TypeScript is a language that supercharges your JavaScript by giving your application's source codes type-checking. Combining the compiler tool and the IDE plug-ins gives a beautiful development experience when building JavaScript applications.
What I love most about using TypeScript is that when I use it, I know exactly the structure of data to give to components and when I give a different structure, the IntelliSense immediately notifies me.
Also, as a friend said:
If you use TypeScript in your application (without doing "illegal" kinds of stuff like passing
anyeverywhere), you'll never have an uncaught error of "xasundefined"
This view is opinionated, but I quite agree with it.
Using TypeScript with React makes building React components faster with little to no uncaught errors. It allows you to specify the exact structure of expected props for any component.
In this article, we'll learn how to use TypeScript to compose React components. To continue with this article, a fair knowledge of TypeScript is required. This is a great starting guide to learn TypeScript.
At the end, we'll also look at the difference between prop-types and TypeScript.
Let's start building components
In this article, we'll build four components: an Input, a Button, a Header, and a BlogCard component. These components will show how TypeScript can be used with React.
Setting up TypeScript for React
Some React frameworks (like NextJS and GatsbyJS) already have support for TypeScript out of the box, but for Create React App, you have a few things you'll need to do.
If it's a new project, you can create the project like so:
create-react-app project-name --template typescript
The --template typescript installs dependencies that add support for TypeScript in your React application.
If it's an existing project, then you would need to install the Typescript dependencies:
npm install --save typescript @types/node @types/react @types/react-dom
