If you’ve ever wanted to learn SvelteKit, now is the time! In this article we will cover the basics of Svelte and SvelteKit and also learn how to build a simple counter app.
This article is a summary of the JS Marathon training by Nacho Falk on Svelte. Read the article, or watch along!
What is SvelteKit
SvelteKit is a Vite-powered framework for building Svelte applications. It enables users to take advantage of filesystem-based routing, and build a variety of applications including server-side rendered, static site generated, or single page applications.
But before we start with SvelteKit, let’s brush up on our Svelte.
What is Svelte?
Svelte is a front end, open-source JavaScript framework for building fast interactive web applications.
Unique Features of Svelte
- Build time compilation, delivers less js code to the server
- No virtual DOM, requires direct and specific modification to browser DOM
- Simple reactivity, easier to modify and maintain application state
- Scoped CSS, no css leaking between components
A Svelte Component
A Svelte component is written into a .svelte file using a superset of HTML syntax.
Each .svelte file holds a component, which is a reusable self-contained block of code that encapsulates HTML, CSS, and JavaScript or Typescript.
Svelte Component code example
<!-- evelutaed once -->
<script context="module">
/**
* can be imported as
* import { text } from filename.svelt
*/
export const text = 'hello'
</script>
<script>
let foo = 1
</script>
<h1>Template 1</h1>
<p>{foo}</p>
<style>
h1 {
color: blue;
}
</style>
The 4 sections in a .svelte file
Module
This section contains codes and other information about the .svelte component. With the module, you can export functions to other components. The default export for a .svelte file is the component itself. Anything exported from the module section is independent of the component.
The ComponentScript
This contains the script and logic of the component itself. This can be JavaScript or TypeScript code. If you want to specify the desired syntax, the script code can look like this:
// typescript
<script lang="ts">
let foo: number = 1
</script>
// javascript
<script lang="js">
let foo = 1
</script>
Template This section contains the HTML template code for the component.
Style This section contains the stylesheet code for the component UI.
Props
To define a prop of the component, you will declare a variable in the script section like the example code below.
<script lang="ts">
import Child from './child.svelte'
let foo: number = 1
let prop1 = 1,
prop2 = 2,
obj = {
prop1,
prop2
};
</script>
<h1>Template 1</h1>
<p>{foo}</p>
<Child prop1={prop1} prop2={prop2} />
<Child {prop1} {prop2} />
<Child {...obj} />
Declared props can be passed to a child component through assignment, short-hand assignment, or by destructing it like the code shown above.
Handling Events
To declare an event, import the createEventDispatcher provided by Svelte, and attach the on directives to the events like on:click.
Example
<script lang="ts">
import { createEventDispatcher } from "svelte";
let dispatch = createEventDispatcher();
</script>
<button on:click={(e) => dispatch('foo', {foo: 'bar'})}>Button 1</button>
But you can also declare and handle events in Svelte using other methods, like:
<!-- handle on click event -->
<button on:click={(e) => console.log(e)}>Button Log</button>
<!-- event modifiers -->
<button on:click|preventDefault={(e) => console.log(e)}>Button Prevent</button>
<!-- bubble event to be used by the consumer of this component -->
<button on:click>Button 1</button>
Slots Svelte
- Slots can be used to create components that accept and render any children.
- Slots are created in Svelte by using
<slot>inside components that can accept either components or markup.
Building a Counter Application with Svelte Kit
Now that we understand the basics, let’s get into building a Counter App with SvelteKit that Nacho taught us during the JS Marathon training.
