
How to host a full-stack JavaScript app with AWS CloudFront and Elastic Beanstalk
Let's imagine that you have finished building your app. You have a Single Page Application (SPA) with a NestJS back-end. You are ready to launch, but what if your app is a hit, and you need to be prepared to serve thousands of users? You might need to scale your API horizontally, which means that to serve traffic, you need to have more instances running behind a load balancer. Serving your front-end using a CDN will also be helpful.
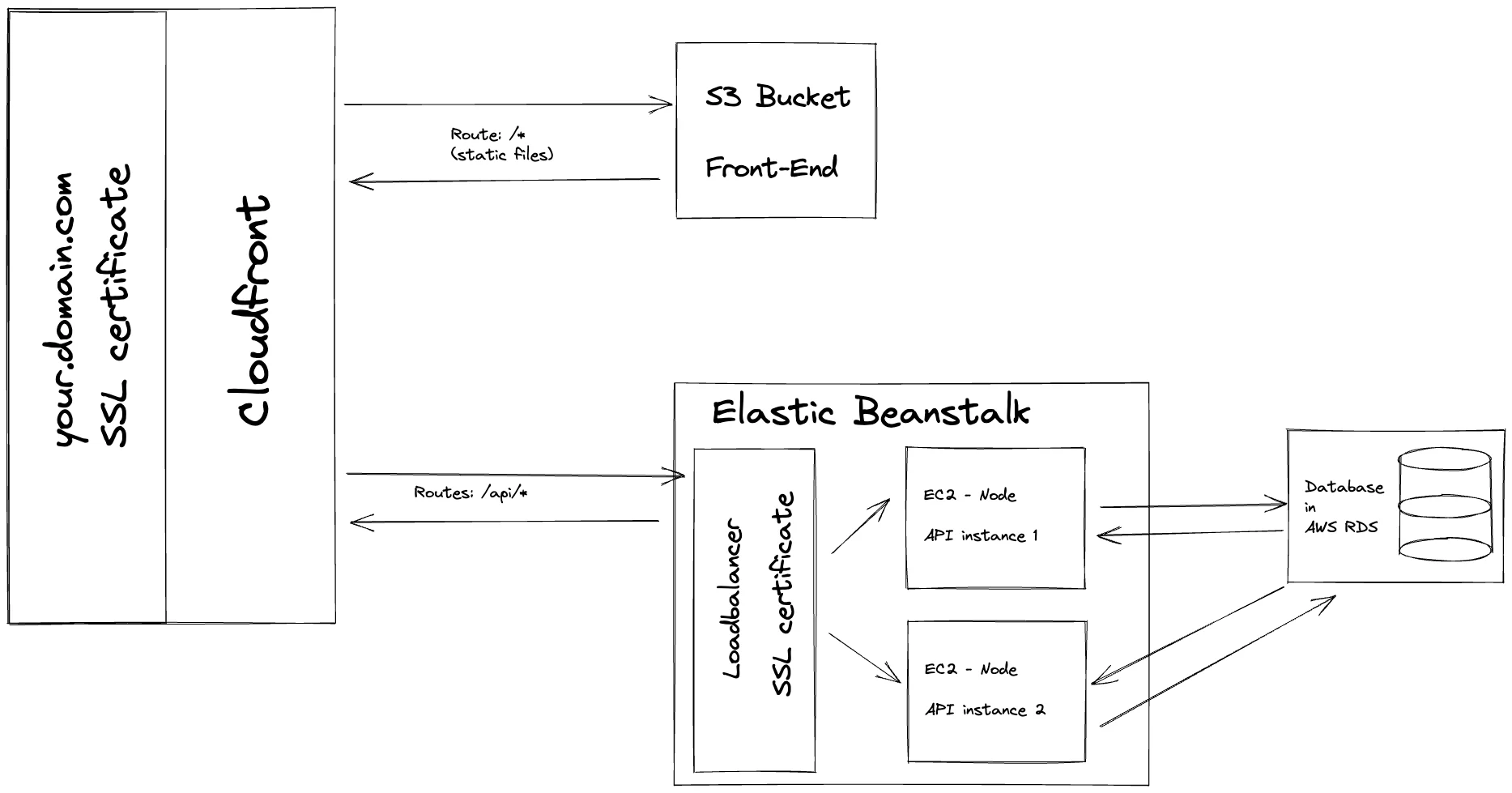
In this article, I am going to give you steps on how to set up a scalable distribution in AWS, using S3, CloudFront and Elastic Beanstalk. The NestJS API and the simple front-end are both inside an NX monorepo
The sample application
For the sake of this tutorial, we have put together a very simple HTML page that tries to reach an API endpoint and a very basic API written in NestJS.
