
Advanced Authentication and Onboarding Workflows with Docusign Extension Apps
Docusign Extension Apps are a relatively new feature on the Docusign platform. They act as little apps or plugins that allow building custom steps in Docusign agreement workflows, extending them with custom functionality. Docusign agreement workflows have many built-in steps that you can utilize. With Extension Apps, you can create additional custom steps, enabling you to execute custom logic at any point in the agreement process, from collecting participant information to signing documents.
An Extension App is a small service, often running in the cloud, described by the Extension App manifest. The manifest file provides information about the app, including the app's author and support pages, as well as descriptions of extension points used by the app or places where the app can be integrated within an agreement workflow.
Most often, these extension points need to interact with an external system to read or write data, which cannot be done anonymously, as all data going through Extension Apps is usually sensitive. Docusign allows authenticating to external systems using the OAuth 2 protocol, and the specifics about the OAuth 2 configuration are also placed in the manifest file. Currently, only OAuth 2 is supported as the authentication scheme for Extension Apps.
OAuth 2 is a robust and secure protocol, but not all systems support it. Some systems use alternative authentication schemes, such as the PKCE variant of OAuth 2, or employ different authentication methods (e.g., using secret API keys). In such cases, we need to use a slightly different approach to integrate these systems with Docusign.
In this blog post, we'll show you how to do that securely. We will not go too deep into the implementation details of Extension Apps, and we assume a basic familiarity with how they work. Instead, we'll focus on the OAuth 2 part of Extension Apps and how we can extend it.
Extending the OAuth 2 Flow in Extension Apps