To create a SvelteKit app, run:
npm init svelte
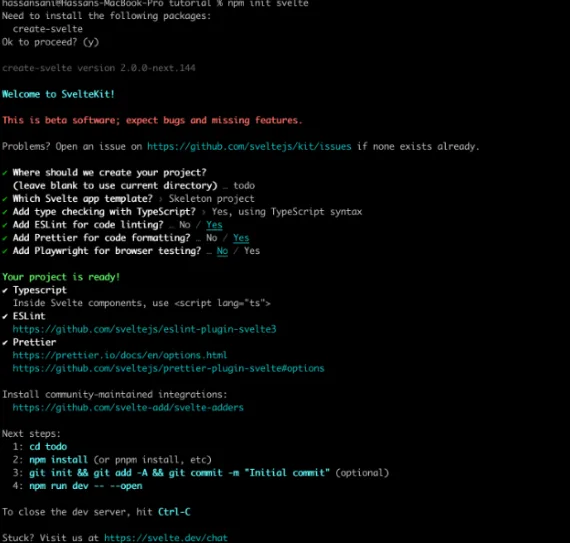
The CLI will prompt you with some questions:
Where should we create your project?
(leave blank to use current directory) … todo
Type the name of the directory you want to use, or leave blank if you will be using the current directory. Follow the prompt to choose.
Then run…
npm install
…to install dependencies for the application.
To test the application, run:
npm run dev
This will render the application on the http://localhost:3000/.

Open the directory with your code editor:
Modify src/routes/index.svelte file and replace it with the following
<script context="module" lang="ts">
export const prerender = true;
</script>
<section>
<h1>
<div class="welcome">
<picture>
<source srcset="svelte-welcome.webp" type="image/webp" />
<img src="svelte-welcome.png" alt="Welcome" />
</picture>
</div>
to your new<br />SvelteKit app
</h1>
<h2>
try editing <strong>src/routes/index.svelte</strong>
</h2>
</section>
<style>
section {
display: flex;
flex-direction: column;
justify-content: center;
align-items: center;
flex: 1;
}
h1 {
width: 100%;
}
.welcome {
position: relative;
width: 100%;
height: 0;
padding: 0 0 calc(100% * 495 / 2048) 0;
}
.welcome img {
position: absolute;
width: 100%;
height: 100%;
top: 0;
display: block;
}
</style>
Now, create a new file src/routes/__layout.svelte with the following, just adding the design:
<script lang="ts">
import '../app.css';
</script>
<svelte:head>
<title>Home</title>
<meta name="description" content="Svelte demo app" />
</svelte:head>
<main>
<slot />
</main>
<style>
main {
flex: 1;
display: flex;
flex-direction: column;
padding: 1rem;
width: 100%;
max-width: 1024px;
margin: 0 auto;
box-sizing: border-box;
}
footer {
display: flex;
flex-direction: column;
justify-content: center;
align-items: center;
padding: 40px;
}
footer a {
font-weight: bold;
}
@media (min-width: 480px) {
footer {
padding: 40px 0;
}
}
</style>
Counter Component
In this part, we start creating various components for the to-dos, beginning with the Counter component. Create the src/components/Counter.svelte file with the following:
<script lang="ts">
import { spring } from 'svelte/motion';
let count = 0;
const displayed_count = spring();
$: displayed_count.set(count);
$: offset = modulo($displayed_count, 1);
function modulo(n: number, m: number) {
// handle negative numbers
return ((n % m) + m) % m;
}
</script>
<div class="counter">
<button on:click={() => (count -= 1)} aria-label="Decrease the counter by one">
<svg aria-hidden="true" viewBox="0 0 1 1">
<path d="M0,0.5 L1,0.5" />
</svg>
</button>
<div class="counter-viewport">
<div class="counter-digits" style="transform: translate(0, {100 * offset}%)">
<strong class="hidden" aria-hidden="true">{Math.floor($displayed_count + 1)}</strong>
<strong>{Math.floor($displayed_count)}</strong>
</div>
</div>
<button on:click={() => (count += 1)} aria-label="Increase the counter by one">
<svg aria-hidden="true" viewBox="0 0 1 1">
<path d="M0,0.5 L1,0.5 M0.5,0 L0.5,1" />
</svg>
</button>
</div>
<style>
.counter {
display: flex;
border-top: 1px solid rgba(0, 0, 0, 0.1);
border-bottom: 1px solid rgba(0, 0, 0, 0.1);
margin: 1rem 0;
}
.counter button {
width: 2em;
padding: 0;
display: flex;
align-items: center;
