Concurrent JavaScript with Promises and Async/Await
Most applications require us to handle logic that responds to events. These could be mouse clicks, time elapsed, or even after a network request. JavaScript is NOT a multi-threaded language, meaning the interpreter will only ever run 1 task at a time ("Run-to-completion").
As a result, JavaScript needs a way to queue up and run tasks, 1 after another. Before ES6, callbacks were the main way this kind of logic was handled.
Callbacks
The Mozilla Developer Network (MDN) has a great definition for what a callback is.
A callback function is a function passed into another function as an argument, which is then invoked inside the outer function to complete some kind of routine or action.
Let's illustrate an example of how to use a callback function to handle a network request. In the example below, we'll query SWAPI using an XMLHttpRequest (a callback-based object), and then render a table of starships after receiving a response.
const starshipsRequest = new XMLHttpRequest()
starshipsRequest.addEventListener('load', function () {
const starshipResponse = JSON.parse(this.response)
console.log(starshipResponse)
const starshipsArray = starshipResponse.results
const starshipsDiv = document.getElementById('starships')
starshipsDiv.innerHTML = `
<table>
<thead>
<tr>
<th>Starship Name</th>
<th>Model</th>
<th>Manufacturer</th>
<th>Cost in Credits</th>
<th>Crew</th>
</tr>
</thead>
<tbody>
${starshipsArray.map(starship => `
<tr>
<td>${starship.name}</td>
<td>${starship.model}</td>
<td>${starship.manufacturer}</td>
<td>${starship.cost_in_credits}</td>
<td>${starship.crew}</td>
</tr>
`).join('')}
</tbody>
</table>
`
})
starshipsRequest.open('GET', 'https://swapi.dev/api/starships/')
starshipsRequest.send()
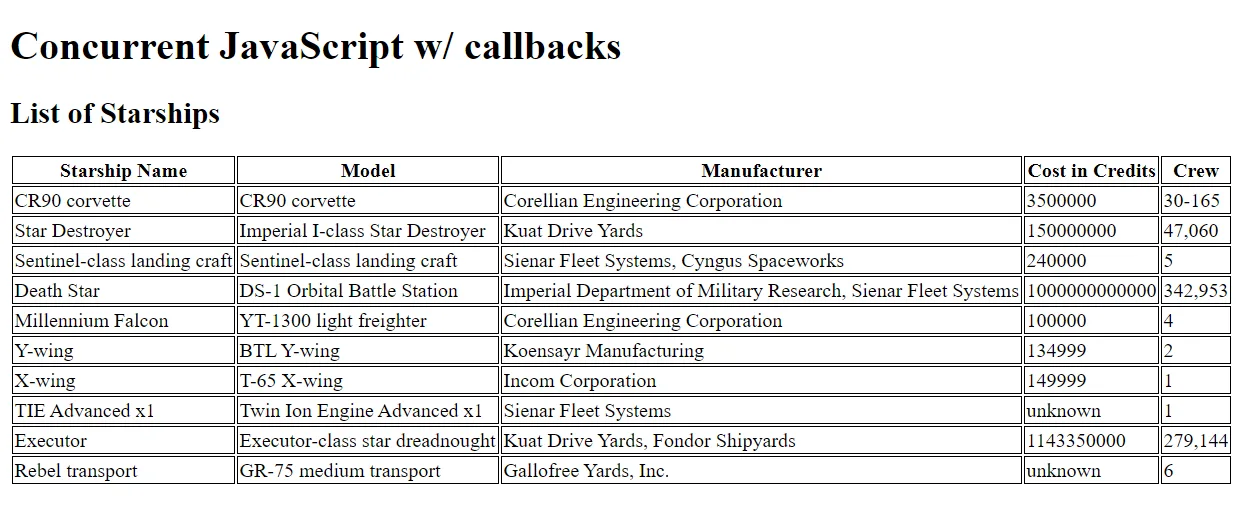
In the above example, we do the following:
- Create a new XMLHttpRequest
- Setup a callback function to be called after a 'load' event is delivered to the new XMLHttpRequest, which renders our starships based on the response.
