
Our databases are growing.
Not only in size, but in data variance and complexity.
Increasing numbers of development teams will need to look for new tools to give them the ability to improve communication between their Client and API teams, and be able to more quickly move their concepts from the development stage to the marketplace.
GraphQL is one of these tools which we expect to see used with increasing frequency across the industry. This query language allows consumers to be pickier about the types of data needed from their APIs in order to fulfill their requests by providing more understandable descriptions about that data.
For some, there may be a question of why one would use GraphQL over REST. But before we dive into this, it is important to remember that the most expensive, resource-intensive, and time-consuming part of client-to-API communication comes from the HTTP request and response process. That’s why even small advantages in performance and functionality matter so much when comparing these communication tools.
THE STRUCTURE OF A GRAPHQL QUERY
To start, the following image demonstrates the structure of a GraphQL query:
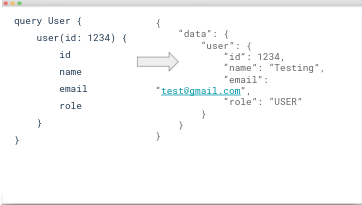
This is an example of a query that is retrieving a single User record with the given id. On the left, you’ll see the query where we define the name, any inputs, and a list of the fields we would like returned. On the right, you’ll see the JSON response body returned, containing a node with our query and the data retrieved.
REST PITFALLS: UNDER AND OVER-FETCHING
GraphQL improves performance by optimizing data retrieval. With REST, one of the problems is under-fetching: or not getting enough data. This, as a result, requires the client to make multiple calls to the API layer to get what it needs. Just take a look at this juxtaposition:
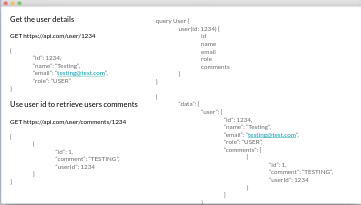
On the left, we have a traditional REST endpoint that returns a user’s details. Once we retrieve the user’s details, we make another call with the user id value to get a list of the user’s comments. We’ve now made two roundtrips to the API to return the data set our client needs.
With GraphQL, however, you are able to request the full data set needed, which eliminates these round trip request. On the right, we have a GraphQL query that requests the comments in the initial query. This returns our user details, as well as the comments, in the same request/response roundtrip cycle. In this instance, using GraphQL increases our client side efficiency by two fold!
Under-fetching is not the only potential pitfall that accompanies REST. The architecture also has a propensity to over-fetch, or return too much data, in some instances as well. Unfortunately, REST does not provide an out-of-the-box way for us to only retrieve data from a request that we need. This can lead to our clients having to consume, and parse, or handle too much data. With GraphQL, you can specify only the fields you need to retrieve without returning superfluous data, thereby decreasing our payload size.
Suppose we want to request a list of users to view in a table. Our user object can be very large, and contain a lot of different fields and props that we know about the user- information like their comments, posts, when they were created and last updated, etc. But do we actually need this data if we are viewing a simple list of users?
Probably not.
Let’s visualize it:
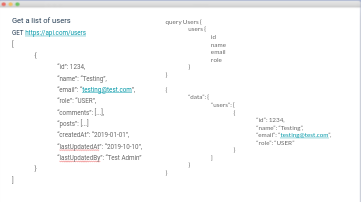
On the left, we have our REST endpoint to retrieve a list of users, and the JSON response it retrieves, which contains all of the props we know about the user- even props we do not need to display. By using REST, our request time is longer, and contains more data to parse in the response by our client. When the client is responsible for extracting out all of this unnecessary data, our users pay the price for this through slower response and render times.
On the right, we have a GraphQL query to get a list of users, and we only specify the user props we need. No comments, posts, etc. Just the lightweight response data to display our list of users!
But the pitfalls still don’t stop there!