justify-content: center;
border: 0;
background-color: transparent;
touch-action: manipulation;
color: var(--text-color);
font-size: 2rem;
}
.counter button:hover {
background-color: var(--secondary-color);
}
svg {
width: 25%;
height: 25%;
}
path {
vector-effect: non-scaling-stroke;
stroke-width: 2px;
stroke: var(--text-color);
}
.counter-viewport {
width: 8em;
height: 4em;
overflow: hidden;
text-align: center;
position: relative;
}
.counter-viewport strong {
position: absolute;
display: flex;
width: 100%;
height: 100%;
font-weight: 400;
color: var(--accent-color);
font-size: 4rem;
align-items: center;
justify-content: center;
}
.counter-digits {
position: absolute;
width: 100%;
height: 100%;
}
.hidden {
top: -100%;
user-select: none;
}
</style>
What are we doing in the Counter component? We imported the spring function from svelte/motion since we will be working with a click event that will be changing the counter value frequently. The spring function will help with animation.
Next, we declared a count variable with an initial value of 0 then we declared a displayed_count function as the name suggests to display the counts as the click event is fired and we assigned an instance of the spring() function to it.
Then, we assigned the Svelte Reactive statement to the displayed_count to run the function whenever the count variable changes. Then, we declared the offset variable and assigned an instance of a modulo function to handle negative digits.
For the template, we attached on:click events for decreasing and increasing the $displayed_count variable.
Now head over to the index.svelte component to import the Counter component.
<script context="module" lang="ts">
export const prerender = true;
</script>
// Start import here
<script lang="ts">
import Counter from '../components/Counter.svelte';
</script>
<svelte:head>
<title>Home</title>
<meta name="description" content="Svelte demo app" />
</svelte:head>
<section>
<h1>
<div class="welcome">
<picture>
<source srcset="svelte-welcome.webp" type="image/webp" />
<img src="svelte-welcome.png" alt="Welcome" />
</picture>
</div>
to your new<br />SvelteKit app
</h1>
<h2>
try editing <strong>src/routes/index.svelte</strong>
</h2>
<!-- Add the Counter component here -->
<Counter />
</section>
Before we test the application, let's add an about page and a header to the application.
Create about.svelte file. The name for the route must correspond to the route name. To learn more about SveltKit Routing, check out the docs.
About Component
For the about route add the following:
<svelte:head>
<title>About</title>
<meta name="description" content="About this app" />
</svelte:head>
<div class="content">
<h1>About this app</h1>
<p>
This is a <a href="https://kit.svelte.dev">SvelteKit</a> app. You can make your own by typing the
following into your command line and following the prompts:
</p>
<pre>npm init svelte</pre>
<p>
The page you're looking at is purely static HTML, with no client-side interactivity needed.
Because of that, we don't need to load any JavaScript. Try viewing the page's source, or opening
the devtools network panel and reloading.
</p>
</div>
<style>
.content {
width: 100%;
max-width: var(--column-width);
margin: var(--column-margin-top) auto 0 auto;
}
</style>
The about component is purely static HTML.