The UI
The UI code is very simple. There is a "HELLO" button on the UI which when clicked, tries to reach out to the /api/hello endpoint. If there is a response with status code 2xx, it puts an h1 tag with the response contents into the div with the id result. If it errors out, it puts an error message into the same div.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Frontend</title>
<base href="/" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<link rel="icon" type="image/x-icon" href="favicon.ico" />
</head>
<body>
<button id="hello">HELLO</button>
<div id="result"></div>
<script>
const helloButton = document.getElementById('hello');
const resultDiv = document.getElementById('result');
helloButton.addEventListener('click', async () => {
const request = await fetch('/api/hello');
if (request.ok) {
const response = await request.text();
console.log(json);
resultDiv.innerHTML = ``;
} else {
resultDiv.innerHTML = ``;
}
});
</script>
</body>
</html>
The API
We bootstrap the NestJS app to have the api prefix before every endpoint call.
// main.ts
import { Logger } from '@nestjs/common';
import { NestFactory } from '@nestjs/core';
import { AppModule } from './app/app.module';
async function bootstrap() {
const app = await NestFactory.create(AppModule);
const globalPrefix = 'api';
app.setGlobalPrefix(globalPrefix);
const port = process.env.PORT || 3000;
await app.listen(port);
Logger.log(`🚀 Application is running on: http://localhost:${port}/${globalPrefix}`);
}
bootstrap();
We bootstrap it with the AppModule which only has the AppController in it.
// app.module.ts
import { Module } from '@nestjs/common';
import { AppController } from './app.controller';
@Module({
imports: [],
controllers: [AppController],
})
export class AppModule {}
And the AppController sets up two very basic endpoints. We set up a health check on the /api route and our hello endpoint on the /api/hello route.
import { Controller, Get } from '@nestjs/common';
@Controller()
export class AppController {
@Get()
health() {
return 'OK';
}
@Get('hello')
hello() {
return 'Hello';
}
}
Hosting the front-end with S3 and CloudFront
To serve the front-end through a CMS, we should first create an S3 bucket. Go to S3 in your AWS account and create a new bucket. Name your new bucket to something meaningful. For example, if this is going to be your production deployment I recommend having -prod in the name so you will be able to see at a glance, that this bucket contains your production front-end and nothing should get deleted accidentally.
We go with the defaults for this bucket setting it to the us-east-1 region. Let's set up the bucket to block all public access, beca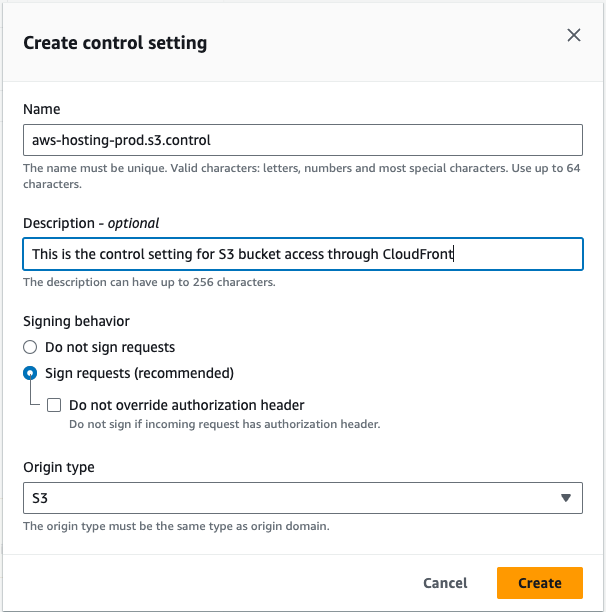 use we are going to allow get requests through CloudFront to these files. We don't need bucket versioning enabled, because these files will be deleted every time a new front-end version will be uploaded to this bucket. If we were to enable bucket versioning, old front-end files would be marked as deleted and kept, increasing the storage costs in the long run. Let's use server-side encryption with Amazon S3-managed keys and create the bucket.
