When programming, a lot of time is spent reading and debugging code. When coming to grips with a new framework or library, it is important to know how to debug it when things eventually go astray. Angular has a plethora of useful 1st party and 3rd party tools that will aid you in debugging your application effectively.
Angular Devtools
First thing’s first, if you don’t have the Angular Devtools already, then you should download them. The Angular Devtools does many things such as allowing you to view the component tree live as your application runs, view the state of components in your application, and profile your application.
Below, I have an Angular application loaded, and I can view the internal state and configuration of the various components present.
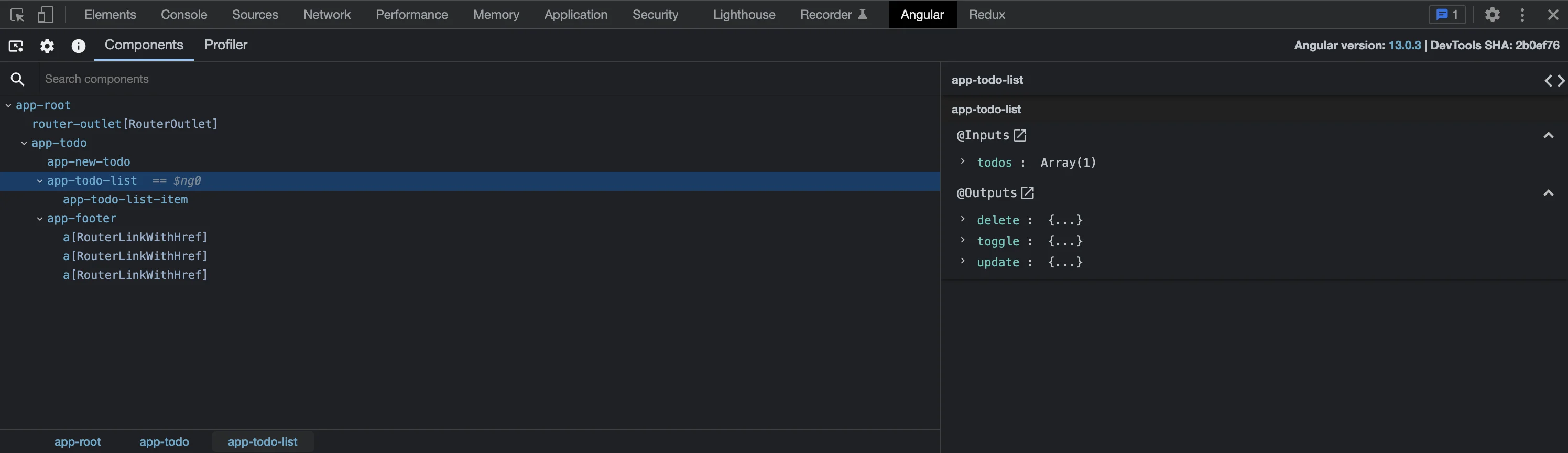
There is also a “Profiler” tab that can be used for measuring the performance of your individual components. You may ask what performance profiling has to do with debugging. Performance issues are problematic like any bug, and can lead to a detrimental user experience. Being able to identify these issues will make it easier for you to fix these issues, and improve the application.
The profiler gives us a breakdown of the resources used by each component. This is very useful for identifying performance bottlenecks in your application.
One last thing I should mention is the ability to jump to the source code of the component you currently have selected. The button looks like a pair of angle brackets in the top-right corner. This is useful if you need to use the built-in debugger provided by the browser. I highly recommend reading up on the official guide for Angular Devtools, which goes more in-depth about the various features.
Using a JavaScript Debugger
Do not forget that your browser has a built-in debugger. Angular application dev builds are very debuggable as source maps are provided by webpack. If you’re using the Angular CLI for your developer server, then you should already be good to go!
You can access your source code through the “Sources” tab, and it will be available under the “webpack://” dropdown. However, it isn’t very convenient to navigate your source code like this. Instead, you can search for your TypeScript files using CTRL+P (or CMD+P on mac), or use the Angular Devtools to jump to the source code of your components.
Once you’re in the source file, you can place breakpoints directly in your TypeScript files! Do note that debugging the original TypeScript files is not available in production builds.