With these, you can rename .js files to .tsx to allow TypeScript codes.
Now, let's build our components.
An Input component
For our Input component, we need the following props: defaultValue, onChange, placeholder and name. Each of them is a string value except onChange, which is a function.
Using TypeScript, here's how we define the component:
// Input.tsx
import React from "react";
type Props = {
onChange: (str: string) => void;
placeholder: string;
name: string;
value?: string;
};
function Input({ onChange, name, placeholder, value = "" }: Props) {
return (
<input
onChange={event => onChange(event.target.value)}
name={name}
placeholder={placeholder}
value={value}
/>
);
}
export default Input;
This way, our component is well defined. The expected onChange method must accept only one argument which must be a string. placeholder, name and value (if provided) must be a string. If a different data type is passed, the IntelliSense immediately yells, or the compile command on the terminal breaks.
And here's how this component is used:
// Form.tsx
import React, { useState } from "react";
import Input from "./Input";
function Form() {
const [nameInput, setNameInput] = useState("");
const onChange = (str: string) => {
setNameInput(str);
};
return (
<form>
<Input
onChange={onChange}
name="name"
placeholder="Enter your name"
value={nameInput}
/>
</form>
);
}
export default Form;
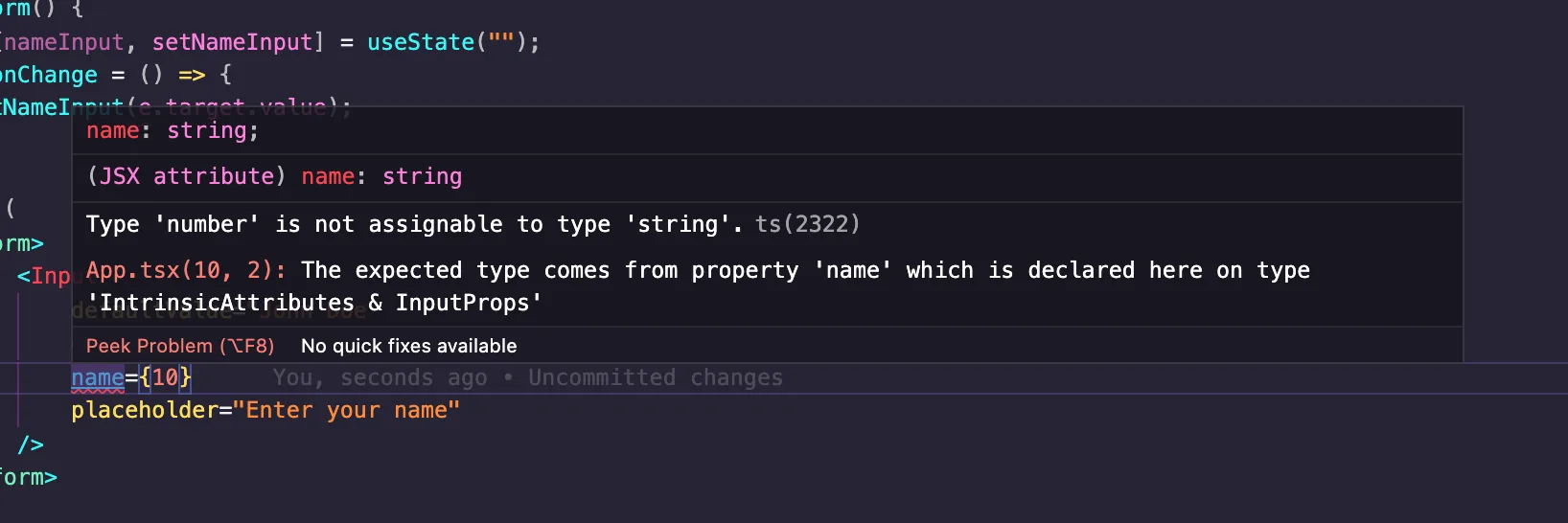
Let's change the data type of the placeholder property to see the warning we get:
...
<form>
<Input
...
name={10}
/>
</form>
...
Here's the warning:
A Button component
Our Button component will have the following props: value and processing like so:
// Button.tsx
type Props = {
value: "Submit" | "Continue" | "Update";
processing: boolean;
};
function Button({ value, processing }: Props) {
return <button>{processing ? "Processing" : value}</button>;
}
