let’s add a Typescript file named types.ts. This file will define the object types that we are going to use in the GraphQL queries and mutations.
export type Book = {
id: string;
name: string;
genre: string;
author: Author;
}
export type Author = {
id: string;
name: string;
age: number;
books: Book[];
}
export type BooksQuery = {
books: Book[];
}
export type AuthorsQuery = {
authors: Author[];
}
Define the GraphQL queries
The second Typescript file to add is the queries.ts file. This file includes all the queries and mutations we are going to use throughout this app. For now, let’s have a look at the query we will use in order to get a list of all the books available from the GraphQL Server API.
import gql from 'graphql-tag';
export const getBooksQuery = gql`
{
books {
id
name
genre
author {
id
name
age
books {
id
name
}
}
}
}`;
The gql() function is imported from the graphql-tag package. We’ve already seen the syntax of writing GraphQL queries. No difference here. The query requests all books with fields to retrieve as id, name, genre, and author. For the author field, the query requests to retrieve the id, name, age, and list of books written by that author. For the list of books, only the id and name fields are needed for this query. A composition of queries within a single GraphQL query!
Add the BookList Component
Let’s add the BookList Angular Component.
<div class="books">
<div class="row">
<div class="col">
<h2 class="h2 list">List of Books</h2>
<table class="table table-hover">
<thead>
<tr>
<th>Book Name</th>
<th>Book Genre</th>
<th>Author</th>
</tr>
</thead>
<tbody>
<tr *ngFor="let book of books" (click)="selectBook(book)">
<td>{{ book.name }}</td>
<td>{{ book.genre }}</td>
<td>{{ book.author.name }}</td>
</tr>
</table>
</div>
</div>
</div>
The HTML markup above expects a variable called books to be defined on the BookList component class.
The BookList component class defines the following:
private querySubscription: Subscription;
books: Book[];
The querySubscription variable holds the actual RxJS Subscription to the GraphQL Server API, as you will see shortly.
The books variables holds all the book records retrieved from the server.
@Output()
bookSelected = new EventEmitter<Book>();
The bookSelected event will be triggered by the component upon selection of a book.
import { Apollo } from ‘apollo-angular’;
constructor(private apollo: Apollo) { }
The Apollo Client, a service in the Angular terminology, is injected into the constructor of the component and will be used later to send the query to the GraphQL server.
Next, the code hooks into the OnInit lifecycle hook of the component to issue a request to the GraphQL Server and subscribe to the Observable returned by Apollo Client, in order to process the results once they are ready.
ngOnInit() {
this.querySubscription = this.apollo.watchQuery<BooksQuery>({
query: getBooksQuery
})
.valueChanges
.subscribe(({ data }) => {
this.books = data.books;
});
}
The Apollo Client makes available the watchQuery() function to issue a query request. This function expects an input object with a minimum of query property defined. The query property, in this case, holds the query name.
Through the valueChanges Observable property returned by the watchQuery() function, you can subscribe to 1) issue the request, and 2) to be given the chance to review the results of the query.
The watchQuery() function is smart enough to reissue a new request whenever it detects that the list of books, cached locally by Apollo Client, might have been changed somehow.
The watchQuery() function is generic and expects a type declaration to guide it internally on how to process the results from the server. The code passes the type BooksQuery, which was defined in the types.ts class as follows:
export type BooksQuery = {
books: Book[];
}
The response is expected to have a property named books,an array of Book type.
The component local variable books is then populated in the body of the subscribe() function as follows:
.subscribe(({ data }) => {
this.books = data.books;
});
Remember it’s important to unsubscribe from the active subscription inside the OnDestroy lifecycle hook:
ngOnDestroy() {
this.querySubscription.unsubscribe();
}
The BookList component handles the selection of a single book and notifies other components in the app by emitting an event.
/// HTML ///
<tr *ngFor="let book of books" (click)="selectBook(book)">
/// Typyescript ///
selectBook(book: Book): void {
this.bookSelected.emit(book);
}
Adding the BookList component into the App component
The BookList component is then embedded inside the App component as follows:
<app-book-list (bookSelected)="book = $event"></app-book-list>
Notice how the App component is listening to an event called bookSelected that is fired by the BookList component once the user selects a single book? The event handler saves the selected book inside a local variable called book.
Add the BookCreatEdit component
This component is used to create a new book and edit or delete an existing book in the app. It displays an HTML Form to allow managing a book.
