Remix is a React framework for building server-side rendering full-stack applications. It focuses on using web standards to build modern user interfaces. Remix was created by the team behind React Router, and was recently open-sourced for the community.
Remix extends most of the core functionality of React and React Router with server-side rendering, server requests, and backend optimization.
But why start using Remix? Remix comes with a number of advantages:
-
Nested routes - nested routes help eliminate nearly every loading state by using React Router’s outlet to render nested routes from directories and subdirectories.
-
Setup is easy! Spinning up a remix project takes just a few minutes and gets you productive immediately.
-
Remix uses server side progressive enhancement which means only necessary JavaScript, JSON, and CSS content is sent to the browser.
-
Remix focuses on server-side rendering.
-
File-system-based routing automatically generates the router configuration based on your file directory.
-
Remix is built on React which makes it easy to use if you know React.
Key Features
Let’s highlight a few key features of Remix you should be aware of.
Nested Route
Routes in Remix are file-system-based. Any component in the route directory is handled as a route and rendered to its parent outlet components.
If you define a parent component inside the routes directory, and then different routes inside a directory with the same name as the parent component, the latter will be nested within the first one.
Error boundaries
Error handling with applications is critical. In many cases, a single error can cause the entire application to be affected.
With Remix, when you get an error in a Remix component or a nested route, the errors are limited to the component and the component will fail to render or it will display the error without disrupting the entire application’s functionality.
Loading State
Remix handles loading states in parallel on the server and sends the fully formed HTML document to the browser; this eliminates the need to use a loading skeleton or spinner when fetching data or submitting form data.
Loaders and Actions
Among the most exciting features of Remix are Loaders and Actions.
These are special functions:
Loaders are functions (Hooks) that retrieve dynamic data from the database or API using the native fetch API. You can add loaders to a component by calling the useLoaderData() hook.
Actions are functions used to mutate data. Actions are mostly used to send form data to the API or database, to make changes to an API, or perform a delete action.
Building Your First Remix App
The next portion of this blog post will show you how to build your first Remix app!
We will be building a small blog app with primsa’s SQLite to store the posts.
To start a Remix project the prerequisites are:
- A familiarity with JavaScript and React
- Node.js installed
- A code editor i.e VSCode
Open your system terminal and run:
npx create-remix@latest
You can accept the default prompts or use your own preferences.
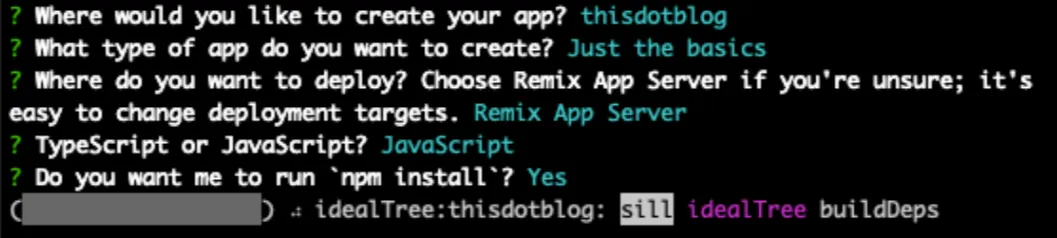
Remix will install all the dependencies it requires and scaffold the application with directories and files.
In the project’s directory let install the other dependencies we will be using, run:
npm install bootstrap
You should use something like the directory in the image.
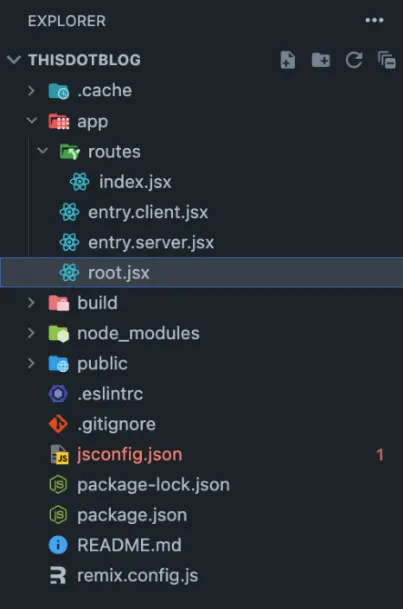
File structure walk through
The app directory contains the main building files for our Remix application.
The route directory holds all the routes that expose the exported default function as the route handler from the file.
entry.client.jsx and entry.server.jsx are core Remix’s files. Remix uses entry.client.jsx as the entry point for the browser bundle, and uses entry.server.jsx to generate the HTTP response when rendering on the server.
root.jsx is the root component of Remix application, the default export is the layout component that renders the rest of the app in an <Outlet />
These are the files we really want to touch on in our project. To learn more about the file directory, check out Remix’s API conventions.