use we are going to allow get requests through CloudFront to these files. We don't need bucket versioning enabled, because these files will be deleted every time a new front-end version will be uploaded to this bucket. If we were to enable bucket versioning, old front-end files would be marked as deleted and kept, increasing the storage costs in the long run. Let's use server-side encryption with Amazon S3-managed keys and create the bucket.
When the bucket is created, upload the front-end files to the bucket and let's go to the CloudFront service and create a distribution.
As the origin domain, choose your S3 bucket. Feel free to change the name for the origin. For Origin access, choose the Origin access control settings (recommended). Create a new Control setting with the defaults. I recommend adding a description to describe this control setting.
At the Web Application Firewall (WAF) settings we would recommend enabling security protections, although it has cost implications. For this tutorial, we chose not to enable WAF for this CloudFront distribution.
In the Settings section, please choose the Price class that best fits you. If you have a domain and an SSL certificate you can set those up for this distribution, but you can do that later as well. As the Default root object, please provide index.html and create the distribution.

When you have created the distribution, you should see a warning at the top of the page. Copy the policy and go to your S3 bucket's Permissions tab. Edit the Bucket policy and paste the policy you just copied, then save it.
If you have set up a domain with your CloudFront distribution, you can open that domain and you should be able to see our front-end deployed. If you didn't set up a domain the Details section of your CloudFront distribution contains your distribution domain name.

If you click on the "Hello" button on your deployed front-end, it should not be able to reach the /api/hello endpoint and should display an error message on the page.
Hosting the API in Elastic Beanstalk
Elastic beanstalk prerequisites
For our NestJS API to run in Elastic Beanstalk, we need some additional setup. Inside the apps/api/src folder, let's create a Procfile with the contents: web: node main.js. Then open the apps/api/project.json and under the build configuration, extend the production build setup with the following (I only )
{
"targets": {
"build": {
"configurations": {
"development": {},
"production": {
"generatePackageJson": true,
"assets": [
"apps/api/src/assets",
"apps/api/src/Procfile"
]
}
}
}
}
}
The above settings will make sure that when we build the API with a production configuration, it will generate a package.json and a package-lock.json near the output file main.js.
To have a production-ready API, we set up a script in the package.json file of the repository. Running this will create a dist/apps/api and a dist/apps/frontend folder with the necessary files.
{
"scripts": {
"build:prod": "nx run-many --target=build --projects api,frontend --configuration=production"
}
}
After running the script, zip the production-ready api folder so we can upload it to Elastic Beanstalk later.
zip -r -j dist/apps/api.zip dist/apps/api
Creating the Elastic Beanstalk Environment
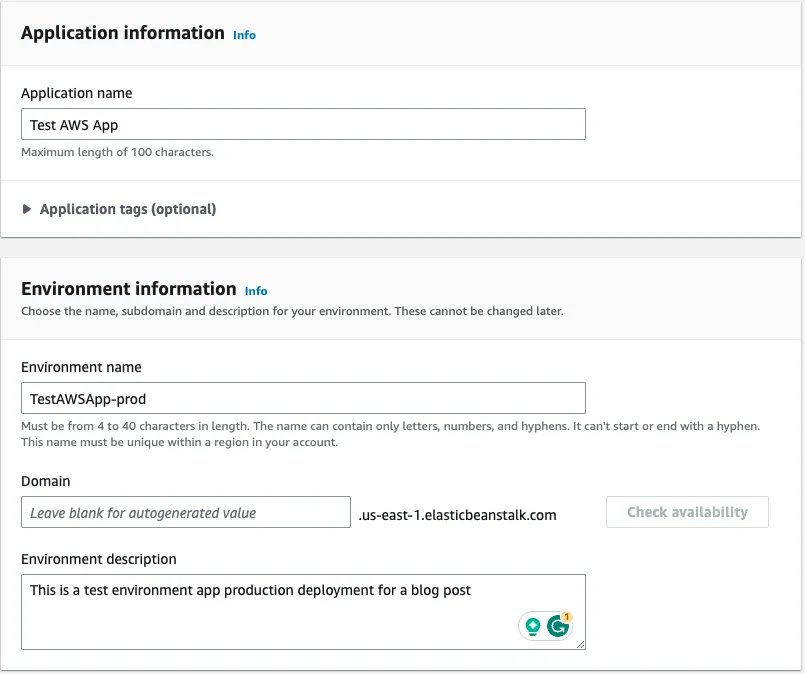
Let's open the Elastic Beanstalk service in the AWS console. And create an application. An application is a logical grouping of several environments. We usually put our development, staging and production environments under the same application name. The first time you are going to create an application you will need to create an environment as well.