For this blog post, we'll integrate with an imaginary task management system called TaskVibe, which offers a REST API to which we authenticate using a secret API key. We aim to develop an extension app that enables Docusign agreement workflows to communicate with TaskVibe, allowing tasks to be read, created, and updated.
TaskVibe does not support OAuth 2. We need to ensure that, once the TaskVibe Extension App is connected, the user is prompted to enter their secret API key. We then need to store this API key securely so it can be used for interacting with the TaskVibe API. Of course, the API key can always be stored in the database of the Extension App. Sill, then, the Extension App has a significant responsibility for storing the API key securely. Docusign already has the capability to store secure tokens on its side and can utilize that instead. After all, most Extension Apps are meant to be stateless proxies to external systems.
Updating the Manifest
To extend OAuth 2, we will need to hook into the OAuth 2 flow by injecting our backend's endpoints into the authorization URL and token URL parts of the manifest. In any other external system that supports OAuth 2, we would be using their OAuth 2 endpoints. In our case, however, we must use our backend endpoints so we can emulate OAuth 2 to Docusign.
"connections": [
{
"name": "authentication",
"description": "Secure connection to TaskVibe",
"type": "oauth2",
"params": {
"provider": "CUSTOM",
"clientId": "my-client-id",
"clientSecret": "my-secret",
"scopes": [],
"grantType": "authorization_code",
"customConfig": {
"authorizationMethod": "body",
"authorizationParams": {
"prompt": "consent",
"audience": "api.taskvibe.example.com",
"client_id": "my-client-id",
"response_type": "code"
},
"authorizationUrl": "https://your-backend/authorize",
"requiredScopes": [],
"scopeSeparator": " ",
"tokenUrl": "https://your-backend/api/token",
"refreshScopes": []
}
}
}
]
The complete flow will look as follows:
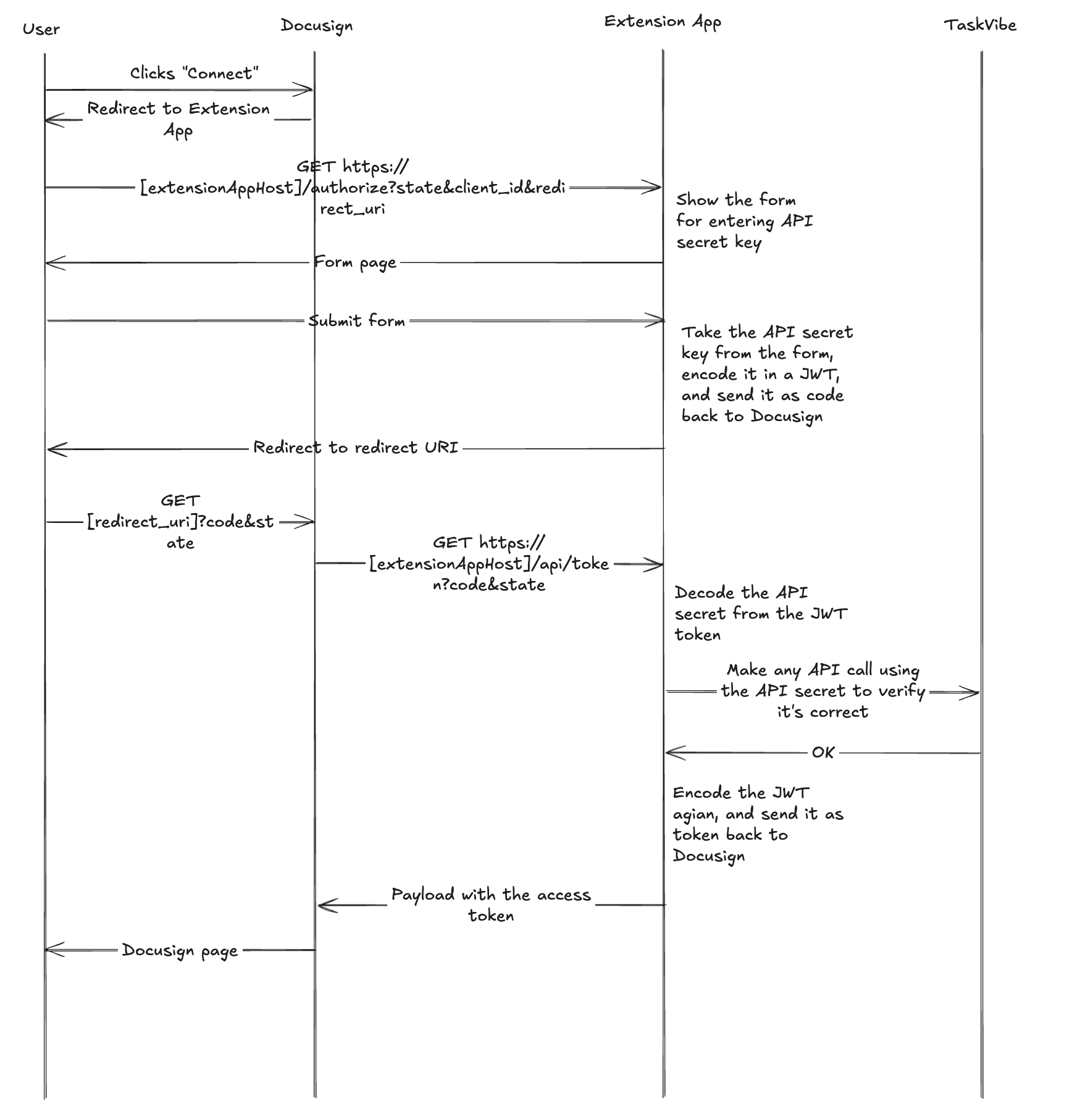
In the diagram, we have four actors: the end-user on behalf of whom we are authenticating to TaskVibe, DocuSign, the Extension App, and TaskVibe. We are only in control of the Extension App, and within the Extension App, we need to adhere to the OAuth 2 protocol as expected by Docusign.
