In our Getting Started With RxJS article, we briefly mentioned Operators. In this article, we will expand further on what Operators are in RxJS. We will also show you some basic Operators, what they do, and how you can use them.
What are RxJS Operators?
Taken straight from the RxJS manual:
Operators are the essential pieces that allow complex asynchronous code to be easily composed in a declarative manner.
If you're scratching your head, don't worry. I think most people would be confused by that statement alone. Luckily for us, the manual gives an even better definition:
An Operator is a function which creates a new Observable based on the current Observable. This is a pure operation: the previous Observable stays unmodified.
Essentially, an Operator is like a machine that takes an Observable as an input, performs some logic on the values streamed through the Observable, and creates a new Observable with these values, without changing the original Observable.
The diagram below might help illustrate it a little better.
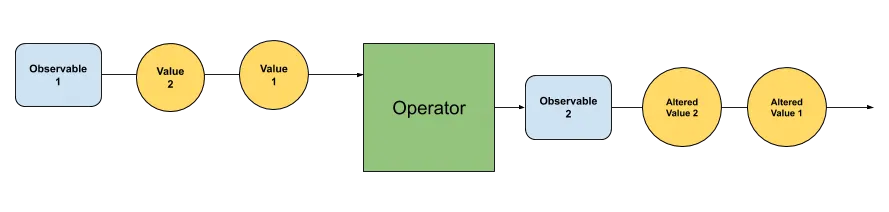
We can see that the Operator takes in the values from one Observable, and creates a new Observable that emits altered values of the original Observable's values, without affecting the original Observable.
Now let's take a look at 6 basic Operators: of, from, map, tap, switchMap, take.
1. of - Creation Operator
The of Operator is a creation Operator. Creation Operators are functions that create an Observable stream from a source.
The of Operator will create an Observable that emits a variable amount of values in sequence, followed by a Completion notification.
A Completion notification tells the Observable's subscribers that the Observable will no longer be emitting new values. We will cover this in more detail in a future article!
Let's take a look at of in practice.
const arr = [1, 2, 3];
const arr$ = of(arr);
arr$.subscribe((values) => console.log(`Emitted Values: `, values));
of creates the Observable, and when we subscribe to it, it starts emitting its values immediately.
The output of the above is:
Emitted Values: [1, 2, 3]
of will emit the full array [1, 2, 3] as a full value. This is in contrast to from, which we will look at next!
2. from - Creation Operator
The from Operator turns an Array, Promise, or Iterable, into an Observable.
This operator will convert a Promise to an Observable, allowing for it to be handled in a more reactive manner. When the Promise resolves or rejects, a completion notification will be sent to any subscribers.
Also, unlike of, it will emit each element in an Array or Iterable in sequence, rather than the full value. Once all elements of the Array or Iterable have been emitted, a completion notification is sent to any subscribers.
Let's take the example we used for of to see this difference in action:
const arr = [1, 2, 3];
const arr$ = from(arr);
arr$.subscribe((values) => console.log(`Emitted Values: `, values));
Its output is:
Emitted Values: 1
Emitted Values: 2
Emitted Values: 3
As we can see by the multiple logs, the from Operator took each number and emitted it as a value. The subscriber received each value in sequence, and called console.log three times.
We can also use a value such as a string:
const fromString$ = from("Hello");
fromString$.subscribe((value) => console.log(`Emitted Values: `, value));
The output is:
Emitted Values: H
Emitted Values: e
Emitted Values: l
Emitted Values: l
Emitted Values: o
How about for a Promise? Let's take a look!
const examplePromise = new Promise((resolve, reject) => {
// Do some async code and resolve and object with an id property
return resolve({ id: 1 });
});
const promise$ = from(examplePromise);
promise$.subscribe((value) => console.log(`Emitted Values: `, value));
The output of this would be:
Emitted Values: {id: 1}
When the Promise resolves, the value gets emitted as the next value in the Observable.
3. map - Transformation Operator
The map operator is a Transformation Operator. It takes values from one Observable, transforms them, and creates a new Observable that emits the transformed values.
With map, you can perform simple transformations to the values emitted by an Observable. Let's take a look at two examples.