For the value prop, we're expecting either of three strings: "Submit", "Continue", or "Update", and the processing expects a true or false value.
Let's see the component in use:
// Form.tsx
import React, { useState } from "react";
import Input from "./Input";
import Button from "./Button";
function Form() {
const [nameInput, setNameInput] = useState("");
const onChange = (str: string) => {
setNameInput(str);
};
return (
<form>
<Input
onChange={onChange}
name="name"
placeholder="Enter your name"
value={nameInput}
/>
<Button value='Submit' processing={false} />
<Button value='Submit' processing={true} />
</form>
);
}
export default Form;
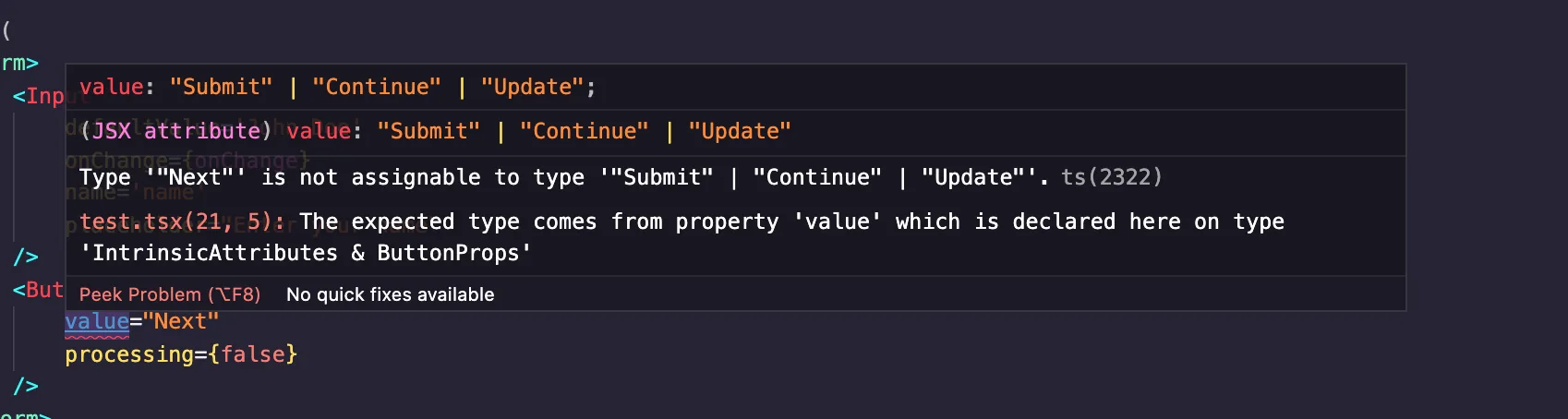
As you'd notice, "Next" is not included in the expected strings for value. Therefore, we get an error from IntelliSense. Here are two things you'd notice on your IDE:
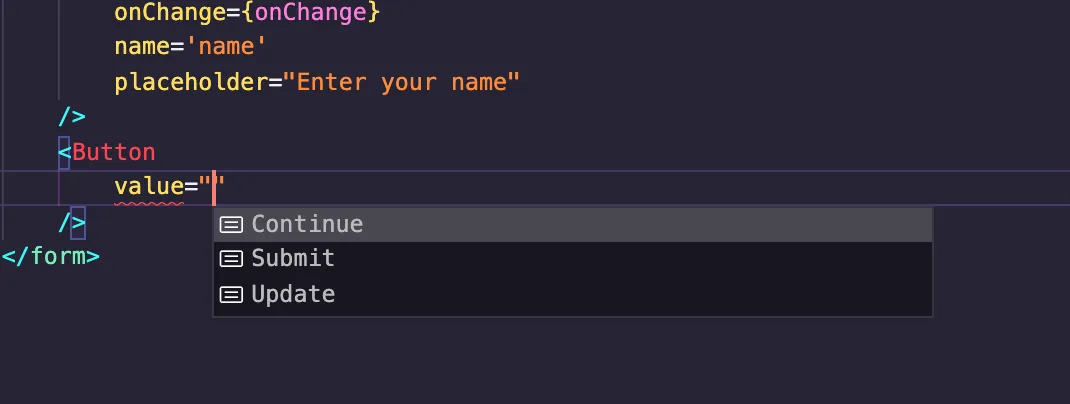
As seen above, on entering quotes, the IDE already gives you the acceptable values. But if you pass "Next", you'll get this:
A Header component
So our Header component would be a bit complex. For an authenticated user, the header would have the user's name, but if otherwise, we have the "Sign in" text. Here's how we'll define it:
// Header.tsx
import React from "react";
type User = {
name: string;
};
type Props =
| {
authenticated: false;
profile: null;
}
| {
authenticated: true;
profile: User;
};
function Header(props: Props) {
return (
<header>
<a href="/">Home</a>
<a href="/about">About</a>
{props.authenticated ? props.profile.name : <a href="/signin">Sign in</a>}
</header>
);
}
export default Header;
The Header component accepts two props: authenticated and profile. The props are conditional such that when props.authenticated is false, props.profile is null and when props.authenticated is true, props.profile is the User type.
This means, if a user is authenticated, a profile object must also be provided.
