Introduction
There is still a lot of confusion around Angular and AngularJS. It has gotten better, but searching for "Angular" still provides ambiguous results.
This is a problem because AngularJS is on Long Term Support (LTS) mode. It entered LTS on July 1, 2018, for 3 years. It was granted a six-month extension due to COVID-19. Therefore, all support is expected to end on December 31, 2021, meaning Google will stop fixing bugs and providing support for AngularJS.
All Angular engineering effort will be focused on the latest version of Angular making it prudent that active AngularJS codebases are migrated to Angular this year.
This article will showcase different migration paths available to achieve this.
Big Bang Rewrite
By far, the easiest way to migrate a legacy codebase is to simply start fresh from the ground up. You won't have to worry about conflicting packages or supporting different versions of the same package.
You would simply use the latest Angular CLI to scaffold out a new app and begin working on re-implementing your legacy app features with Angular.
However, this is a significant engineering effort.
This approach is excellent for very small AngularJS apps. However, it can also be possible for larger codebases.
For larger codebases, you could set aside one or two developers to perform bug fixes and tackle production issues on the AngularJS app. You would inform customers that new features will be considered but will likely take some time to become available in the app. You would then concentrate the rest of your engineering effort on rewriting the app in Angular.
This allows you to support your current app as it stands whilst reaching feature parity with the new Angular version of the app.
UpgradeModule
UpgradeModule is a tool provided by ngUpgrade by Angular to aid in the migration process. It allows you to run a hybrid application, mixing Angular and AngularJS apps. There is no emulation; it runs both frameworks at the same time.
UpgradeModule provides us with two options on how we run our application. We can either run the AngularJS app and downgrade our Angular code into it, or we can run the Angular app and upgrade our AngularJS code into Angular.
The Angular docs provide incredible documentation on setting up the hybrid application (you can read more here). We'll cover the basics here.
Downgrading to run in AngularJS
Generally, AngularJS apps can be bootstrapped using the ng-app directive such as:
<body ng-app="myApp">
</body>
However, for ngUpgrade to take full effect you need to manually bootstrap AngularJS:
angular.bootstrap(document.body, ['myApp'], {strictDi: true});
The next step in running the latest Angular framework in the AngularJS context is to load the framework itself.
This involves an outdated setup process where we need to use SystemJS to set up our Angular framework. The Angular framework no longer uses SystemJS by default for loading the framework; however, they have written a guide on how to do this here.
We then set up Angular to provide it with a reference to the AngularJS App and more importantly, its Dependency Injector: $injector.
import { NgModule } from '@angular/core';
import { BrowserModule } from '@angular/platform-browser';
import { UpgradeModule } from '@angular/upgrade/static';
@NgModule({
imports: [
BrowserModule,
UpgradeModule
]
})
export class AppModule {
constructor(private upgrade: UpgradeModule) { }
ngDoBootstrap() {
this.upgrade.bootstrap(document.body, ['myApp'], { strictDi: true });
}
}
Notice that this.upgrade.bootstrap has the same signature as angular.bootstrap.
The final thing to do now is to bootstrap the Angular framework, which is done easily with one line:
platformBrowserDynamic().bootstrapModule(AppModule);
Now we can create new Angular components and downgrade them into AngularJS.
Say we have an Angular component called HelloComponent. We use downgradeComponent provided by ngUpgrade to allow this component to be available to use in the AngularJS app:
import { downgradeComponent } from '@angular/upgrade/static';
import { HelloComponent } from './hello.component';
angular.module('myApp', [])
.directive(
'helloWorld',
downgradeComponent({ component: HelloComponent }) as angular.IDirectiveFactory
);
We can then use this in an AngularJS template:
<div ng-controller="MainCtrl as ctrl">
<hello-world></hello-world>
</div>
Notice that the directive is registered in camelCase (helloWorld) but we use it in our HTML with kebab-case (hello-world).
You're all set up to start migrating your components to Angular and downgrading them to be used in AngularJS.
However, I like to think you'll agree that there is a lot of setting up here, and it leaves you with an Angular codebase that uses SystemJS to bootstrap and load your app.
Upgrading to run in Angular
We can take a different approach with ngUpgrade and UpgradeModule, however. We could lazy load our AngularJS app into an Angular app that was scaffolded by the Angular CLI getting the full benefit of the build tools and leaving us with a codebase in line with the latest Angular.
The Angular docs provide a great guide on setting up the Lazy Load Approach.
It involves four things:
- An Angular Service to lazy load AngularJS and bootstrap the AngularJS App
- A file providing an entry point for AngularJS and the AngularJS App
- An Angular Component to render the AngularJS app (a wrapper component)
- Telling the Angular router when to route within the AngularJS app
Once these are complete (the Angular docs really do explain this best), you can start creating new Angular components and downgrading them to be used in the AngularJS app similarly to how it was done in the previous section.
You also get the benefit of a more straightforward method to upgrade AngularJS services to be used within Angular:
You create a factory provider and add it to the providers array of your Angular Module:
export function myServiceFactory(i: any) {
return i.get('my');
}
export const myServiceProvider = {
provide: myService,
useFactory: myServiceFactory,
deps: ['$injector']
};
/* ... */
@NgModule({
declarations: [MyComponent],
providers: [myServiceProvider]
})
export class MyModule {}
This means you can focus on upgrading your AngularJS components first, then circling back to your services afterwards.