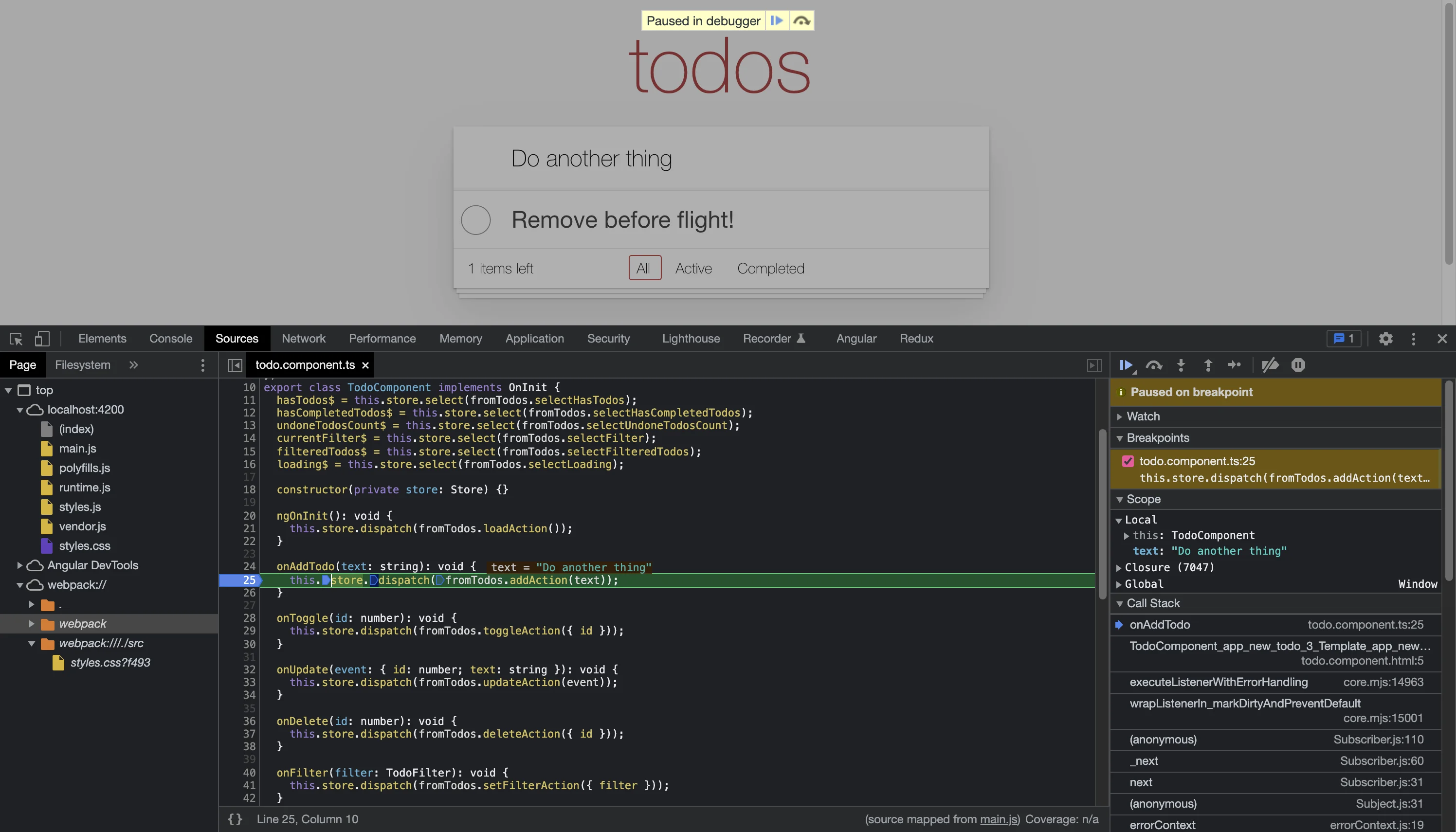
You should try to use the debugger over “console.log” in most situations. It will be much easier to view the state of your application here, and understand what is going on.
Redux Devtools
Lots of Angular applications are using NgRx for state management now. One important thing to keep in mind is that NgRx is compatible with the Redux devtools browser extension. Although NgRx is not based on Redux, that does not stop it from being compatible with its developer tools! Isn’t that neat?
You can install the Redux devtools from your browser’s respective extension marketplace. Once it’s installed, you should see a new tab when you open devtools (F12). Here, you can see I have loaded up a demo application that uses Redux, and the tools appear to be working!
Before we dig in deeper, I should mention that the application has to do some extra setup to ensure that Redux Devtools works. Out of the box, your application will not work with Redux Devtools until you import the StoreDevTools module. That can easily be done by adding another import to your module.ts file.
@NgModule({
// Properties...
imports: [
// Other imports...
EffectsModule.forRoot([TodosEffects]),
!environment.production
? StoreDevtoolsModule.instrument({
name: 'TodoMVC app using Angular & NgRx',
maxAge: 50,
})
: [],
],
// Properties...