REST PITFALLS: ERROR HANDLING
Traditionally in REST, when an error occurs while processing the request, the entirety of the request fails. Let’s call this the All or Nothing approach.
This approach provides a very poor user experience. The client only knows that the error occurred, but does not have any data that could have been potentially retrieved before the error occurred.
We will look at an example of how REST handles an error:
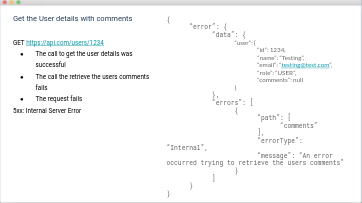
On the left, we have a REST endpoint, where we are retrieving user details with comments. Though we were able to successfully retrieve the user’s details when we made the call to get their comments, an error occurred, and it tanked our response, returning only a 500: Internal Server Error and no other information.
GraphQL allows for a better user experience because it will return the data that it was able to successfully retrieve, AND any errors that occurred while trying to retrieve that data. This allows us to also responsibly handle errors, and provide the end user with as much information as we have. You can see this demonstrated on the right, where we have the same request using GraphQL. In this case, because the user’s details were successfully retrieved, we still get access to that data, and can display it to our end-user. We are also, however, informed that an error occurred, what that error is, and what fields were affected.
REST PITFALLS: BATCH SUPPORT
When using REST out-of-the-box, you can only hit one endpoint, and retrieve only one dataset at a time.
GraphQL, on the other hand, comes with the ability to send a batch of queries and mutations to your API to be processed. This supports data-intensive pages like dashboards, where data is retrieved, aggregated, and displayed from, potentially, a multitude of sources. This often causes long load times. Dashboards are very common in web applications since they let you see high-level data about current statuses, and can even change in real-time.
This data can be very useful to better visualise, and understand how your company is doing. But there is a lot of data involved in these dashboards, causing the render and load times to grow as more and more data is added and visualized. GraphQL supports batching queries out-of-the-box, and can come in handy to help alleviate some of this bloat:
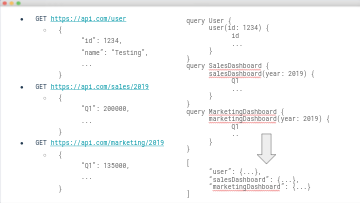
On the left is the traditional REST route used to retrieve this data, through which we make multiple requests to our endpoints to retrieve the data we need. Through this process, each has to go through its own request/response HTTP lifecycle, and be rendered into the component.
On the right, is an example of batch querying achieved in GraphQL. We send a batch of queries we want to run to our API, and the entire data set is retrieved in only one HTTP request response lifecycle. This, again, is one of the reasons why the adoption of GraphQL can be so useful when trying to achieve performance improvements on the client side.
So now that we have established some of the differences in performance between the REST architecture and GraphQL query language, let’s take a closer look at why enterprises are adopting the latter.
WHY ENTERPRISES ARE ADOPTING GRAPHQL
While it would be impossible to list all of the specific advantages of the query languages, especially considering the diverse technical needs of different enterprises, there are at least four clear motivators that are driving companies to incorporate GraphQL in their arsenal of tech tools:
- Ability to Create Separation of Concerns
- Faster Prototyping and Development
- Support of Component Driven Architecture
- Strong Typing System
ABILITY TO CREATE SEPARATION OF CONCERNS
By adopting a GraphQL middleware layer, users are able to create a separation of concerns, allowing the API layer to only concern itself with how to retrieve, and return data, instead of building out multiple endpoints, and structures, to expose the data that the client needs. Specifically, the GraphQL middleware layer exposes one connection for the clients to consume, and centralizes the business logic, as well as common things like request logging and authentication. Because the structure and definition of the data is provided by GraphQL, the Client can also just focus on consuming the data it needs. This should increase API flexibility, and decrease API development time.
Another benefit is that this separation of concerns allows for API teams to ease the migration from monolithic API architectures to a more microservice-based architecture. This is because the GraphQL layer now handles how the Clients get data, and allows these APIs to evolve over time as the business requirements change.