This approach allows you to use all the modern Angular tools as well as providing you with an option of splitting up your AngularJS into smaller modules and only loading them as required. It also allows you to focus on upgrading smaller chunks of the AngularJS app at a time.
Take a look at this folder structure for an example:
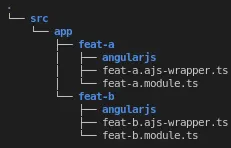
You would store the relevant AngularJS code for the feature in the corresponding angularjs folder. This means your team can focus on one feature at a time without losing any functionality for your customers.
Angular Elements
Another approach that is gaining some popularity is to use Angular's Web Component solution, called Angular Elements.
Angular Elements allows you to package up your Angular Component as a Web Component enabling it to be distributed and rendered in a plain old JavaScript context.
This is awesome for migrating AngularJS codebases. It means we can create an Angular Component, bundle it as a Web Component and drop it into our AngularJS codebase with less set up than the ngUpgrade approach.
This approach does have some drawbacks. We need a good build pipeline that will bundle the Angular Components, make them available, and include them into the AngularJS codebase so that they can be loaded and used in this context.
One approach to take that employs this would be to create two folders: one for your AngularJS codebase, one for your Angular codebase.
You would keep your AngularJS codebase as is. All new work would occur in the Angular codebase.
You can use the Angular CLI to scaffold out a monorepo. Each component you intend to upgrade would live in its own /projects folder (this is an Angular CLI workspace convention).
To do this, you can run the command:
ng generate application my-component
Next, you need to add Angular Elements to your workspace:
ng add @angular/elements --project=my-component
This would create a folder and accompanying files at /projects/my-component.
You would then create your component:
ng generate component my-component --project=my-component
This will scaffold out the component files you need.
Once you have finished setting up your component, you need to use Angular Elements to convert it to a Web Component.
Modify the app.module.ts at the root of /projects/my-component:
@NgModule({
imports: [BrowserModule],
declarations: [MyComponent],
bootstrap: [],
entryComponents: [MyComponent]
})
export class AppModule {
constructor(private injector: Injector) {
const myComponent = createCustomElement(MyComponent, {
injector
});
customElements.define('my-component', myComponent);
}
ngDoBootstrap() {}
}
When we build our app, we need to copy the output into a public folder in our AngularJS codebase.
To build the elements file:
ng build --prod --project=my-component
This will produce output similar to:
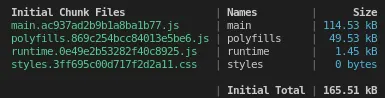
Notice that it created 4 files: 3 JavaScript files and one CSS file. They contain hashes to allow for cache-busting. However, it would also be worth bundling these together and naming them related to the component.
We can do this with a simple node.js script (concat-elements-bundle.js):
const fs = require('fs');
const pathToComponent = './dist/my-component';
const javascriptFiles = fs.readdirSync(pathToComponent).filter(file => file.endsWith(".js"));
let fileData;
for(const file of javascriptFiles) {
fileData += fs.readFileSync(`${pathToComponent}/${file}`);
}
const hash = Date.now();
fs.writeFileSync(`./dist/my-component/my-component.bundle.${hash}.js`, fileData)
We can run this on the command line using node:
node concat-elements-bundle.js
This will output something similar to:
my-component.bundle.1610106946217.js
We then need to copy this to a scripts folder in our AngularJS and include it using a script tag in our index.html file:
<script type="text/javascript" src="app/scripts/my-component.bundle.1610106946217.js"></script>
We can then use our component anywhere in our AngularJS app:
<div ng-controller="MyCtrl as ctrl">
<my-component></my-component>
</div>
This approach allows us to incrementally upgrade components to Angular, using Angular's modern tooling without changing our existing app's set up much. Once all components are upgraded, we have to place the components together in an Angular app, completing the migration.
With a good CI Pipeline we _could _ automate the bundling and inclusion of the Angular Element in the AngularJS app, requiring even less work as the migration moves forward.
Best Practice for Upgrading
No matter the approach taken, one thing remains consistent between the two of them: how we tackle the migration.
Consider our application to be a tree of components. The closer to the root of the tree, the more complex and usually more coupled the components are. As we move down the nodes in the tree, the components should get simpler and be coupled with fewer components.
These components, the lowest hanging fruits, are ideal candidates for migrating to Angular first. We can migrate these components then use them in the AngularJS app where appropriate.
Let's say we have an AngularJS TodoList Component which uses an AngularJS Todo Component.
At this point, we can't really migrate the TodoList Component to Angular as we would have a dependency on the AngularJS Todo Component.
We can migrate the Todo Component to Angular first and use it in the TodoList Component. This makes it easier to migrate the TodoList Component as its dependency on the Todo Component is already an Angular Component.
We can use this approach when migrating legacy codebases. Start from the bottom and work our way up, and I would say this is the best approach.
Conclusion
With AngularJS losing support at the end of this year, it's worthwhile looking at migrating any legacy AngularJS codebases as soon as possible and figuring out a plan to do so.
Hopefully, this article has illustrated the different options available for you to do this and helped provide an approach to tackling migrating the components in your codebase.