We are creating a Web server environment. Provide your application's name in the Application information section. You could also provide some unique tags for your convenience. In the Environment information section please provide information on your environment. Leave the Domain field blank for an autogenerated value.
When setting up the platform, we are going to use the Managed Node.js platform with version 18 and with the latest platform version.

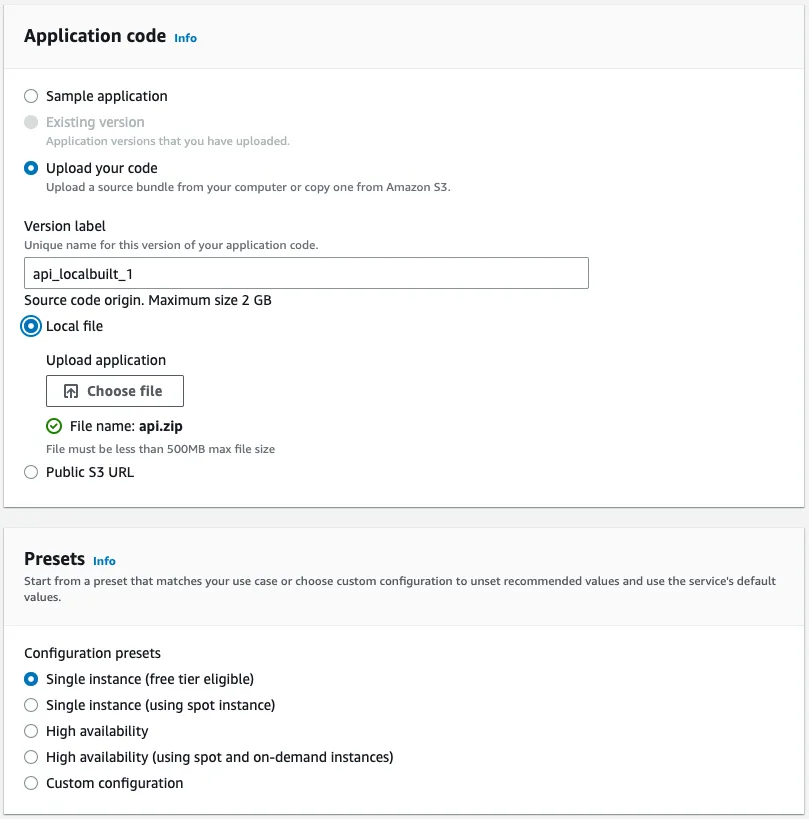
Let's upload our application code, and name the version to indicate that it was built locally. This version label will be displayed on the running environment and when we set up automatic deployments we can validate if the build was successful. As a Preset, let's choose Single instance (free tier eligible)
On the next screen configure your service access. For this tutorial, we only create a new service-role. You must select the aws-elasticbeanstalk-ec2-role for the EC2 instance profile.

If can't select this role, you should create it in AWS IAM with the AWSElasticBeanstalkWebTier, AWSElasticBeanstalkMulticontainerDocker and the AWSElasticBeanstalkRoleWorkerTier managed permissions.

The next step is to set up the VPC. For this tutorial, I chose the default VPC that is already present with my AWS account, but you can create your own VPC and customise it. In the Instance settings section, we want our API to have a public IP address, so it can be reached from the internet, and we can route to it from CloudFront. Select all the instance subnets and availability zones you want to have for your APIs.