FASTER PROTOTYPING AND DEVELOPMENT
Another advantage of adopting GraphQL is the ability to prototype and develop more quickly. Though there are multiple ways to approach GraphQL adoption, we recommend a schema-first approach.
If you start by defining the data structure, and building your schema- adding queries, and mocking out the data response- then the Client can see the definition of the data as it evolves, and can start developing against it while the API, and data layers, are being built and validated.
While this approach requires adherence from both Client and API sides to agree upon a data-structure while development is occurring, users should expect decreased development cycles, and decreased time to market.
SUPPORT OF COMPONENT DRIVEN ARCHITECTURE
GraphQL is a very natural fit for component driven architectures. When you know the structure and definition of your data, your components can request, and retrieve, only the data with which they need in order to interact. This means that you’re able to create an architecture with smaller, stateless components that can be easily reused and composed in a manner that allows stateful components to better ingest them.
STRONG TYPING SYSTEM
Without GraphQL, components typically need to worry about retrieving superfluous data, and not handling that data intuitively. This can decrease performance, and takes away from the user-experience.
With GraphQL’s inherent strong-typing system, components can be written in a more intuitive, data driven manner, making them less error prone and more resilient. This is because its system forces you to define what fields are required, as well as the types of those fields.
This is not only relevant to instances in which data is being queried, but also in which it is being mutated. Because mutation inputs are also strongly-typed, GraphQL informs the component of what fields will be required, and what the type of the field is. This makes the mutation of your data much easier to build out, validate and understand.
WHY NOW IS THE TIME TO ADOPT
Enterprises are already adopting and taking advantage of GraphQL’s many benefits. A few of the growth and competitive advantages they have seen as a result of this include:
Performance improvement Standards with agnostic implementation capabilities Centralized business logic across multiple clients
PERFORMANCE IMPROVEMENT
Paypal has been a strong advocate for the adoption of GraphQL, specifically after they saw such strong performance improvements. In fact, Mark Stuart, one of the leads at PayPal heading the migration to GraphQL said, “GraphQL is a game changer to the way we think about data, fetch data, and build applications.” He also added, “REST’s principles don’t consider the needs of Web and Mobile apps and their users… you’re often making many round trips from the client to the server to fetch data.”
STANDARDS WITH AGNOSTIC IMPLEMENTATION CAPABILITIES
By rallying around a well-defined set of standards and conventions, like those defined by GraphQL, large organizations are able to decrease the inconsistency that results from disparate development teams, and increase the overall quality, and consistency, of the organization’s code.
GraphQL is also agnostic in its implementation, which makes it flexible enough to allow individual teams and organizations to implement as they see fit.
Responding to a question about why GitHub decided to adopt GraphQL, Senior Platform Engineer Brandon Black said, “GraphQL has a clear value proposition for features it provides, including built-in documentation, static types, and an un-opinionated stance. It gave us a standard on which to build, while remaining agnostic in terms of implementation.”
CENTRALIZED BUSINESS LOGIC ACROSS MULTIPLE CLIENTS
We covered how the centralization of business logic, when adopting a GraphQL middleware layer, is one of the advantages of GraphQL over REST in the section titled, “ABILITY TO CREATE SEPARATION OF CONCERNS”.
Evan Huus, Developer Lead on the API Patterns team at Shopify adds, “At Shopify, we have a web admin interface and our iOS and Android apps... Between the three, there’s a lot of duplication of logic; we have to implement the same business interface and business logic in all three... GraphQL solves this problem for us because the business logic now lives in one place behind the API, so we only have to implement and maintain business logic in one place.”
APPROACH TO ADOPTING GRAPHQL
At This Dot Labs, we recommend adopting a schema-first approach, because again, this helps with cross team collaboration, and allows faster prototyping without reliance on individual teams.