Project set up
Open the root.jsx file and replace the code with:
import { Links, LiveReload, Meta, Outlet } from "@remix-run/react";
import bootstrapCSS from "bootstrap/dist/css/bootstrap.min.css";
export const links = () => [{ rel: "stylesheet", href: bootstrapCSS }];
export const meta = () => ({
charset: "utf-8",
viewport: "width=device-width,initial-scale=1",
});
export default function App() {
return (
<Document>
<Layout>
<Outlet />
</Layout>
</Document>
);
}
function Layout({ children }) {
return (
<>
<nav className="navbar navbar-expand-lg navbar-light bg-light px-5 py-3">
<a href="/" className="navbar-brand">
Remix
</a>
<ul className="navbar-nav mr-auto">
<li className="nav-item">
<a className="nav-link" href="/posts">Posts </a>
</li>
</ul>
</nav>
<div className="container">{children}</div>
</>
);
}
function Document({ children }) {
return (
<html>
<head>
<Links />
<Meta />
<title>ThisDot Labs Code Blog</title>
</head>
<body>
{children}
{process.env.NODE_ENV === "development" ? <LiveReload /> : null}
</body>
</html>
);
}
Since we are using bootstrap for styling we imported the minified library, Remix uses the <link rel="stylesheet"> to add stylesheet at component level using the Route Module links export.
The links function defines which elements to add to the page when the user visits the route. Visit Remix Styles to learn more about stylesheets in Remix.
Similar to the stylesheet, Remix can add the Meta tags to the route header by calling Meta Module. The meta function defines which meta elements you can add to the routes. This is a huge plus for your application’s SEO.
The app file has three components with a default export of the App component. Here, we declared a Document Component for the HTML document template, a Layout Component to further improve the template layout for rendering components, and added the {process.env.NODE_ENV === "development" ? <LiveReload /> : null} for Hot reload when changing things in the file during development.
One important note is to not confuse Links with Link. The latter, Link, is a router component for matching routes in Remix’s apps. We will handle the components to match our routes below.
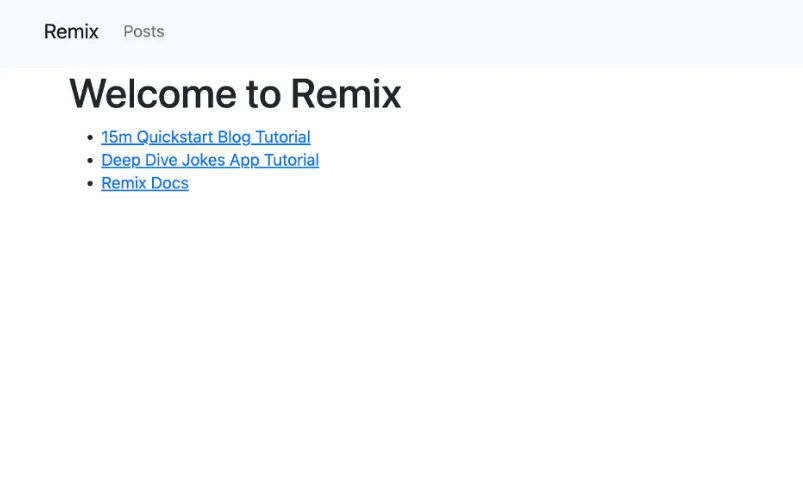
To test out the application:
npm run dev
You should have a similar app as shown below:
Let’s configure the db we will use for the app. We will use primsa SQLite to store the posts.
Install the Prisma packages in your project:
npm install prisma @prisma-client
Now let’s initialize the prisma SQlite in project:
npx prisma init --datasource-provider sqlite
This will add a Prisma directory to the project.
Open prisma/schema.prisma and add the following code at the end of the file:
model Post {
slug String @id
title String
body String
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
}
This is the schema for the blog database.
Simply, the schema is identifying that we will need a slug which will be a unique string and used for our blog’s unique route. The title property is also a string type for the title of our blog. The body type of string will hold the body, and finally we want to have the dates created and updated.
Now, let’s push the schema to Prisma:
npx prisma db push
Prisma will create a dev.db in the Prisma directory.
Now let's seed our database with a couple posts. Create prisma/seed.js and add this to the file.
const {PrismaClient} = require('@prisma/client')
const prisma = new PrismaClient()
async function seed() {
await Promise.all(
getPosts().map(post => {
return prisma.post.create({data: post})
})
)
}
seed()
function getPosts() {
return [
{
title: 'JavaScript Performance Tips',
slug: "javaScript-performance-tips",
body: `We will look at 10 simple tips and tricks to increase the speed of your code when writing JS`,
},
{
title: 'Tailwind vs. Bootstrap',
slug: `tailwind-vs-bootstrap`,
body: `Both Tailwind and Bootstrap are very popular CSS frameworks. In this article, we will compare them`,
},
{
title: 'Writing Great Unit Tests',
slug: `writing-great-unit-tests`,
body: `We will look at 10 simple tips and tricks on writing unit tests in JavaScript`,
},
{
title: 'What Is New In PHP 8?',
slug: `what-is-new-in-PHP-8`,
body: `In this article we will look at some of the new features offered in version 8 of PHP`,
},
]
}
Now edit the package.json file just before the script property and add this:
"prisma": {
"seed": "node prisma/seed"
},
"scripts": {
…
Now, to seed the db with Prisma, run:
npx prisma db seed
Our database setup is now done.
