Developer Tools & Debugging in NgRx
When working on a complex software solution, we often find ourselves scratching our heads over a bug that was reported to us. It's essential to have proper tools to trace the issues which like to hide in our code execution paths. Luckily for the devs using NgRx in their project, the application state is kept in a single location and all the actions that can modify it are easily traceable with some great DevTools. As NgRx adheres to the redux pattern, we can use the same Redux DevTools as we would use for any other Redux base application. This tool is essential for me when debugging an NgRx based application.
If you haven't worked with NgRx yet, I recommend reading this post first where I introduced the NgRx pattern into a simple app.
Getting started
In order to make our NgRx store visible in the Redux DevTools, we need to pull in a module provided by NgRx platform - @ngrx/store-devtools. For the installation instructions, please visit the official installation guide.
After installing the Store Devtools using the AngularCLI schematics, the following code is automatically added to our AppModule:
@NgModule({
/* other module properties */
imports: [
/* other imported modules */
StoreDevtoolsModule.instrument({
maxAge: 25, // Retains last 25 states
logOnly: environment.production, // Restrict extension to log-only mode
}),
],
})
maxAge property is limited to 25 by default for performance reasons - this is the limit of actions stored in the history tree.
logOnly is usually set to true on production build to limit the number of features used when connecting to Redux DevTools.
I suggest adding name property to our initial configuration to more easily find our state in the DevTools (as it will show all the other stores which might be used in other tabs open in the browser).
@NgModule({
/* other module properties */
imports: [
/* other imported modules */
StoreDevtoolsModule.instrument({
name: 'DevTools & Debugging in NgRx'
maxAge: 25, // Retains last 25 states
logOnly: environment.production, // Restrict extension to log-only mode
}),
],
})

With that minimal setup, we can already start using the Redux DevTools to start debugging our application.
You can access the Redux DevTools in the Redux tab on your browser developers tools.

Tracking actions
The first thing you can do in the Redux DevTools is track all the actions that have been dispatched within the application.

For every selected action, you can see the current state value, what exactly has changed in the state as a result of this action, and the content of action object.



Moreover, the extension gives you the possibility to "time travel" your application and skip some of the actions to see how it would affect the end result of the state.
You can either manually select the point in time to jump to or replay the whole sequence of action using timeline at the bottom.
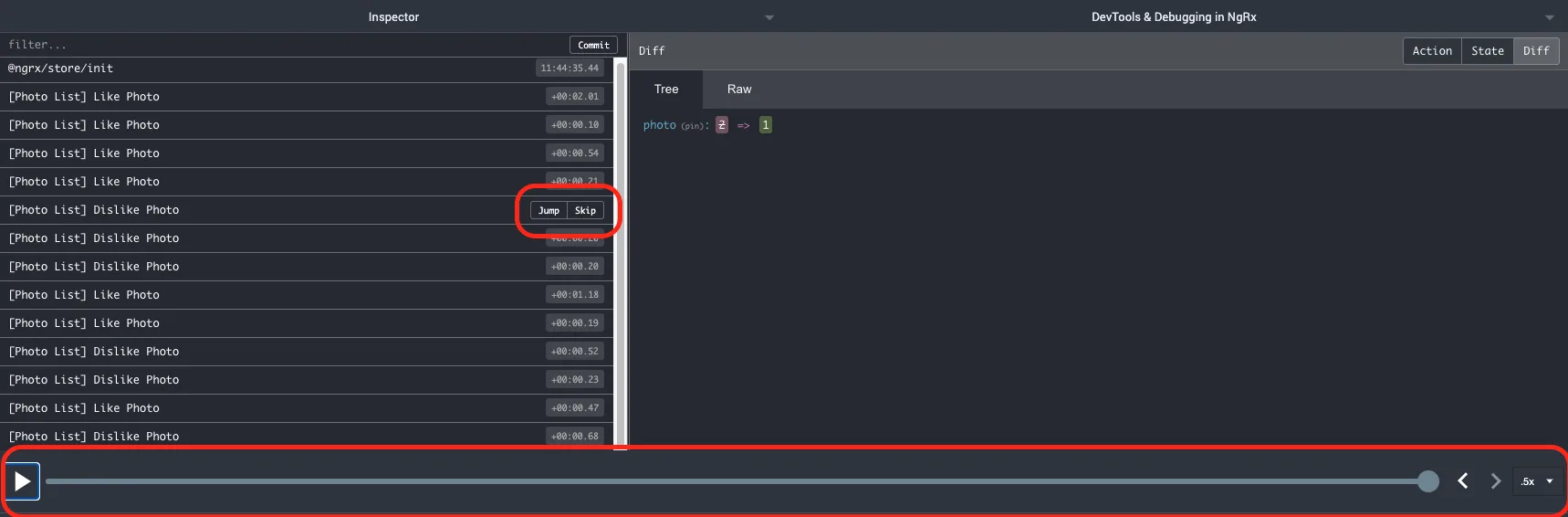
Those functionalities alone provide us with handful of possibilities on tracking how the state of our app is changing over time and pinpointing the possible issues.
