Recently we published an article about a pragmatic approach to using Git in teams. It outlines a strategy which is easy to implement while safeguarding against common issues when using git. It is, however, in my opinion, a compromise. Allowing some issues with edge cases as a trade-off for ease of use.
Status Quo
Before jumping into another strategy, let us establish the pros and cons of what we’re up against. This will give us a reference for determining whether we did better, or not.
Pro: Squash Merging
One of the stronger arguments is the squash merge. It offers freedom to all developers within the team to develop as they see fit. One might prefer to develop all at the same time, and push a big commit in the end. Others might like to play it safe and simply commit every 5 minutes, allowing them to roll back or backup changes.
The only rule is that at the end of the work, all changes get squashed into a single commit that has to adhere to the team's standards.
Con: You Get A Single Commit
Each piece of work gets a single commit. To circumvent this, one could create multiple PRs and break-up the work into bite-size chunks. This is, undeniably, a good practice. But it can be cumbersome and distributive when trying to keep pace.
In addition, you put the team at risk of getting git conflicts. Say you’re in the middle of building your feature and uncover a bug which requires fixing. As a good scout, you implement the fix and create a separate PR to deliver the fix to the team. At the same time, you keep the fix in your branch as you need it for your feature. At the point of squashing, your newly squashed commit conflicts with the stand-alone fix you’ve delivered to your team. This is nothing that git can’t fix, but it is a nuisance nonetheless.
Con: Review Potential
A good PR shouldn’t have too many changes, making it easy to review. In the real world however, things get messy. Commits can give us some insight into how the complete changeset came to be. This requires the team to write well-curated commits though. This conflicts with the strength we’re getting from allowing freedom to commit as one sees fit.
The History Rewriting Controversy
It is good to know that what I’m about to suggest is considered blasphemy by many. Rewriting history is not without its dangers. Changes can go missing, and others who have based their work on now-changed history need to deal with conflicts. However, when applied prudently, rewriting history can yield benefits as well.
In this context, some advanced git knowledge is required.
The Alternative
There was a soft hint towards using conventional commits in Dustin’s article. Let's go ahead and fully endorse adopting it. The convention is simple enough, and the documentation is exhaustive.
Now I hear you think, “but we just concluded that allowing us to commit as we like was a good thing”. And you are not wrong. This is where history rewriting comes into play. As you’re working, commit as you like. Then, when it’s time to put your changes up for review, start editing your branch to ensure each change is nicely wrapped and documented in a proper commit.
Finally, after getting a thumbs-up on the PR, rebase your changes on top of the branch you’re merging into, and finally do a normal merge. Most git hosting services offer this workflow for you.
While I endorse rewriting history in your own branch, restrain from altering shared branches like “main” or “develop”. By sticking to this small rule, you’ve already negated most disadvantages of rewriting history.
Shared Changes
If we look back at our scenario where both the main and our feature branch include a fix, we get to the same point where we want to merge. However in this case, given that you’ve made the same commit in both branches, git is clever enough to fix the flow of history and remove the fix from your new changes.
The following flow...
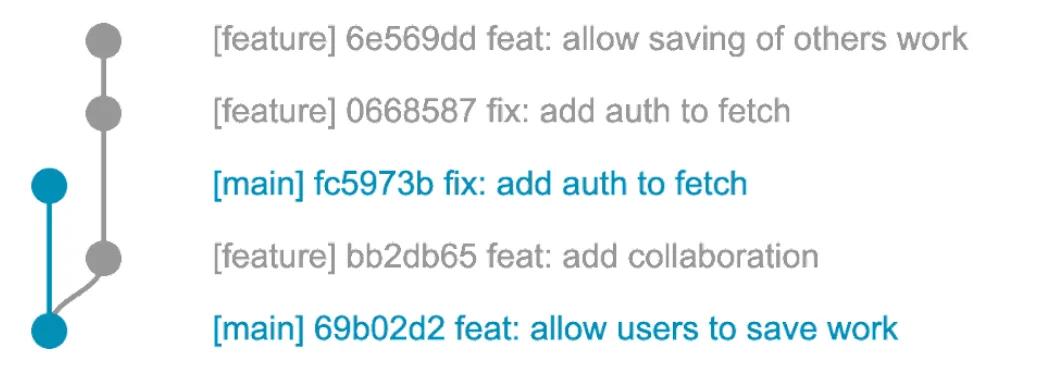
... will look like this after merging:

Fixes On Your Own Features
Although this is part of the conventional commit strategy, I feel it deserves some special attention. If you have introduced a new feature in your branch, and committed the changes. It can happen that you introduced a bug. Your first intuition might be to create a “fix” commit. Instead, consider going back to your feature commit and amending the fix to it.
This has two advantages. First of all, the history will be less cluttered. Looking back at what changed, it's easy to see which features got introduced and what bugs we found along the way.
On top of that, it will prevent confusion for your reviewers. Now, the code presented to others is fixed code. At no time in its history does it ever contain the bug. Your co-workers are not going to have any comments on it.
How To Rewrite Your Branch
Now we know why to clean-up, let's look at strategies to actually do the orchestration. The most obvious route is to keep the changeset you want to present in mind. Doing so, one prevents having to go back and rewrite everything from scratch. As an added bonus, I’ve found that it helps me better separate concerns.
Complete Wipe
If you like making periodic commits (or some other strategy that results in you creating arbitrary commits) chances are you are going to completely wipe all commits (not the changes) in your branch. The simplest way to accomplish this is by doing a soft reset to where you forked from the main branch.
This can be achieved by rebasing and resetting to main (given main is where you want to merge into). This is a good approach as you also prepare your branch for being merged back.
git rebase main
git reset main
This can also be accomplished by counting the amount of commits and making that amount of steps back from HEAD. For example, if you have made 4 commits in your branch.
git reset HEAD~4
And lastly, you can do this by knowing where you started off. One can find this by looking at the logs:
git reset 6a5c8e8f2b
Using either of these methods will leave you with no commits in your branch, and all your changes in your workspace. From this point, you can start cherry-picking your changes, and making well-curated commits.
Interactive Rebase
If you already have somewhat of a structure, interactive rebasing might be a better solution for you. This will allow you to go over each commit, and decide on how to alter them. The most interesting options being:
s, squash - this will add the changes from this commit to its parent, followed by allowing you to change the commit message, and thus appending the message with the squashed changes.
e, edit - using this option, the rebase will stop right before the commit gets added to the branch as if you went back in time and just did the development work. From this point, you can add files, split the commit in multiple different commits, change the commit message, or do whatever you’d like to do.
d, drop - in the rare occasion you simply don’t want this commit anymore.
r, reword - like edit, but you’re only offered the option to change the commit message.
To start an interactive rebase, simply run
git rebase -i main
Conclusion
By embracing history rewriting and dropping squash merging. A team could produce an even cleaner git history. This option might not be for everyone, as it requires a little work and git knowledge. But if done well, it will circumvent some of the drawbacks of our pragmatic approach.




