
Introduction
In my last post, Quick Guide to Playwright Fixtures: Enhancing Your Tests, I delved into some of the enhancements we've been implementing in our end-to-end (E2E) tests using Playwright. As I refine our testing strategies, I've come across a tool that has quickly become an essential part of my workflow: the Playwright VSCode extension.
If you're like me and constantly looking for ways to streamline testing and debugging, you'll appreciate any tool that can make the process more efficient and enjoyable. That's where this extension comes in. It's not just about writing tests - it's about enhancing the entire development experience. In this post, I'll walk you through getting started with the Playwright VSCode extension, sharing some tips and tricks that have made a real difference in my day-to-day work.
Installing the Extension & Basic Setup
Before diving into the Playwright VSCode extension, it's essential to have Playwright installed on your machine. If you haven't done so already, you can quickly install it by running:
npx playwright install
This command will set up Playwright and ensure all necessary dependencies are installed.
Once Playwright is ready, the VSCode extension will be installed next. Open Visual Studio Code, navigate to the Extensions view by clicking on the Extensions icon in the Activity Bar on the side of the window, and search for “Playwright”. The official extension, ID: ms-playwright.playwright / named: “Playwright Test for VSCode” by Microsoft, should appear at the top of the list. Click "Install," and you're all set.
With the extension installed, you can start leveraging its powerful features to enhance your Playwright testing workflow within VSCode.
Running the Tests and Identifying Outputs
To run a test, simply open the test file in VSCode. The Playwright extension will automatically detect test files and display a "Run" icon next to each test and test suite. You can click on this icon to run individual tests or test suites.
Alternatively, you can run all the tests in your project using the Playwright Test Explorer, accessible from the sidebar.

Once you start running your tests, the extension provides real-time feedback within the editor. You'll see the status of each test - whether it passes, fails, or is skipped - right next to the corresponding test in your code. This immediate feedback loop is incredibly helpful for catching issues as you write your tests.

The output of your tests will be displayed in the VSCode terminal. You'll see detailed information about each test run.
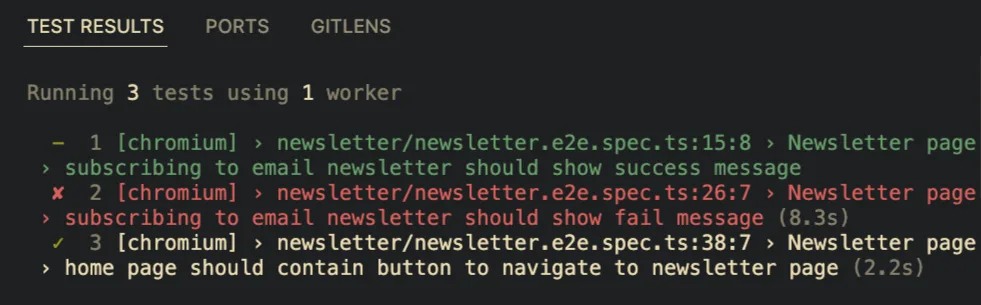
Debugging Step-by-Step
I find debugging particularly useful when a test fails unexpectedly or when I want to verify that certain actions are being performed as intended. Instead of guessing what might be wrong, I can see exactly what's going on in each test step, making debugging a much more straightforward and less frustrating process.
To start debugging, you can easily set a breakpoint in your test file by clicking on the left margin next to the line number where you'd like the execution to pause. Once your breakpoints are in place, you can initiate the debug process by selecting the "Debug" option next to the test you'd like to investigate.
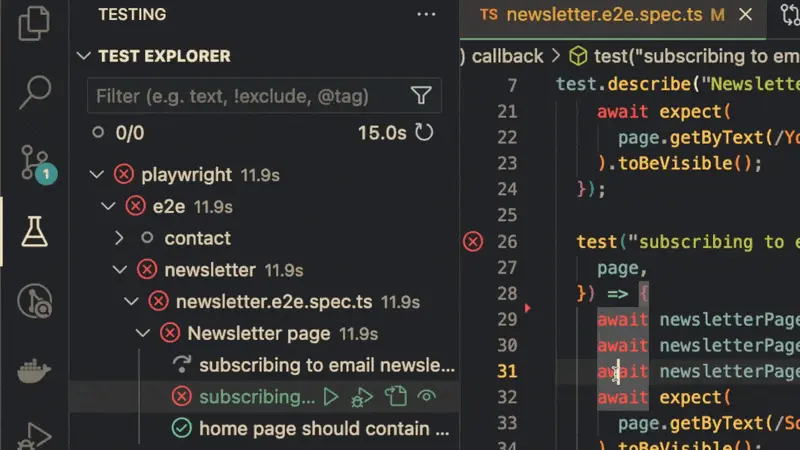
Once the debugger is running, the extension allows you to step through your code, inspect variables, and evaluate expressions - all within VSCode. This real-time insight into your test execution is a game-changer, enabling you to pinpoint issues more effectively and confidently refine your tests.
Using the Pick Locator Tool
Another handy feature is the "Pick Locator" tool. If you've ever struggled with selecting the right element in your tests, this tool can be a time saver. It helps you generate reliable locators by letting you interact directly with the webpage elements you want to target.
To use the Pick Locator tool, click the "Pick Locator" button in the Playwright Test Explorer. This will open a new window where you can navigate to the site you're testing. As you hover over elements on the page, the tool will suggest locators, allowing you to select the most appropriate one for your test.

While the Pick Locator tool is handy, it’s important to ensure that the locators you generate are robust and maintainable. This is especially true when integrating them with the fixtures I discussed in my previous blog post. Combining the proper locators with well-designed fixtures can create more reliable and reusable test setups, ultimately making your E2E tests more efficient.
Conclusion
The Playwright VSCode extension has quickly become indispensable in my development workflow. It significantly enhanced my experience of writing and running Playwright tests.
Whether you’re just starting with Playwright or looking to optimize your existing tests, this extension offers a range of features that can save you time and effort. Combining these tools with thoughtful test design, such as leveraging fixtures, you can create a more efficient and effective testing process.
I hope this guide has given you a good overview of what the Playwright VSCode extension can do and how it can benefit your work. If you haven’t tried it yet, I highly recommend giving it a go. And as always, feel free to explore further and experiment with the features that best suit your needs.