Replicating the app behavior
Another very powerful feature of the Redux DevTools is tha posibility to dispatch the actions without the need of interacting with the UI. It's available as one of the tabs in the bottom extension's menu:
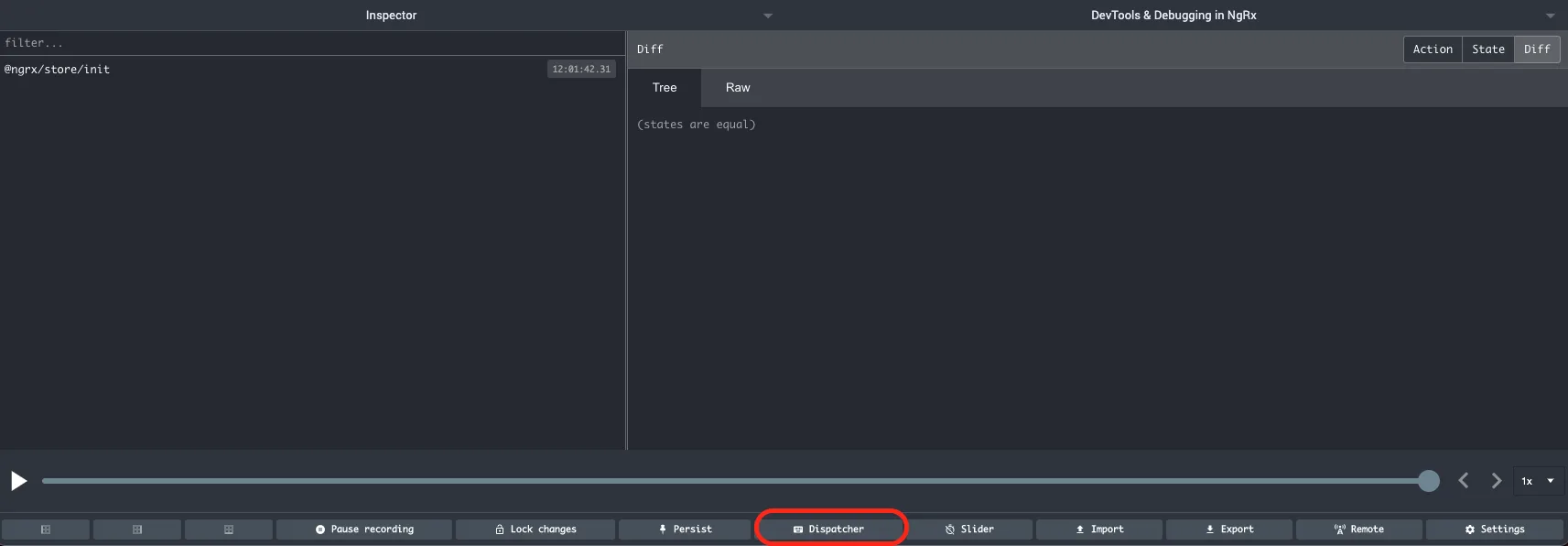
By using this feature, we can dispatch any action we want. This is extremely useful if we find the exact course of actions that is leading to an error, but it's hard or long to replicate using the UI. We can enter and dispatch the desired sequence of actions and get to the troublesome point in the app state with ease and in a reproducible manner.