- In the first step, Docusign will invoke the
/authorizeendpoint of the Extension App and provide thestate,client_id, andredirect_uriparameters. Of these three parameters,stateandredirect_uriare essential. - In the
/authorizeendpoint, the app needs to store state andredirect_uri, as they will be used in the next step. It then needs to display a user-facing form where the user is expected to enter their TaskVibe API key. - Once the user submits the form, we take the API key and encode it in a JWT token, as we will send it over the wire back to Docusign in the form of the code query parameter. This is the "custom" part of our implementation. In a typical OAuth 2 flow, the code is generated by the OAuth 2 server, and the client can then use it to request the access token. In our case, we'll utilize the code to pass the API key to Docusign so it can send it back to us in the next step. Since we are still in control of the user session, we redirect the user to the redirect URI provided by Docusign, along with the code and the state as query parameters.
- The redirect URI on Docusign will display a temporary page to the user, and in the background, attempt to retrieve the access token from our backend by providing the code and state to the
/api/tokenendpoint. - The
/api/tokenendpoint takes the code parameter and decodes it to extract the TaskVibe API secret key. It can then verify if the API key is even valid by making a dummy call to TaskVibe using the API key. If the key is valid, we encode it in a new JWT token and return it as the access token to Docusign. - Docusign stores the access token securely on its side and uses it when invoking any of the remaining extension points on the Extension App.
By following the above step, we ensure that the API key is stored in an encoded format on Docusign, and the Extension App effectively extends the OAuth 2 flow. The app is still stateless and does not have the responsibility of storing any secure information locally. It acts as a pure proxy between Docusign and TaskVibe, as it's meant to be.
Writing the Backend
Most Extension Apps are backend-only, but ours needs to have a frontend component for collecting the secret API key. A good fit for such an app is Next.js, which allows us to easily set up both the frontend and the backend.
We'll start by implementing the form for entering the secret API key. This form takes the state, client ID, and redirect URI from the enclosing page, which takes these parameters from the URL.
The form is relatively simple, with only an input field for the API key. However, it can also be used for any additional onboarding questions. If you will ever need to store additional information on Docusign that you want to use implicitly in your Extension App workflow steps, this is a good place to store it alongside the API secret key on Docusign.
// components/auth-form.tsx
"use client";
import type React from "react";
import { useState } from "react";
import { authorizeUser } from "@/lib/actions";
interface AuthFormProps {
state: string;
clientId: string;
redirectUri: string;
}
export function AuthForm({ state, clientId, redirectUri }: AuthFormProps) {
const [apiKey, setApiKey] = useState("");
const [isSubmitting, setSubmitting] = useState(false);
const handleSubmit = async (e: React.FormEvent) => {
e.preventDefault();
setSubmitting(true);
try {
await authorizeUser(apiKey, state, redirectUri);
} catch (error) {
console.error("Authorization failed:", error);
setSubmitting(false);
}
};
return (
<div className="card max-w-md w-full">
<div className="card-header">
<h2 className="card-title">Connect to TaskVibe</h2>
<p className="card-description">
To authenticate with TaskVibe task management tool, please enter your
API secret key below.
</p>
</div>
<form onSubmit={handleSubmit}>
<div className="card-content">
<div className="form-group">
<label htmlFor="apiKey" className="form-label">
API Secret Key
</label>
<input
id="apiKey"
type="password"
className="form-input"
placeholder="Enter your TaskVibe API key starting with tv_"
value={apiKey}
onChange={(e) => setApiKey(e.target.value)}
required
autoComplete="off"
/>
</div>
<input type="hidden" name="state" value={state} />
<input type="hidden" name="redirectUri" value={redirectUri} />
</div>
<div className="card-footer">
<button
type="submit"
className="btn btn-primary w-full"
disabled={isSubmitting}
>
{isSubmitting ? "Connecting..." : "Connect"}
</button>
</div>
</form>
</div>
);
}
Submitting the form invokes a server action on Next.js, which takes the entered API key, the state, and the redirect URI. It then creates a JWT token using Jose that contains the API key and redirects the user to the redirect URI, sending the JWT token in the code query parameter, along with the state query parameter. This JWT token can be short-lived, as it's only meant to be a temporary holder of the API key while the authentication flow is running.