We start doing this by defining our schema, and the data structure that needs to be consumed.
GraphQL defines a language for building schemas called the Schema Definition Language, or SDL. Below, we have an example SDL file where we build out a simple schema:
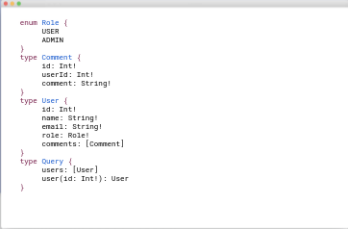
There are a few different options, such as enum, type, input, fragment, etc. These allow us to compose our schema building complex types from these primitive types.
We have an enum called Role, that defines the available Role values that a user can have as a prop.
Then, we build out our complex type Comment, which has an id prop of type integer, userId, and comment. Notice the exclamation marks above. These denote a field as being required. Of course, this does not mean that you have to specify the field in your query. Instead, it means that, if you do, and the field does not return a value, an error will occur.
We use the Role enum and the Comment type to build out User. This shows how easy it is to compose these types together.
UTILIZING THE POWER OF RESOLVERS
Now that we have a schema, we can concern ourselves with how to get data.
The power of GraphQL is found within the resolvers, and being able to utilize them. A resolver retrieves data that is requested. This can be done through whatever means you want, such as a call to your service layer, a call directly to your database or data layer, or even an http call to another service. Not only are resolvers responsible retrieving the data for a query, but they can also be utilized to resolve individual fields in a data type.
This is an example resolver in NodeJs with the NestJs framework, in which we define our User Resolver which will be responsible for retrieving data for our User queries:
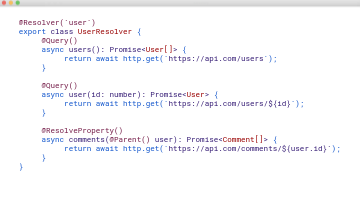
If you remember, from our SDL slide, we define two queries, users and user. These definitions connect those queries with the functionality responsible to retrieve the data. When the users query is requested, we make an http call to https://api.com/users, which retrieves and returns our users list.
In addition, we have this Resolve Property function. This instructs GraphQL to resolve properties via a call to the comments microservice to retrieve data in instances when a user, and comments, are requested in the same query. The resolver then stitches these comments back into the user and returns.
BUILD OUT A GRAPHQL MIDDLEWARE
This Dot also recommends adopting a GraphQL Middleware Layer. This method of adoption makes incremental migration a breeze by allowing you to build out your GraphQL layer, and having your clients incrementally adopt as the types, and layers, are built out.
This diagram is an example of where the GraphQL middleware layer would fit into the architecture of your ecosystem:

Previously, these apps would connect to their own microservices, but now, the GraphQL layer handles that all for you.
MIGRATIONS
Let’s talk a bit more on migrations.
The goal is to allow teams to communicate in order to define, and build out the schema. As this build out is occurring, and the middleware layer is being developed, clients can begin incrementally adopting and utilizing this layer with ease.
This incremental adoption increases productivity and engagement of the engineers. They get to quickly utilize and see the power of GraphQL since it is being continually built out. It also helps to simplify the codebase, since business logic is centralized in this layer, and moved out from the client code.
We also see that, with this approach, teams communicate to help each other better understand how the data is being utilized. They then use this data in collaboration to build the schema, and ultimately, provide the end-user with the best experience possible.
HOW WE CAN HELP YOU
Interested in adding this revolutionary tech tool to your arsenal? Please do not hesitate to reach out to the team at This Dot Labs. Having only been formally released in 2015, GraphQL is a relatively new technology, and so we encourage companies who are interested in harnessing its power to adopt as soon as possible in order to stay ahead of the development curve.
Through consulting, mentorship, training, and/or staff augmentation, This Dot Labs will help your team understand how to get the most out of this query language in order to decrease development times, and increase productivity, making their concepts come to life more quickly and seamlessly.