There is just one more thing for database connection, We need to create a typescript file app/utils/db.server.ts.
We specify a server file by appending .server at the end of the file name, Remix will compile and deploy this file on the server..
Add the code below to the file:
import { PrismaClient } from "@prisma/client";
let db: PrismaClient
declare global {
var __db: PrismaClient | undefined
}
if (process.env.NODE_ENV === 'production') {
db = new PrismaClient()
db.$connect()
} else {
if (!global.__db) {
global.__db = new PrismaClient()
global.__db.$connect()
}
db = global.__db
}
export { db }
Now, go back to the code editor and create post.jsx in the route directory, and add the following code:
import { Outlet } from "@remix-run/react"
function Posts() {
return (
<>
<Outlet />
</>
)
}
export default Posts
All we are doing is rendering our nested routes of posts here, nothing crazy.
Now create routes/posts/index.jsx
import { Link, useLoaderData } from "@remix-run/react";
import {db} from '../../utils/db.server';
export const loader = async () => {
const data = {
posts: await db.post.findMany({
take: 20,
select: {slug: true, title: true, createdAt: true},
orderBy: {createdAt: 'desc'}
})
}
return data
}
function PostItems() {
const {posts} = useLoaderData()
return (
<>
<div>
<h1>Posts</h1>
<Link to='/posts/new' className="btn btn-primary">New Post</Link>
</div>
<div className="row mt-3">
{posts.map(post => (
<div className="card mb-3 p-3" key={post.id}>
<Link to={`./${post.slug}`}>
<h3 className="card-header">{post.title}</h3>
{new Date(post.createdAt).toLocaleString()}
</Link>
</div>
))}
</div>
</>
)
}
export default PostItems
Here, we are declaring the loader and fetching all the posts from the database with a limit of 20 and destructuring the posts from the useLoaderData hook, then finally looping through the returned posts.
Dynamic Routes
Remix dynamic routes are defined with a $ sign and the id key. We will want to use the slugs properties as our dynamic routes for the blogs.
To do this, create app/routes/posts/$postSlug.jsx
import {Link, useLoaderData} from "@remix-run/react";
import {db} from '../../utils/db.server';
export const loader = async ({params}) => {
const post = await db.post.findUnique({
where: {slug: params.postSlug}
})
if (!post) throw new Error('Post not found')
const data = {post}
return data
}
function Post() {
const {post} = useLoaderData()
return (
<div className="card w-100">
<div className="card-header">
<h1>{post.title}</h1>
</div>
<div className="card-body">{post.body}</div>
<div className="card-footer">
<Link to='/posts' className="btn btn-danger">Back</Link>
</div>
</div>
)
}
export default Post
Here, the loader is fetching from the database using the unique slug we provided and rendering the article.
To add where to post new blogs, create app/routes/posts/new.jsx, and the following code:
import { redirect } from "@remix-run/node";
import { Link } from "@remix-run/react";
import { db } from "../../utils/db.server";
export const action = async ({ request }) => {
const form = await request.formData();
const title = form.get("title");
const body = form.get("body");
const fields = { title, body, slug: title.split(‘ ‘).join(‘-’) };
const post = await db.post.create({ data: fields });
return redirect(`/posts/${post.slug}`);
};
function NewPost() {
return (
<div className="card w-100">
<form method="POST">
<div className="card-header">
<h1>New Post</h1>
<Link to="/posts" className="btn btn-danger">
Back
</Link>
</div>
<div className="card-body">
<div className="form-control my-2">
<label htmlFor="title">Title</label>
<input type="text" name="title" id="title" />
</div>
<div className="form-control my-2">
<label htmlFor="body">Post Body</label>
<textarea name="body" id="body" />
</div>
</div>
<div className="card-footer">
<button type="submit" className="btn btn-success">
Add Post
</button>
</div>
</form>
</div>
);
}
export default NewPost;
We created an action function to handle the form post request, and Remix will catch all the formData by passing the request.
And there you have it! You’ve created a functional blog application.
Conclusion
In this article, we learned why Remix is a great choice for building your next application, and why it’s becoming a more popular framework to use amongst developers.
We also explored the core features of Remix and learned how to build a sample blog application using a database.