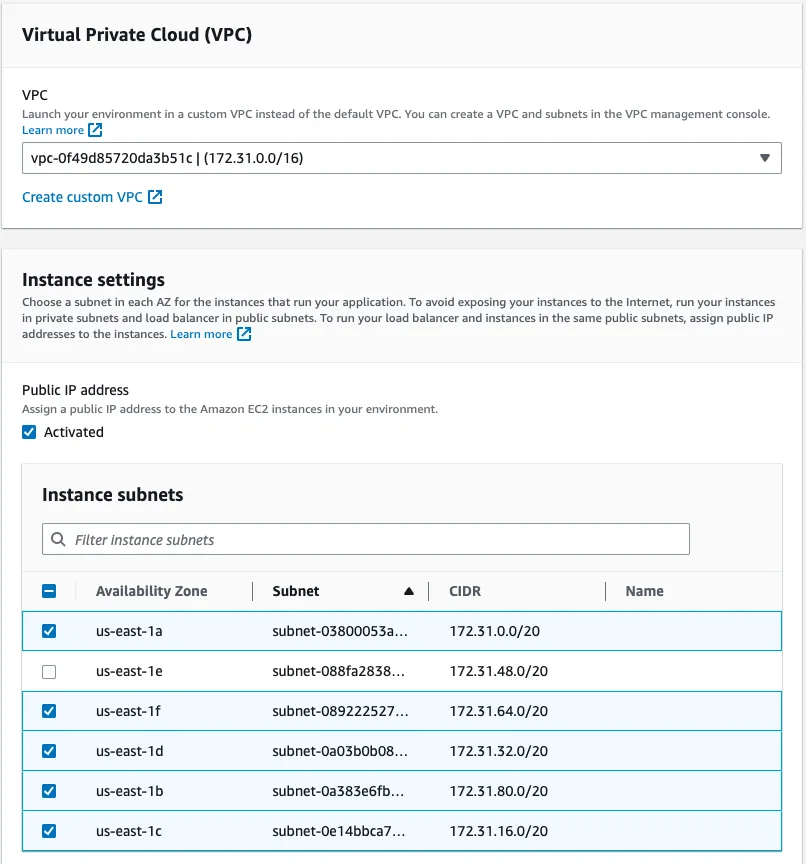
For now, we are not going to set up a database. We can set it up later in AWS RDS but in this tutorial, we would like to focus on setting up the distribution. Let's move forward
Let's configure the instance traffic and scaling. This is where we are going to set up the load balancer. In this tutorial, we are keeping to the defaults, therefore, we add the EC2 instances to the default security group.
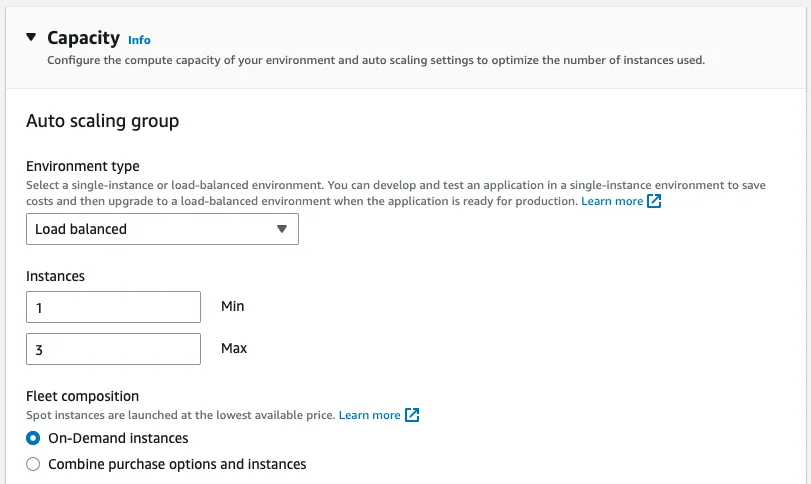
In the Capacity section we set the Environment type to Load balanced. This will bring up a load balancer for this environment. Let's set it up so that if the traffic is large, AWS can spin up two other instances for us. Please select your preferred tier in the instance types section, We only set this to t3.micro For this tutorial, but you might need to use larger tiers.