Here's how the component is used:
import Header from "./Header";
function Layout() {
return (
<div>
<Header authenticated={true} profile={null} />
</div>
);
}
For the above, we do something unacceptable. authenticated is true, but a different data type for profile is provided. Here's what the IntelliSense gives:
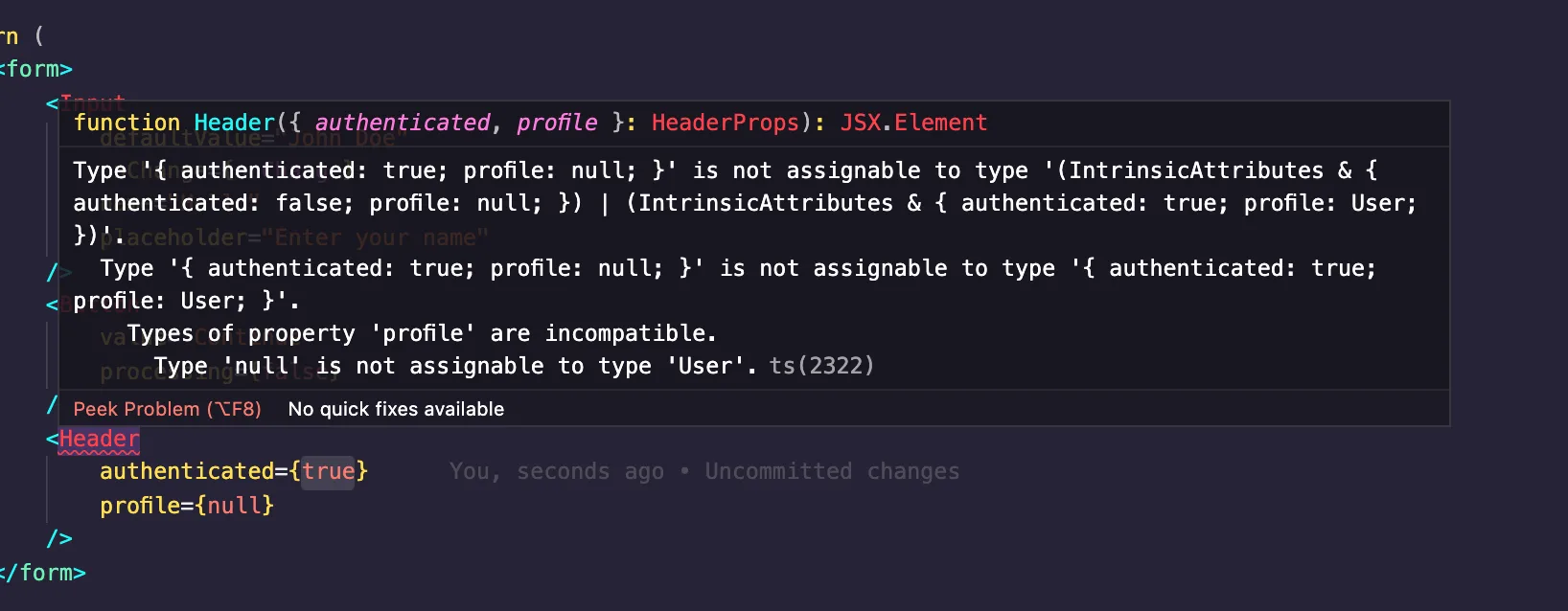
A BlogCard component
In this component, we expect a post prop which is an object with the following properties: title, author, date and timeToRead. Here's how we define it with TypeScript:
// BlogCard.tsx
import React from "react";
type Props = {
post: {
title: string;
author: {
name: string;
};
date: Date;
timeToRead: number;
};
};
function BlogCard({ post }: Props) {
return (
<div className="blog-card">
<span className="title">{post.title}</span>
<span className="date">
on {new Intl.DateTimeFormat().format(post.date)}
</span>
<span className="time-to-read">{post.timeToRead}mins</span>
<span className="author-name">By {post.author.name}</span>
</div>
);
}
export default BlogCard;
And here's how it's used:
// BlogPosts.tsx
import React from "react";
import BlogCard from "./BlogCard";
type Post = {
title: string;
author: {
name: string;
};
date: Date;
timeToRead: number;
};
function BlogPosts() {
const posts: Post[] = [
{
title: "What is JavaScript",
date: new Date(),
timeToRead: 3,
author: {
name: "Dillion Megida"
}
}
];
return (
<div>
{posts.map((p, i) => (
<BlogCard key={`post-${i}`} post={p} />
))}
</div>
);
}
export default BlogPosts;
Note that the Post type does not have to be written multiple times in different files. It can be a shared type exported from its own file and used anywhere.
With the above, we do not get an error because every data type is as expected. Now let's say we added an extra property to the Post type in the blog posts like so:
type Post = {
title: string;
author: {
name: string;
};
date: Date;
timeToRead: number;
excerpt: string; // new property
}
...
