Hosted by This.JavaScript, an online event where developers learn about the latest news in JavaScript, State of Frameworks and Libraries covered all the breaking news in the world of frameworks.
On Feb. 19, State of Frameworks speakers, including many of the best and brightest from the development world, gave us updates on all things frameworks.
Here’s some of what Justin Fagnani, who works at Google on Web Components and Polymer, had to say about what’s coming up for Polymer and Web Components.
Justin Fagnani — Polymer.js at Google — @justinfagnani

Releases
Since the last update, there have been a lot of releases in the Polymer project and elsewhere in the community.
Salesforce recently released their Lightning Web Components, for example. Salesforce moved their entire client-side SDK away from a custom framework type of solution to pure Web Components.
Web Components has already seen a great deal of adoption and enterprise, and Salesforce is a big move towards even more. Salesforce brings with it around 4 million developers on their platform, so this is a big deal for Web Components’ future.
Similarly, Ionic just released Ionic v4, which is a rewrite of all their libraries and components to be more framework-agnostic. Ionic is using their own stencil Web Components compiler to create all the Ionic components in there.
Also recently released are the first stable versions of LitElement and lit-html, which are the next generation libraries from the Polymer group.

LitElement and lit-html
lit-html
For those who are unfamiliar, lit-html is a new html templating engine. It write templates in JS using template literals. It also renders and updates them very efficiently, only updating the parts that change. Lit-html also doesn’t use a v-DOM or do any diffing, which both typically require overhead for the extra memory allocation.
Lit-html has several major benefits. It’s very small — only about 3.1K if modules are bundled, minified, and compressed. It’s also very fast, clocking in at around the time that Inferno runs, or sometimes even faster.
Lit-html is written nearly as pure ES2017. It’s distributed in modules, so it can be used in modern browsers with no extra steps at all. The feedback so far has been very positive, even from people working in other frameworks like Angular and React.
You can see in the syntax its dynamic and static portions. Not using a vDOM or walking the tree — instead “remembering” where the dynamic portion was and updating it as needed — saves a lot of work and adds to the ergonomy of the engine.
Lit-html recently gained some new syntax to control how bindings are implemented. You can bind to text, an attribute, or properties. You can also bind to any event using an event listener, such as bubbling or capturing an event.
The Stacklits team has been working on a template for lit-html. This template takes advantage of the fact that there’s little build required. Full page reloads are available on every keystroke; because there’s no build, it’s basically instant. This means that hot module loading is essentially available without its usual pitfalls.