Configure the Scaling triggers to your needs, we are going to leave them as defaults. Set the load balancer's visibility to the public and use the same subnets that you have used before.
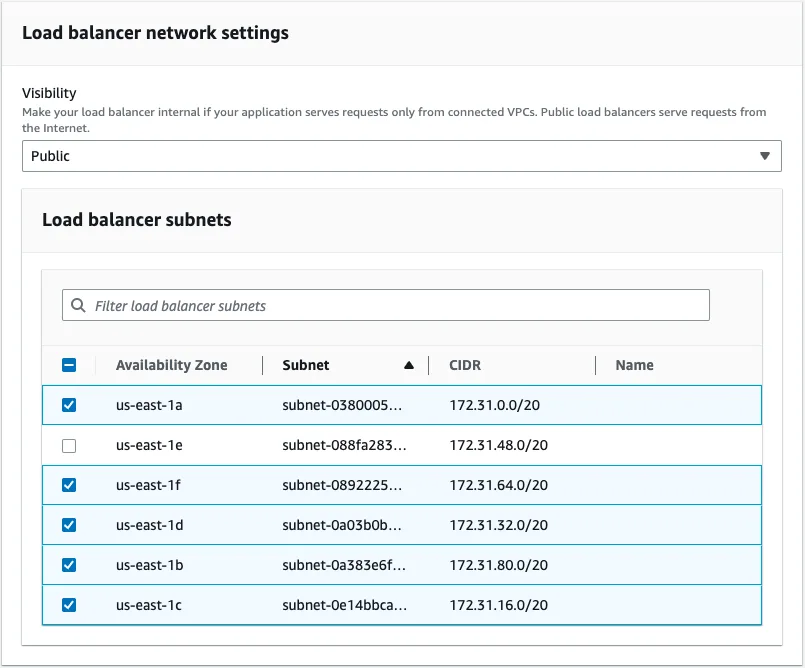
At the Load Balancer Type section, choose Application load balancer and select Dedicated for exactly this environment. Let's set up the listeners, to support HTTPS.
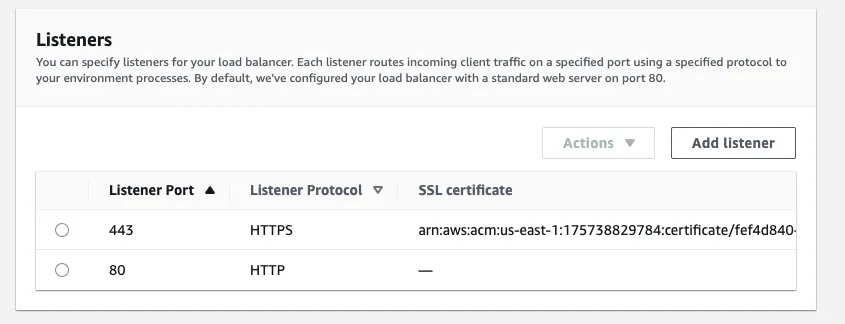
Add a new listener for the 443 port and connect your SSL certificate that you have set up in CloudFront as well. For the SSL policy choose something that is over TLS 1.2 and connect this port to the default process.
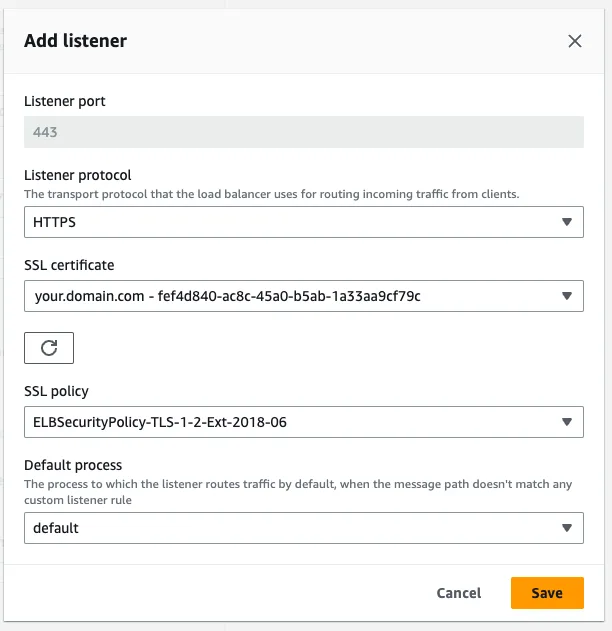
Now let's update the default process and set up the health check endpoint. We set up our API to have the health check endpoint at the /api route. Let's modify the default process accordingly and set its port to 8080.