For the first example, we'll take the Array example for the from Operator, and modify it to also use map:
const arr = [1, 2, 3];
const fromArr$ = from(arr);
fromArr$
.pipe(map((value) => value + 10))
.subscribe((value) => console.log(`Emitted Values: `, value));
You'll notice the introduction of the .pipe() call. This is RxJS's method for applying operators to an Observable's stream before you subscribe to it. It will pipe the value emitted from the Observable through each operator passed as an argument, before passing the final transformed value to the subscribe method. We'll cover this in more detail in a future article!
In this example, as map is a transformation Operator, it must be used within the .pipe() call so that it can transform the value it receives from the Observable. We are simply adding 10 to the value, and emitting the transformed value.
You can see this in the output:
Emitted Values: 11
Emitted Values: 12
Emitted Values: 13
We can do almost anything in the map Operator, but a common use-case would be to get a property from an object that is emitted in an Observable stream. We can use our Promise example to see this in action:
const examplePromise = new Promise((resolve, reject) => {
// Do some async code and resolve and object with an id property
return resolve({ id: 1 });
});
const promise$ = from(examplePromise);
promise$
.pipe(map((obj) => obj.id))
.subscribe((value) => console.log(`Emitted Values: `, value));
Here, we are telling the map operator to return the id property of the object that is resolved in the Promise. The output of this is:
Emitted Values: 1
The map Operator is a commonly used Operator and is very useful for a number of use-cases!
4. switchMap - Transformation Operator
The switchMap operator is another transformation Operator.
switchMap receives the values emitted by an Observable, and then returns a new Observable from a different source.
Let's say you have an Observable that emits User IDs. You may want to fetch the full User object correlating to the ID, then do something with the full details. The switchMap operator would receive the ID from the Observable, then return an Observable containing the response from the request to fetch the User object.
I find it can be useful to think of this in the terms of switching streams. You're switching from one Observable stream to another.
Let's take a look at an example:
const userDetails$ = from(this.userService.getActiveUserID())
.pipe(switchMap(id => this.userService.fetchUserForID(id)))
.subscribe(user => console.log("Found user ", user));
Here, we ask for the active user's ID. Then, we ask the userService to make an ajax request to our backend to fetch the User that correlates with the ID. We are assuming that the fetchUserForID call returns an Observable. (This can be possible with the ajax operator which we will discuss in a future article!)
We then subscribe to this new Observable stream, and receive the value it emits, rather than the values emitted from from(this.userService.getActiveUserID()) as seen in the output:
Found user {id: 1, name: "Test User", email: "test@test.com"}
It's worth noting that the switchMap operator will cancel any in-flight network requests if it receives a new value from the original (commonly known as the source) Observable stream, making it a great candidate for typeahead search implementations!
5. tap - Utility Operator
The tap Operator is a Utility Operator which is very similar to a helper function, except in the reactive programming landscape.
tap allows you to perform actions or side effects on an Observable stream without modifying or altering the original stream. The values "pass-through" the tap Operator to the next Operator or Subscriber.
This can be very useful for logging:
const arr = [1, 2, 3];
const fromArr$ = from(arr);
fromArr$
.pipe(tap((value) => console.log("Received value: ", value)))
.subscribe((value) => console.log(`Emitted Values: `, value));
Which would output:
Received value: 1
Emitted Values: 1
Received value: 2
Emitted Values: 2
Received value: 3
Emitted Values: 3
6. take - Filtering Operator
The take operator is a Filtering Operator. Filtering Operators allows you to select how and when to accept values emitted from Observables.
take is one of the most common and most simplistic filtering Operators. It allows you to specify a maximum number of values you want to receive from an Observable.
We can use our from example where we emit the elements of an Array, and combine it with take to get a better understanding of this operator:
const arr = [1, 2, 3];
const fromArr$ = from(arr);
fromArr$
.pipe(take(1))
.subscribe((value) => console.log(`Emitted Values: `, value));
From the output below we can see we only received and used 1 value from the array:
Emitted Values: 1
It can be used in situations where we want to limit how many user-produced events (fromEvent) we want to handle, for example, the first time the user clicks in our app.
Conclusion
In this article, we briefly covered some of what I would consider to be the most common Operators that live in RxJS. By understanding these 6 Operators, you are on your way to mastering RxJS! Stay tuned for more articles discussing more operators and more in-depth topics based on RxJS.