- Open and send the XMLHttpRequest to SWAPI's 'starship' resource.
Receiving a response from the SWAPI API takes time, so we want to handle that logic asynchronously so as not to block JavaScript's single-threaded event loop. We do so by passing a callback to the XMLHttpRequest object, and having it call our callback when a response is ready.
Let's see what could happen though if we wanted to make things a bit more complicated. Here is what our JSON parsed response looks like for a single one of our starships, a Star Destroyer:
{
"name": "Star Destroyer",
"model": "Imperial I-class Star Destroyer",
"manufacturer": "Kuat Drive Yards",
"cost_in_credits": "150000000",
"length": "1,600",
"max_atmosphering_speed": "975",
"crew": "47,060",
"passengers": "n/a",
"cargo_capacity": "36000000",
"consumables": "2 years",
"hyperdrive_rating": "2.0",
"MGLT": "60",
"starship_class": "Star Destroyer",
"pilots": [],
"films": [
"http://swapi.dev/api/films/1/",
"http://swapi.dev/api/films/2/",
"http://swapi.dev/api/films/3/"
],
"created": "2014-12-10T15:08:19.848000Z",
"edited": "2014-12-20T21:23:49.870000Z",
"url": "http://swapi.dev/api/starships/3/"
}
We could add a feature to our table, and add a comma-delimited list of names of movies that our starships appeared in. To implement this, we would have to deal with the following two issues:
- Nesting more callbacks within our current callback (famously known as "Callback Hell").
- Rendering our data after all of our requests have finished.
There are ways we can write callbacks to mitigate some of the unpleasantness of callback hell, and callbacks can be used while also ensuring logic will run only after a series of asynchronous events. Doing this is painful though, and with the release of JavaScript ES6, Promises have been released to solve these very same problems.
But to appreciate how asynchronous JavaScript has evolved, let's implement this feature, and add a column to our table showing the movies these ships appeared in.
const starshipsRequest = new XMLHttpRequest()
starshipsRequest.addEventListener('load', function () {
const starshipResponse = JSON.parse(this.response)
const starshipsArray = starshipResponse.results
const starshipsDiv = document.getElementById('starships')
starshipsDiv.innerHTML = `
<table>
<thead>
<tr>
<th>Starship Name</th>
<th>Model</th>
<th>Manufacturer</th>