<div class="book-edit">
<div class="row">
<div class="col">
<h2 class="h2">{{ title }}</h2>
<form name="form" (ngSubmit)="f.form.valid && onSave()" #f="ngForm" novalidate>
<div class="form-group">
<label for="name">Name</label>
<input required type="text" name="name" class="form-control"
[(ngModel)]="model.name" #name="ngModel" [ngClass]="{ 'is-invalid': f.submitted && genre.invalid }">
<div *ngIf="f.submitted && name.invalid" class="invalid-feedback">
<div *ngIf="name.errors.required">Book Name is required</div>
</div>
</div>
<div class="form-group">
<label for="genre">Genre</label>
<input required type="text" name="genre" class="form-control"
[(ngModel)]="model.genre" #genre="ngModel" [ngClass]="{ 'is-invalid': f.submitted && genre.invalid }">
<div *ngIf="f.submitted && genre.invalid" class="invalid-feedback">
<div *ngIf="genre.errors.required">Book Genre is required</div>
</div>
</div>
<div class="form-group">
<label for="author">Author</label>
<select required class="form-control" name="authorId"
[(ngModel)]="model.authorId" #authorId="ngModel" [ngClass]="{ 'is-invalid': f.submitted && authorId.invalid }">
<option value="">Please select an Author</option>
<option *ngFor="let author of authors" [value]="author.id">
{{ author.name }}
</option>
</select>
<div *ngIf="f.submitted && authorId.invalid" class="invalid-feedback">
<div *ngIf="authorId.errors.required">Author is required</div>
</div>
</div>
<div class="form-group">
<div class="controls">
<div class="reset">
<button class="btn btn-warning" type="reset">Reset</button>
</div>
<div class="manage">
<button class="btn btn-danger" [disabled]="!enableDelete()" (click)="delete()">Delete</button>
<button type="submit" class="btn btn-primary">Save</button>
</div>
</div>
</div>
</form>
<pre>{{f.value | json}}</pre>
</div>
</div>
</div>
The form has input fields for the Name, Genre, and Author fields. Also, three buttons are placed at the bottom of the form to Reset the form, Delete a book, and Edit/Create a book.
When the component loads, it issues a request to the GraphQL Server API to retrieve a list of authors and bind them to the dropdown field on the form.
ngOnInit(): void {
this.querySubscription = this.apollo.watchQuery<AuthorsQuery>({
query: getAuthorsQuery
})
.valueChanges
.subscribe(({ data }) => {
this.authors = data.authors;
});
}
When creating or editing a book, the onSave() function is triggered:
onSave(): void {
let variables = {};
let mutation = {};
let msg = "";
if (this.model.id) {
// update
variables = {
id: this.model.id,
name: this.model.name,
genre: this.model.genre,
authorId: this.model.authorId
};
mutation = updateBookMutation;
msg = "Book updated";
} else {
// create
variables = {
name: this.model.name,
genre: this.model.genre,
authorId: this.model.authorId
};
mutation = addBookMutation;
msg = "Book Added";
}
this.apollo.mutate({
mutation: mutation,
variables:variables,
refetchQueries: [{
query: getBooksQuery
}]
}).pipe(
map ( results => mutation === updateBookMutation ? results.data['updateBook'] : results.data['addBook'] )
).subscribe( ({ id, name }) => {
console.log(`${msg}:\n -Id (${id}) \n -Name (${name})`);
});
this.reset();
}
The code starts by collecting the data to be sent to the server and stores them in variables object. In the case of editing an existing book, the Book Id is also sent to the server.
The Apollo Client is used to send a mutation request, this time using the mutate() function and specifying the name of the mutation as either addBookMutation or updateBookMutation.
The mutate() function expects the name of the mutation to run on the GraphQL Server API. In addition, the payload of the request is also passed to the mutate() function. Finally, the code instructs the Apollo Client to refresh or re-execute the getBooksQuery so that, after adding or editing a book, the list of books will automatically reflect the changes.
When deleting a book, another mutation is called on the GraphQL Server API with this code:
delete(): void {
if (confirm('Are you sure you want to delete this book?')) {
// delete
this.apollo.mutate({
mutation: deleteBookMutation,
variables: { id: this.model.id },
refetchQueries: [{
query: getBooksQuery
}]
})
.subscribe( (data: any) => {
});
this.reset();
}
}
If the user confirms that they want to delete the book, then the code issues a call on the Apollo Client to execute the deleteBookMutation on the GraphQL Server API, passing along the way the Book Id.
That’s it!
Conclusion
GraphQL is a new standard and a broad topic to just cover in one-part pair of articles. I tried to summarise all the major features of GraphQL by building a GraphQL Server and then demonstrating how you can communicate with the GraphQL Server via an Angular app with the help of Apollo Client for Angular.