This is the server action:
// lib/actions.ts
"use server";
import { redirect } from "next/navigation";
import { signJwt } from "./jwt";
export async function authorizeUser(
apiKey: string,
state: string,
redirectUri: string,
) {
// Create a JWT with 1 hour expiration
// This is only for the initial authorization code flow, which should be short-lived
const code = await signJwt({ apiKey }, { expiresIn: "1h" });
// Construct the redirect URL with state and code
const redirectUrl = new URL(redirectUri);
redirectUrl.searchParams.append("state", state);
redirectUrl.searchParams.append("code", code);
// Redirect to the callback URL on Docusign
// Docusign will then invoke the token endpoint with the code to obtain the access token
redirect(redirectUrl.toString());
}
After the user is redirected to Docusign, Docusign will then invoke the /api/token endpoint to obtain the access token. This endpoint will also be invoked occasionally after the authentication flow, before any extension endpoint is invoked, to get the latest access token using a refresh token. Therefore, the endpoint needs to cover two scenarios.
In the first scenario, during the authentication phase, Docusign will send the code and state to the /api/token endpoint. In this scenario, the endpoint must retrieve the value of the code parameter (storing the JWT value), parse the JWT, and extract the API key. Optionally, it can verify the API key's validity by invoking an endpoint on TaskVibe using that key.
Then, it should return an access token and a refresh token back to Docusign. Since we are not using refresh tokens in our case, we can create a new JWT token containing the API key and return it as both the access token and the refresh token to Docusign.
In the second scenario, Docusign will send the most recently obtained refresh token to get a new access token. Again, because we are not using refresh tokens, we can return both the retrieved access token and the refresh token to Docusign.
The api/token endpoint is implemented as a Next.js route handler:
// src/app/api/token/route.ts
export async function POST(request: NextRequest) {
try {
const body = await request.text();
const parsedBody = parseQueryString(body);
const { code, refresh_token } = parsedBody;
if (code) {
// This is the initial authorization code flow
// Verify and decode the JWT from the authorization code
const payload = await verifyJwt<{ apiKey: string }>(code);
const { apiKey } = payload;
// Verify the API key with TaskVibe
const isValid = await verifyApiKey(apiKey);
if (!isValid) {
return NextResponse.json({ error: "Invalid API key" }, { status: 401 });
}
// Create a new JWT with no expiration
const accessToken = await signJwt({ apiKey });
// Return the tokens
// We are not using a refresh token in this implementation, so we are returning the same token for both access and refresh
return NextResponse.json({
access_token: accessToken,
refresh_token: accessToken,
token_type: "Bearer",
});
} else if (refresh_token) {
// This is the flow that happens for every subsequent request
// The refresh token is the same as the access token we created in the initial authorization code flow
return NextResponse.json({
access_token: refresh_token,
refresh_token: refresh_token,
token_type: "Bearer",
});
}
return NextResponse.json(
{ error: "Missing required parameters" },
{ status: 400 },
);
} catch (error) {
console.error("Token exchange error:", error);
return NextResponse.json(
{ error: "Invalid or expired token" },
{ status: 401 },
);
}
}
In all the remaining endpoints defined in the manifest file, Docusign will provide the access token as the bearer token. It's up to each endpoint to then read this value, parse the JWT, and extract the secret API key.
Conclusion
In conclusion, your Extension App does not need to be limited by the fact that the external system you are integrating with does not have OAuth 2 support or requires additional onboarding. We can safely build upon the existing OAuth 2 protocol and add custom functionality on top of it. This is also a drawback of the approach - it involves custom development, which requires additional work on our part to ensure all cases are covered. Fortunately, the scope of the Extension App does not extend significantly. All remaining endpoints are implemented in the same manner as any other OAuth 2 system, and the app remains a stateless proxy between Docusign and the external system as all necessary information, such as the secret API key and other onboarding details, is stored as an encoded token on the Docusign side.
We hope this blog post was helpful. Keep an eye out for more Docusign content soon, and if you need help building an Extension App of your own, feel free to reach out. The complete source code for this project is available on StackBlitz.