})
export class AppModule {}
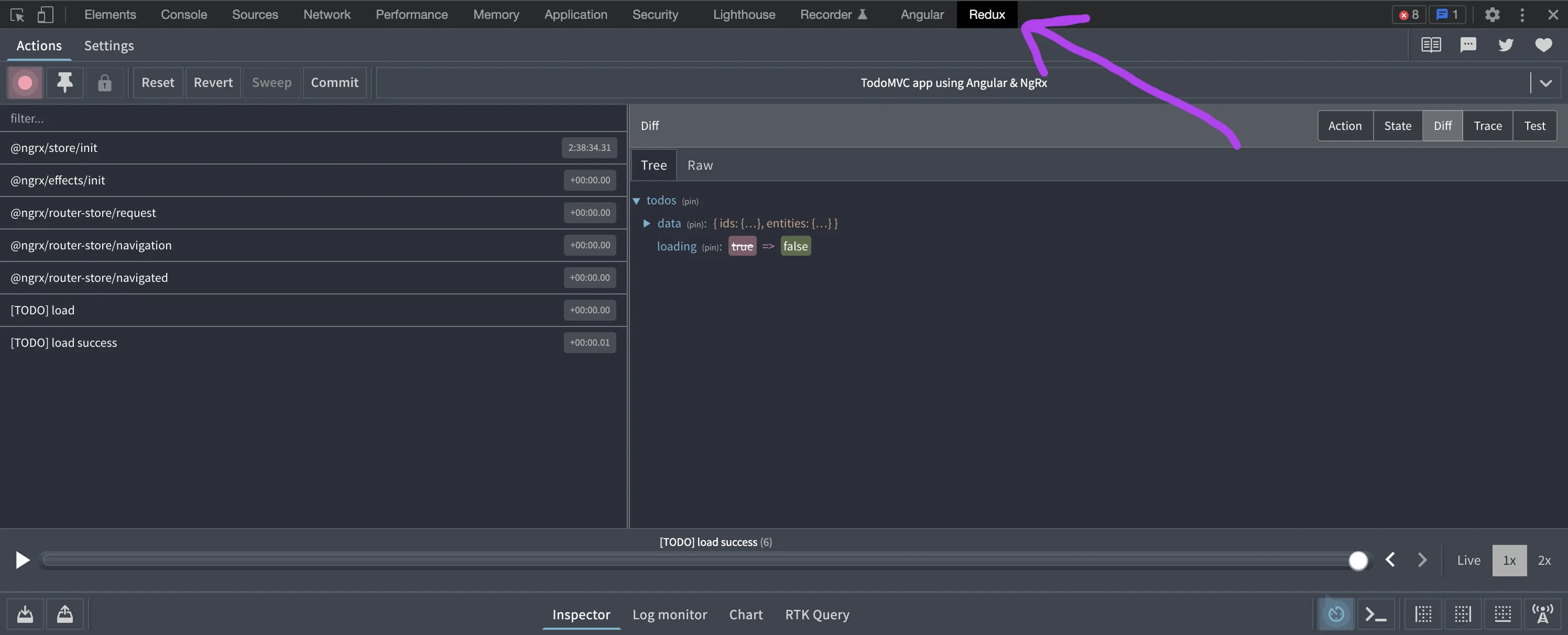
There are a few things to describe on this screen. Let’s talk about the left sidebar. It is here that you will find a list of actions that have been emitted throughout the lifetime of the application. The first 5 actions are emitted by NgRx after performing initialization of the store and the router. Everything after those are from the application code for the particular example we’re using.
Clicking on one of the actions and having the “Diff” view action on the right-hand side will show what state was changed by it. In the TODO MVC example I used, there are two actions that happen upon initialization. The first just updates a loading flag to true. Then, the second one adds the TODO entries and flips the loading flag back to false.