Header Component
Create Header.svelte file and add the following
<script lang="ts">
import { page } from '$app/stores';
</script>
<header>
<nav>
<svg viewBox="0 0 2 3" aria-hidden="true">
<path d="M0,0 L1,2 C1.5,3 1.5,3 2,3 L2,0 Z" />
</svg>
<ul>
<li class:active={$page.url.pathname === '/'}><a sveltekit:prefetch href="/">Home</a></li>
<li class:active={$page.url.pathname === '/about'}>
<a sveltekit:prefetch href="/about">About</a>
</li>
</ul>
<svg viewBox="0 0 2 3" aria-hidden="true">
<path d="M0,0 L0,3 C0.5,3 0.5,3 1,2 L2,0 Z" />
</svg>
</nav>
</header>
<style>
header {
display: flex;
justify-content: space-around;
}
nav {
display: flex;
justify-content: center;
--background: rgba(255, 255, 255, 0.7);
}
svg {
width: 2em;
height: 3em;
display: block;
}
path {
fill: var(--background);
}
ul {
position: relative;
padding: 0;
margin: 0;
height: 3em;
display: flex;
justify-content: center;
align-items: center;
list-style: none;
background: var(--background);
background-size: contain;
}
li {
position: relative;
height: 100%;
}
li.active::before {
--size: 6px;
content: '';
width: 0;
height: 0;
position: absolute;
top: 0;
left: calc(50% - var(--size));
border: var(--size) solid transparent;
border-top: var(--size) solid var(--accent-color);
}
nav a {
display: flex;
height: 100%;
align-items: center;
padding: 0 1em;
color: var(--heading-color);
font-weight: 700;
font-size: 0.8rem;
text-transform: uppercase;
letter-spacing: 0.1em;
text-decoration: none;
transition: color 0.2s linear;
}
a:hover {
color: var(--accent-color);
}
</style>
Import Header component into __layout.svelte file, modify the code:
<script lang="ts">
// Import Header component here
import Header from '../components/Header.svelte';
import '../app.css';
</script>
<!-- Add the Header component -->
<Header />
<main>
<slot />
</main>
<footer>
<p>visit <a href="https://kit.svelte.dev">kit.svelte.dev</a> to learn SvelteKit</p>
</footer>
<style>
main {
flex: 1;
display: flex;
flex-direction: column;
padding: 1rem;
width: 100%;
max-width: 1024px;
margin: 0 auto;
box-sizing: border-box;
}
footer {
display: flex;
flex-direction: column;
justify-content: center;
align-items: center;
padding: 40px;
}
footer a {
font-weight: bold;
}
@media (min-width: 480px) {
footer {
padding: 40px 0;
}
}
</style>
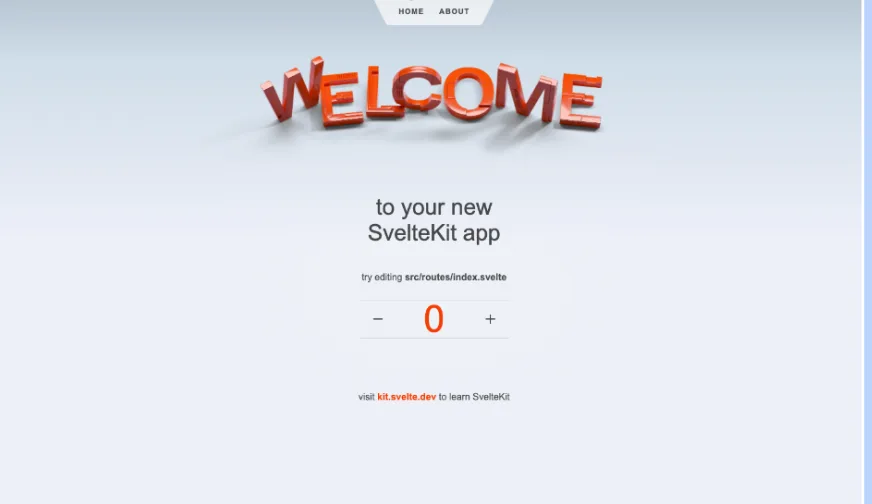
Run the application to see the final result
Conclusion
Hopefully you learned a little about SvelteKit and were able to follow along and build a simple app!
If you want a live demo on how to build an app using Svelte and SvelteKit, I suggest watching the full video of the JS Marathon training on YouTube
Here is the GitHub repository for the complete project, which you can clone.