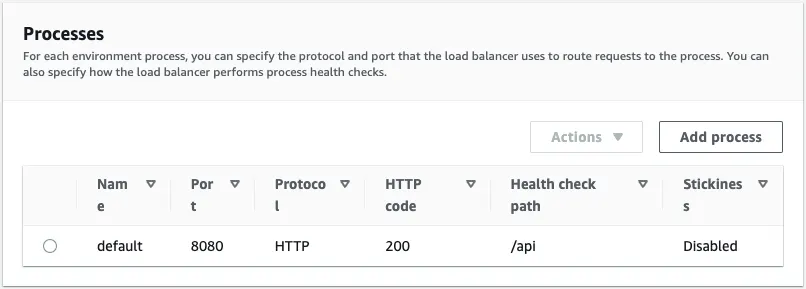
For this tutorial, we decided not to enable log file access, but if you need it, please set it up with a separate S3 bucket.
At the last step of configuring your Elastic Beanstalk environment, please set up Monitoring, CloudWatch logs and Managed platform updates to your needs. For the sake of this tutorial, we have turned most of these options off. Set up e-mail notifications to your dedicated alert e-mail and select how you would like to do your application deployments.
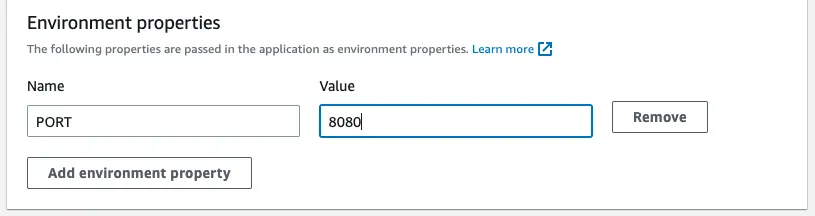
At the end, let's configure the Environment properties. We have set the default process to occupy port 8080, therefore, we need to set up the PORT environment variable to 8080.
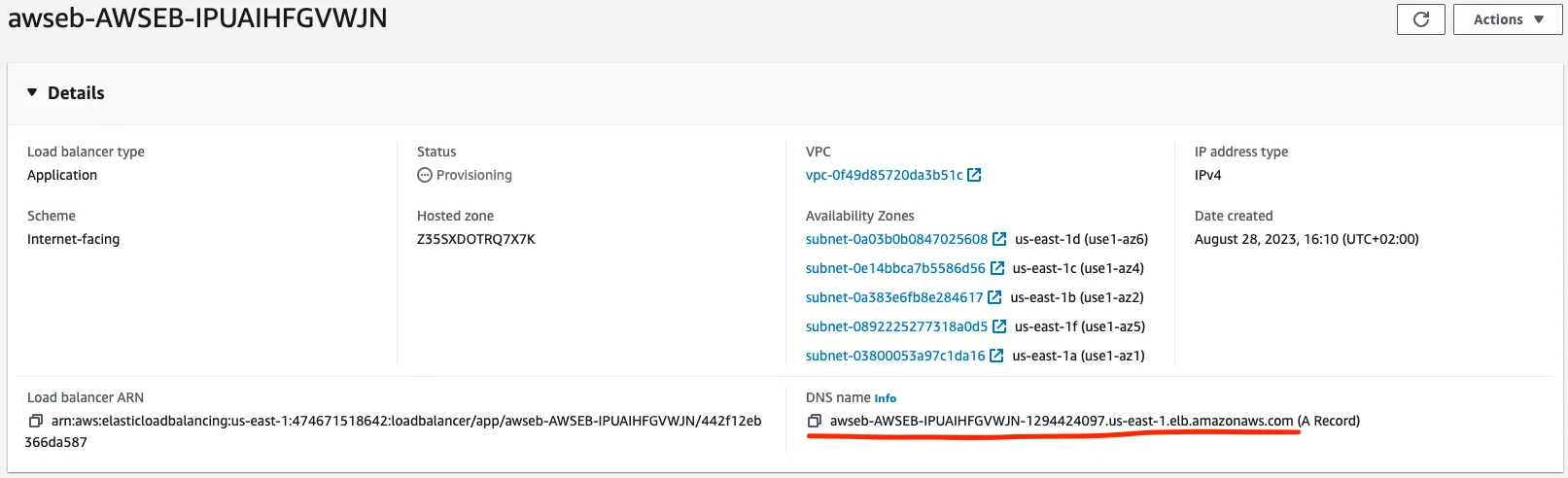
Review your configuration and then create your environment. It might take a few minutes to set everything up. After the environment's health transitions to OK you can go to AWS EC2 / Load balancers in your web console. If you select the freshly created load balancer, you can copy the DNS name and test if it works by appending /api/hello at the end of it.