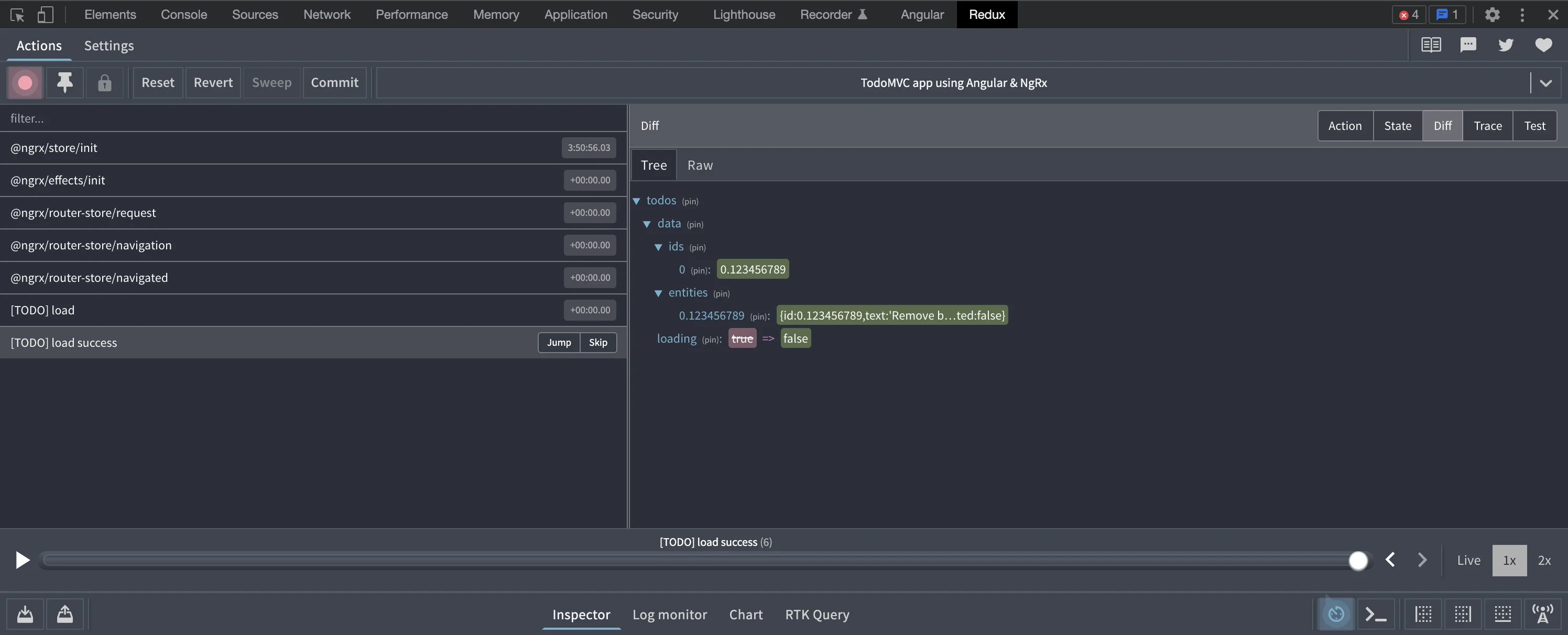
You can also view the contents of individual actions through “Action”, the overall state at that point in time with “State”, generate Jest tests that replay the creation of the state with “Test”, and use “Trace” to find the callstack of whatever triggered the action in the first place. The trace tab in-particular, can be very helpful if an action is being emitted unexpectedly, and you want to figure out why.
I did all of this analysis against the todomvc-angular-ngrx repository if you want to try using the Redux devtools for yourself. We have only glossed the surface of the Redux Devtools here, and I could write a whole article about this wonderful piece of software, but we already did that! If you want to learn more, please consider reading our more in-depth article, Developer Tools & Debugging in NgRx.
Using ng.profiler for Identifying Change Detection Issues
We’ve already gone over the Angular Devtools profiler, but there is another tool provided by Angular that we can use for identifying performance issues related to change detection. For the uninitiated, change detection is the mechanism by which Angular checks for changes to your application’s state, and re-renders views when it does happen. Sometimes, change detection may cause performance issues in larger applications, and one easy way to find out if this is harming it is to use ng.profiler.
ng.profiler can be run on the browser’s console once it is enabled. To enable it, you must call “enableDebugTools” after your app module is finished initializing. I recommend only doing this for dev builds.
platformBrowserDynamic()
.bootstrapModule(AppModule)
.then(moduleRef => {
if (!environment.production) {
const applicationRef = moduleRef.injector.get(ApplicationRef);
const componentRef = applicationRef.components[0];
// Ensure that `ng.profiler` exists.
enableDebugTools(componentRef);
}
})
.catch(err => console.error(err));
With this code in “main.ts”, we can now use ng.profiler.

Hurray, it works! As you can see, there’s no problem with change detection in our current view of the application. If there is a problem however, there is an extra option that you can specify to get more fine-grained details. Pass the “record” option into ng.profiler like so.