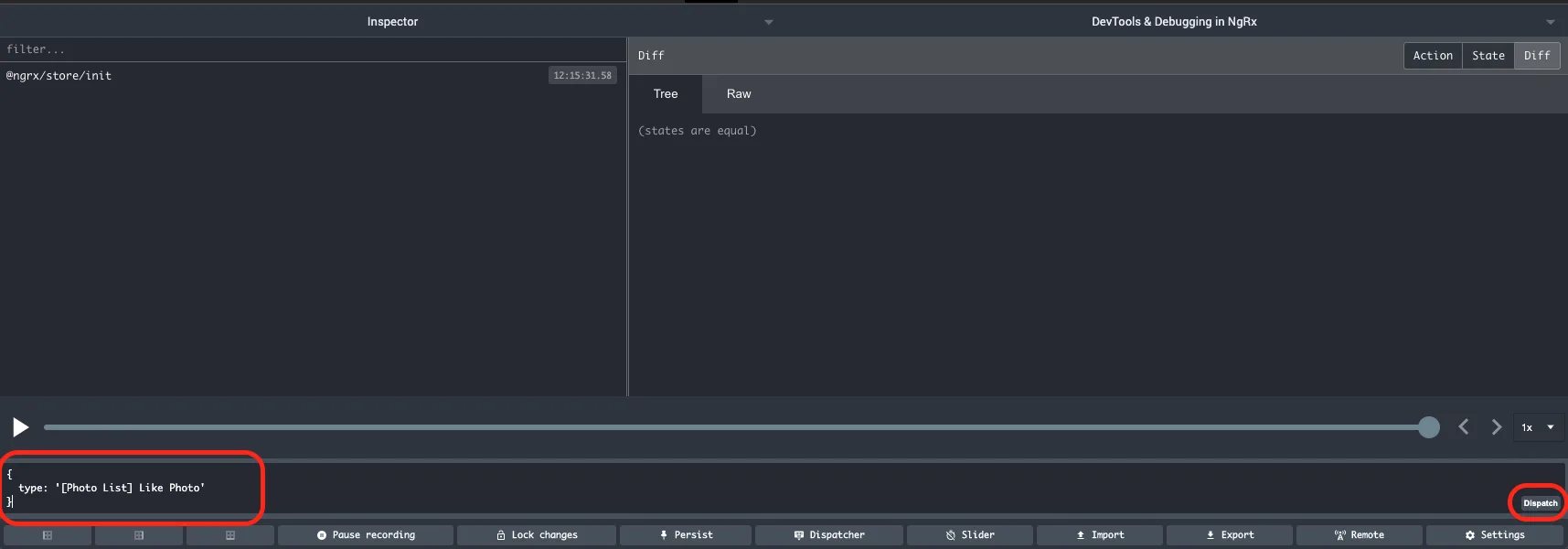
There are a few features that combine well with the aforementioned dispatching technique:
- Persisting the state
- Commiting and reverting the state
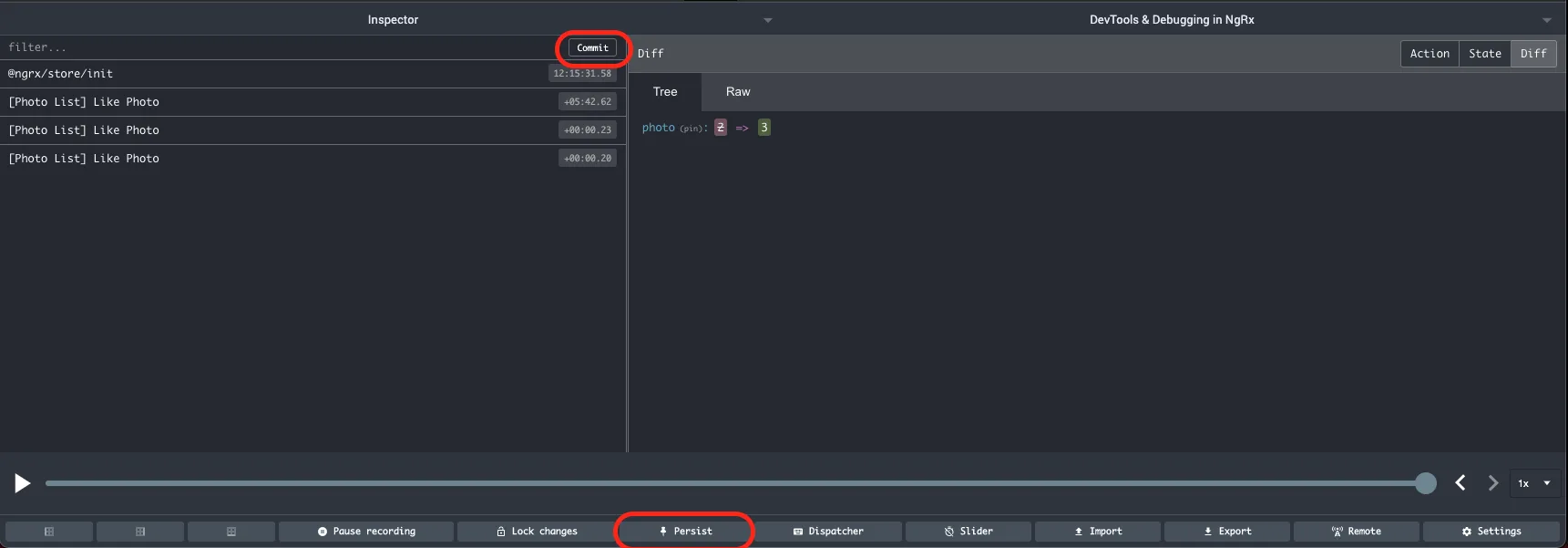
When we select the persist option, the extension makes sure that our state is persisted and restored even after we reload the page. The commit option allows us to store the state at the specific point in time and treat it as a starting point (it's like saving the game before going on to fight with the boss 🤓).