We get errors in the IDE like so:
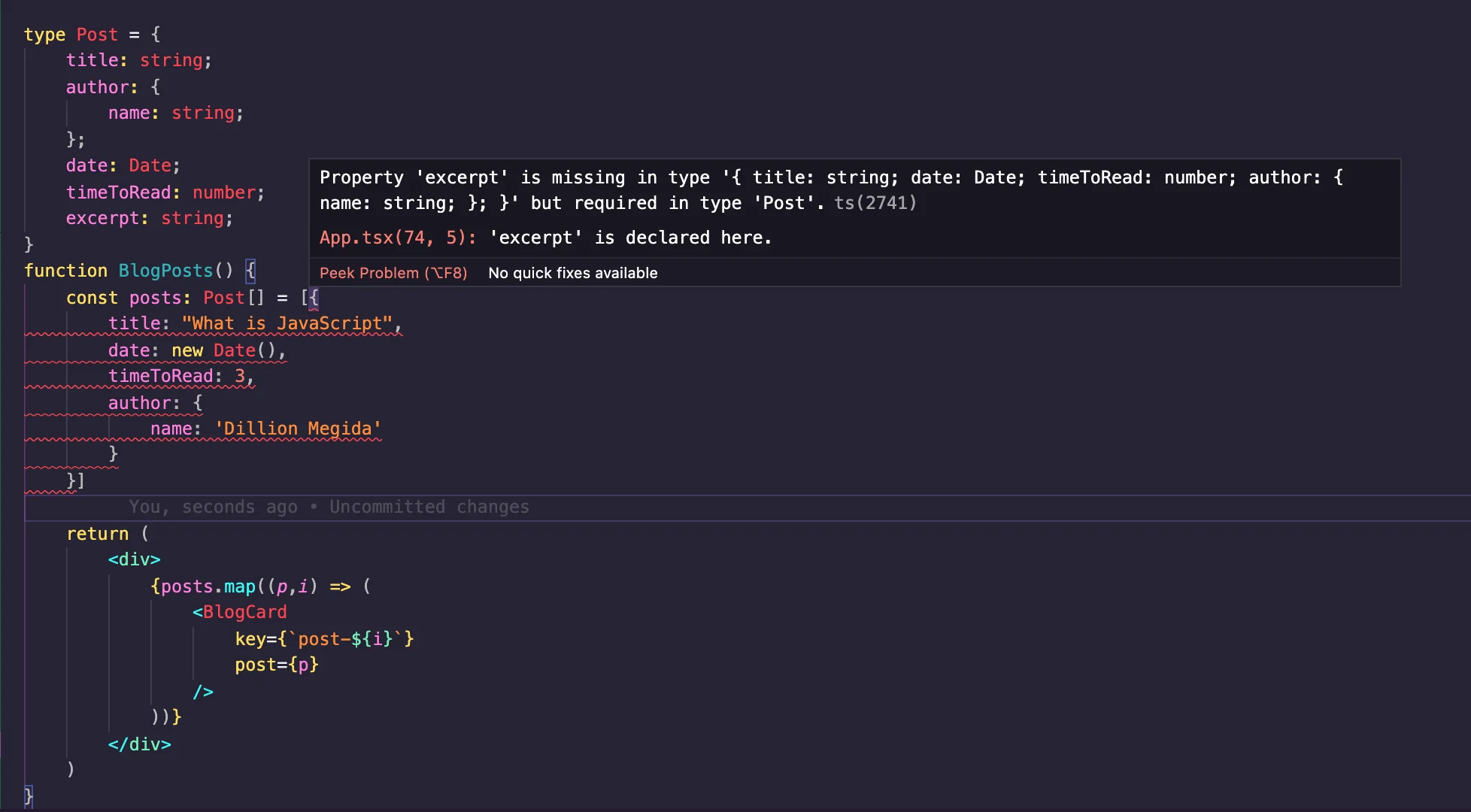
In the components examples above, we've seen how to add typings to the component's properties such that a parent components using such components would know exactly what the component wants to receive. We've seen how the Intellisense provides error messages when types are not valid.