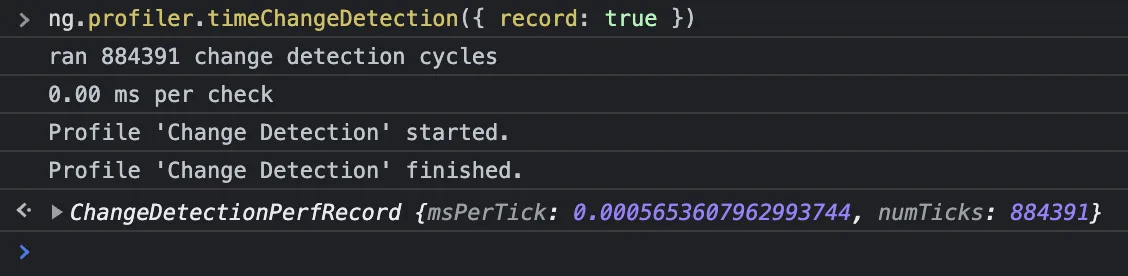
To view the results of the profiling we must ensure that the JavaScript Profiler is enabled (note: this is Chrome specific). You can enable this feature via the Devtools Hamburger Menu > More Tools > JavaScript Profiler.
Once that’s enabled, you should have a new “JavaScript Profiler” tab that contains your results!
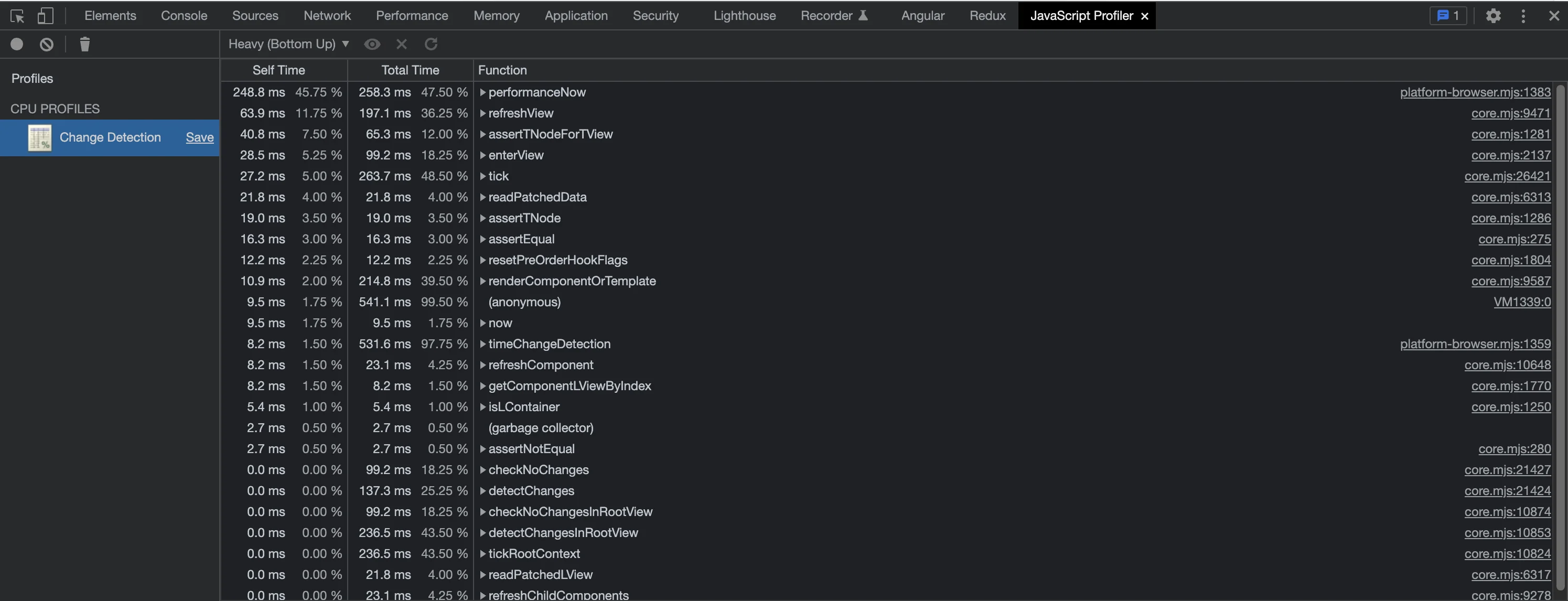
This may look a little intimidating because you will see a lot of results for functions that you don’t have direct control over. Essentially, this is a breakdown of the amount of time it takes for functions in your project to execute. You can sort by total time spent to identify bottlenecks being caused by JavaScript execution as a result of change detection being triggered.
Since the code in my example is fairly minimal, you’re only going to see function calls from the libraries we are using. In a heavier real-world application, you will likely see references to functions in your own application if they’re doing a lot of work on the CPU.
Conclusion
When encountering difficult bugs, whether they’re performance related or otherwise, it helps to know what tools are at your disposal. I hope this information proves useful in your future bug hunts!