Connect CloudFront to the API endpoint
Let's go back to our CloudFront distribution and select the Origins tab, then create a new origin. Copy your load balancer's URL into the Origin domain field and select HTTPS only protocol if you have set up your SSL certificate previously. If you don't have an SSL certificate set up, you might use HTTP only, but please know that it is not secure and it is especially not recommended in production. We also renamed this origin to API. Leave everything else as default and create a new origin.
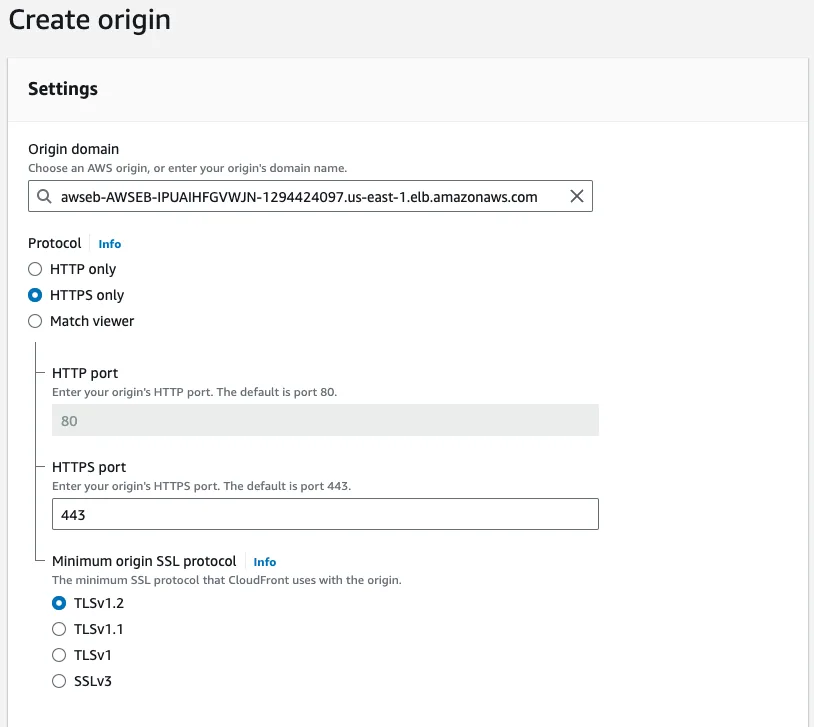
Under the Behaviors tab, create a new behavior. Set up the path pattern as /api/* and select your newly created API origin. At the Viewer protocol policy select Redirect HTTP to HTTPS and allow all HTTP methods (GET, HEAD, OPTIONS, PUT, POST, PATCH, DELETE). For this tutorial, we have left everything else as default, but please select the Cache Policy and Origin request policy that suits you the best.

Now if you visit your deployment, when you click on the HELLO button, it should no longer attach an error message to the DOM.
Now we have a distribution that serves the front-end static files through CloudFront, leveraging caching and CDN, and we have our API behind a load balancer that can scale. But how do we deploy our front-end and back-end automatically when a release is merged to our main branch? For that we are going to leverage AWS CodeBuild and CodePipeline, but in the next blog post. Stay tuned.