<th>Cost in Credits</th>
<th>Crew</th>
<th>Appeared In</th>
</tr>
</thead>
<tbody>
${starshipsArray.map(starship => `
<tr>
<td>${starship.name}</td>
<td>${starship.model}</td>
<td>${starship.manufacturer}</td>
<td>${starship.cost_in_credits}</td>
<td>${starship.crew}</td>
<td data-movies=${JSON.stringify(starship.films)} class="appearedIn"></td>
</tr>
`).join('')}
</tbody>
</table>
`
const appearedInArray = document.querySelectorAll('.appearedIn')
appearedInArray.forEach(starshipTD => {
const movieURLs = JSON.parse(starshipTD.dataset.movies)
const movieNames = []
let movieNamesCompletedRequests = 0
for (let i = 0; i < movieURLs.length; i++) {
const movieNameRequest = new XMLHttpRequest()
movieNameRequest.addEventListener('load', function() {
const movieNameResponse = JSON.parse(this.response)
movieNames.push(movieNameResponse.title)
movieNamesCompletedRequests++
if (movieNamesCompletedRequests === movieURLs.length) {
starshipTD.innerHTML = movieNames.join()
}
})
movieNameRequest.open('GET', movieURLs[i])
movieNameRequest.send()
}
})
})
starshipsRequest.open('GET', 'https://swapi.dev/api/starships/')
starshipsRequest.send()
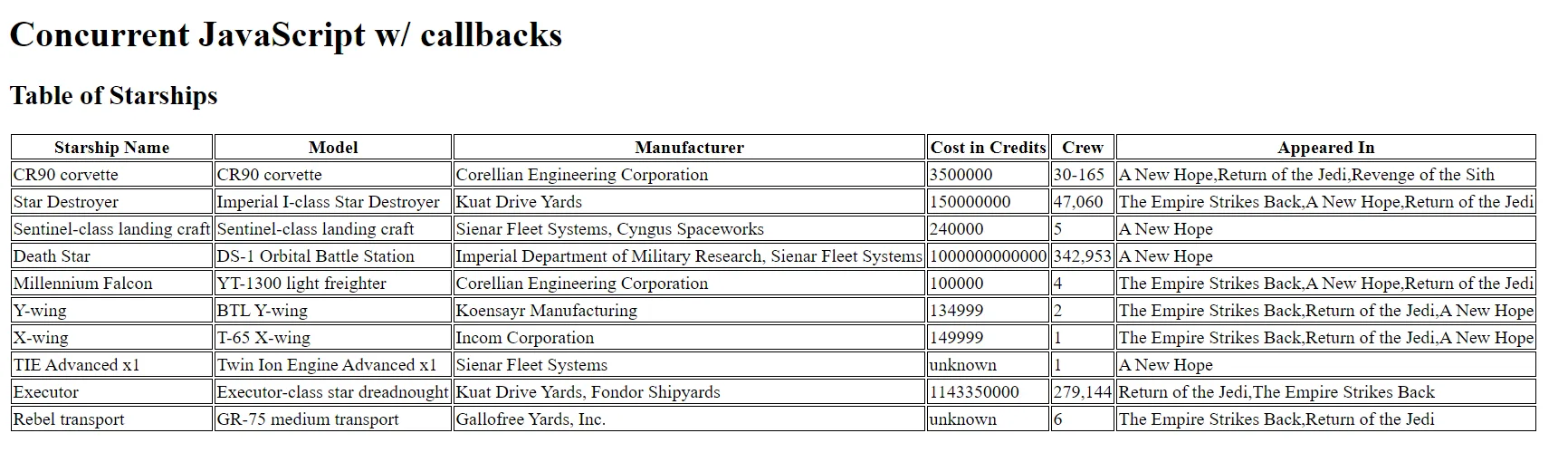
To implement this feature, we added logic that does the following:
- Create
<td>elements with no inner content, and with a movies data attribute, containing an array of URLs to query movie names from. - After rendering the table, loop through each of the empty
<td>elements with the movies data attribute.- Parse
<td>movie data attribute. - Loop over each movie in the parsed movie array, sending a network request to get the name of each movie.
- If all movie names have been retrieved, set the innerHTML of the
<td>to a comma-delimited list of movie names.
- Parse
Pain points here, in the execution of this logic, were keeping track of the total number of handled network requests for each starship, along with the further nesting of callback functions. Let's do it better with Promises.
Promises
MDN, once again, does a great job defining what a Promise is.
The Promise object represents the eventual completion (or failure) of an asynchronous operation, and its resulting value.
Introduced in ES6, Promises are another step up on the evolution chain of asynchronous JavaScript. Let's refactor our starship example to use the Fetch API, a promise-based API for handling network requests.