Having an IntelliSense makes the development faster as you can easily see the warnings and errors in your IDE. Without IntelliSense, you can also verify the data types when you try building (npm run build) your React application.
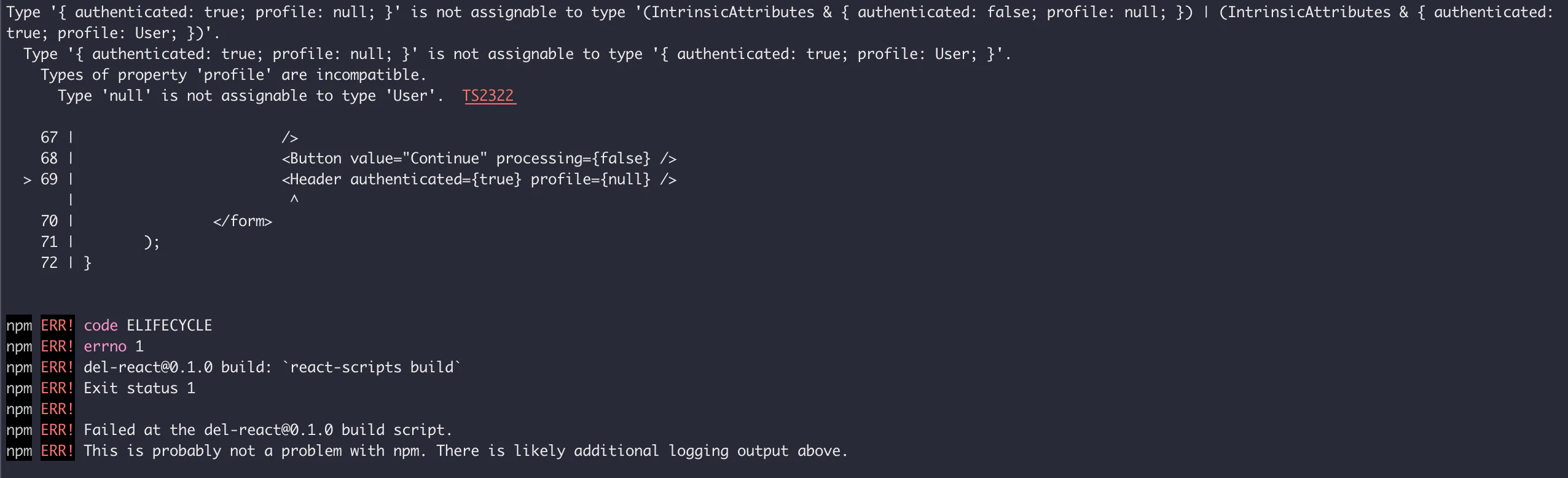
For example, using the Header component like so:
...
<Header
authenticated={true}
profile={null}
/>
...
Running npm run build for the above code gives the following error in the terminal:
The examples above are in this Stackblitz project. You can play with it, and violate expected types to see warnings.
Prop Types
TypeScript is not the only way to ensure expected data types in a React application. There are also prop-types. They are quite similar, but work in different ways. prop-types is more of an injected tool that inspects data received from an API to ensure it has the expected type. Also, it can be used in libraries that are compiled to JavaScript to be consumed by other applications. This means, even in Vanilla JavaScript, you'll still be able to catch type errors. However, prop-types is limited in the way you can specify data types compared to TypeScript. For example, prop-types cannot have interfaces, neither can they have the conditional props as we saw for the Header component.
This StackOverFlow answer shows a detailed difference between them.
Conclusion
While TypeScript has a lot of work (adding typings to almost everything) which can be strenuous, it makes developing React applications faster and with little fear of errors. You're not just limited to single types as with prop-types, but you can also specify objects of objects or literally any pattern as an expected type.
There's also more than you can do with TypeScript and React. You can further read the TypeScript Documentation to learn more.