You can perform as many actions as you want from this point on, but you'll always be able to restore the state to a point in time at which you've done a last commit. The restore functionality is only available in the log monitor and not the inspector.
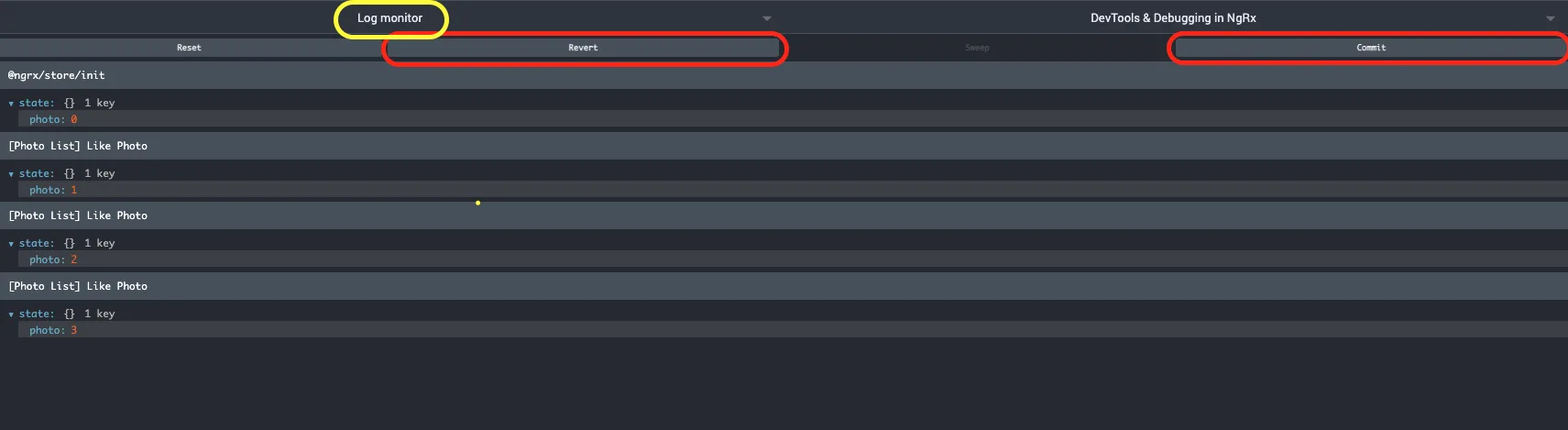
This plays really well with dispatching actions directly from the extension. We can test and debug how our application behaves (ie. via Effects) when dipatching a specific action with always exactly the same comitted state. Also, it's easy to repeat by reverting the state and dispatching the action again.
NgRx Store Dev Tools options
So far we've covered many use-cases of the Redux DevTools, but we can configure it's behavior to our needs when setting up the StoreDevtoolsModule.
In real life applications, our action log might consist of hundreds of actions which might pollute our view of what is happening in the app. We can filter them out directly in the extension but that doesn't solve the issue of the limit on number of actions visible at once. We're still limited by whatever the limit we set, and for performance reasons, we should not take this limit off or set it too high. For debugging purposes, we might only be interested in certain type of actions or definitely know that some actions (ie. the one dispatched by Angular Router) might not be useful to us at the given moment. When setting up our StoreDevtoolsModule we're given 3 ways to filter the actions that will be sent to the Redux DevTools extension:
actionBlocklistactionSafelistpredicate
The first two are the most common ones to use. We can either block specific patters of actions (which we know that are not of interest to us) or we can allow only certain types of actions. Both of them take an array of strings as a value and act as a regex on action type property to filter out only the ones we're interested in.
If we want to do more specific filtering, we can use predicate. It takes current state and action as parameters and is called for each dispatched action. To allow action to be passed to the Redux DevTools extension, it must return true.
With those techniques, we can narrow the scope of actions visible in the extension and therefore make it easier to get the grasp of what is happening in the app.
Conclusion
With the tools and techniques mentioned above, you should be able to debug your NgRx based application with a bit more ease. It's important to know the tools you have available so that you can use them when the need arises.
In case you have any questions you can always tweet or DM at me @ktrz. I'm always happy to help!