fetch('https://swapi.dev/api/starships/')
.then(starshipsResponse => starshipsResponse.json())
.then(starshipsData => {
const starshipsArray = starshipsData.results
const starshipsDiv = document.getElementById('starships')
starshipsDiv.innerHTML = `
<table>
<thead>
<tr>
<th>Starship Name</th>
<th>Model</th>
<th>Manufacturer</th>
<th>Cost in Credits</th>
<th>Crew</th>
<th>Appeared In</th>
</tr>
</thead>
<tbody>
${starshipsArray.map(starship => `
<tr>
<td>${starship.name}</td>
<td>${starship.model}</td>
<td>${starship.manufacturer}</td>
<td>${starship.cost_in_credits}</td>
<td>${starship.crew}</td>
<td data-movies=${JSON.stringify(starship.films)} class="appearedIn"></td>
</tr>
`).join('')}
</tbody>
</table>
`
const appearedInTDArray = document.querySelectorAll('.appearedIn')
appearedInTDArray.forEach(starshipTD => {
const movieURLs = JSON.parse(starshipTD.dataset.movies)
const movieNamePromises = movieURLs
.map(movieURL => fetch(movieURL).then(res => res.json()).then(movieData => movieData.title))
Promise.all(movieNamePromises)
.then(movieNames => {
starshipTD.innerHTML = movieNames.join()
})
})
})
We've avoided the worst of callback hell simply because we haven't needed to nest requests too much at all with this example. But Promises have saved us a bunch of logic when it came to resolving multiple fetch requests.
The star of the code in the above example is Promise.all(). Instead of manually keeping track of completed requests, and performing an asynchronous action, once we've determined all requests have been completed, Promise.all() does this for us, resolving all of our promises, and only setting our innerHTML once all promises have been resolved. Super helpful.
We can take this a step further though by using the next step in JavaScript's asynchronous evolution, async/await.
Async/Await
Async/Await was introduced in ES8 as a way to write asynchronous code, that reads like synchronous code. Here is an MDN article about those keywords.
Let's refactor our example one final time, using Async-Await.
(async () => {
const starshipsResponse = await fetch('https://swapi.dev/api/starships/')
const starshipsData = await starshipsResponse.json()
const starshipsArray = starshipsData.results
const starshipsDiv = document.getElementById('starships')
starshipsDiv.innerHTML = `
<table>
<thead>
<tr>
<th>Starship Name</th>
<th>Model</th>
<th>Manufacturer</th>
<th>Cost in Credits</th>
<th>Crew</th>
<th>Appeared In</th>
</tr>
</thead>
<tbody>
${starshipsArray.map(starship => `
<tr>
<td>${starship.name}</td>
<td>${starship.model}</td>
<td>${starship.manufacturer}</td>
<td>${starship.cost_in_credits}</td>
<td>${starship.crew}</td>
<td data-movies=${JSON.stringify(starship.films)} class="appearedIn"></td>
</tr>
`).join('')}
</tbody>
</table>
`
const appearedInTDArray = document.querySelectorAll('.appearedIn')
appearedInTDArray.forEach(async starshipTD => {
const movieURLs = JSON.parse(starshipTD.dataset.movies)
const movieNamePromises = movieURLs
.map(movieURL => fetch(movieURL).then(res => res.json()).then(movieData => movieData.title))
const movieNames = await Promise.all(movieNamePromises)
starshipTD.innerHTML = movieNames.join()
})
})()
Here, we've wrapped our logic in an async IIFE, which allows the use of the await keyword. await pauses the execution of the function, waiting until we resolve the value of our promises, resulting in synchronous looking code. This is much easier to read and reason about.
If you want to check out a deployed version of this code, here is a link to the StackBlitz deployment, and here is a link to the source code.
Conclusion
JavaScript is an evolving language, and as a result, handling asynchronous behavior has been growing with the language. We described 3 ways to handle networks requests asynchronously, using:
- Callbacks: Pre-ES6
- Promises: ES6 solution
- Async/Await: ES8 syntactic sugar over promises
I've loved the developer experience offered by promises, and as a result, I always lean on the Fetch API over XMLHttpRequest's when it comes to handling network requests. Promises, especially with async/await, just offer such a better experience writing async logic.
There is so much more to learn when it comes to working with async JavaScript, such as the details of the event loop, and differences between the micro and macro task queues, but this should give a good high-level overview of your asynchronous options when it comes to writing your logic.
Happy coding!