LitElement 2.0
LitElement, also recently released, is a lightweight base class for Web Components, only about 2 KB on top of lit-html. LitElement uses lit-html for rendering.
It also has reactive, declarative properties and feeds them through an asynchronous rendering pipeline.
LitElement uses shadowDOM for styling and looks a lot like React but without JSX, usually using standard syntax.
Pre-release Adoption
Web Components have had several encouraging adoption announcements recently. In particular, the community is noticing early adoption from enterprises with existing design systems. Enterprises like SAP, ING, British Gas, Williams Sonoma, and others have already started using Web Components.
Chrome 73
Chrome 73 is going to ship with two great features for Web Components.
The first is Constructible StyleSheets, a feature that allows you to create a stylesheet once and parse it only once. You simply have to give it some CSS text. After that, for every component that wants to use a StyleSheet, you can add it to the shadowDOM for that component. This is just a JS reference to a single shared StyleSheet.
This feature gives a nice boost in performance of up to 30% in some benchmarks, making Web Components faster. If you mutate the stylesheet, changes can affect all of those components at once, even though they’re in encapsulated shadowRoots.
LitElements automatically uses this feature when available. Pages that use LitElement will be faster on Chrome 73.
The CSS tag will detect whether you have Constructible StyleSheets, and if you do, it will create a stylesheet out of that CSS text. If not, it will inject a plain style tag into the ShadowRoot.
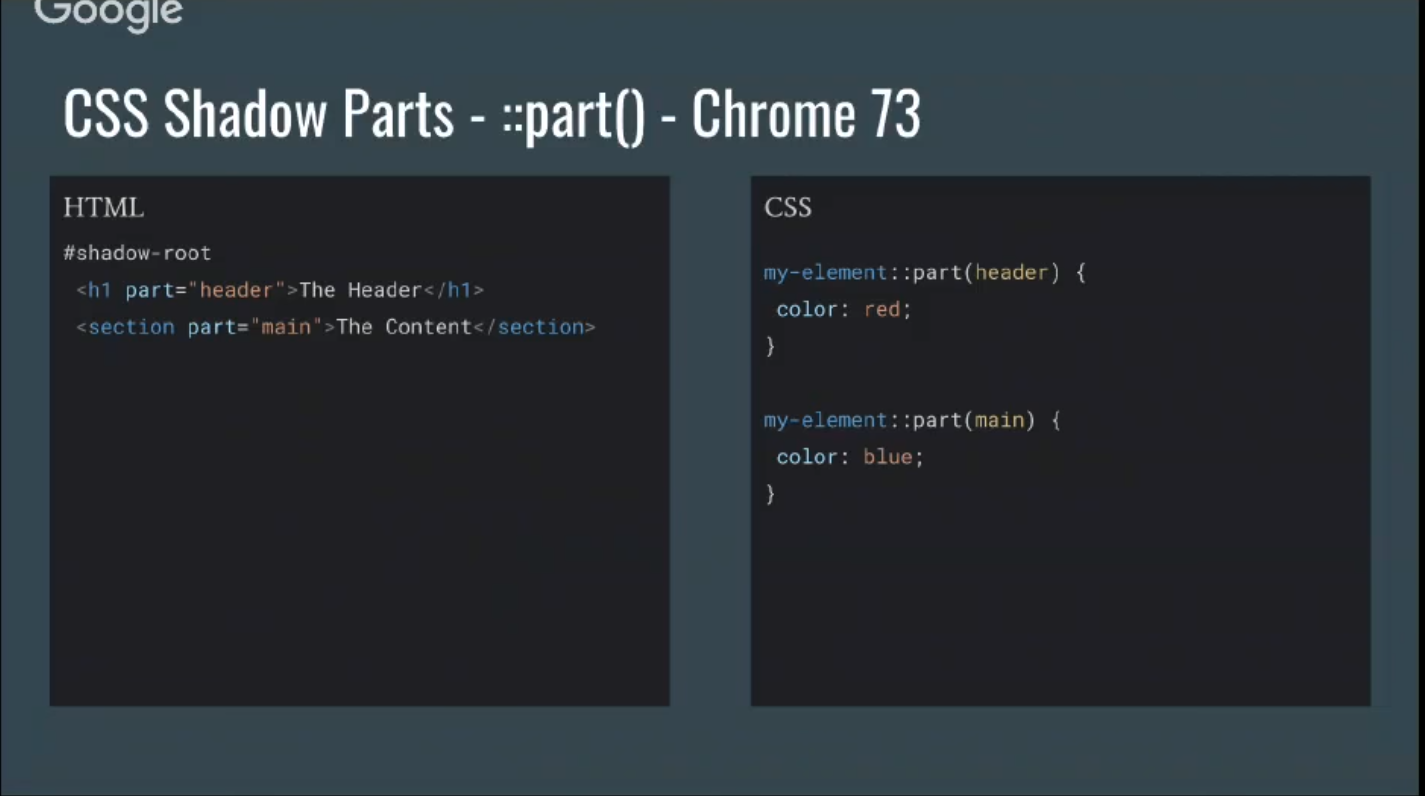
Another new feature of Chrome 73 that will have great implications for Web Components is CSS ShadowParts, or ::part().
ShadowDOM gives you style encapsulation. Sometimes you want to be able to explicitly expose something out of that ShadowRoot for styling purposes.
You add this new ::part() attribute to elements inside a ShadowRoot. Outside of the ShadowRoot, just like in Pseudo-Elements, you’re able to select a part and make styling changes. This is a really important feature for theming in an encapsulated style world.
These features will help Web Components march down this progression of enabling developers to do what only the platform could do. The story of Web Component is about gradually exposing Native features to developers. In the future, custom Pseudo-Classes will complete that story with Custom State.

Usage Stats
Looking at the stats, it’s clear that Web Components have become more popular. Almost 10 percent of page views in Chrome use Web Components. This is one of the most successful platform features launched in recent years, even more successful than Web Workers, Web Audio, and Service Workers. Nearly every web user uses Web Components every day that they browse the web.
What’s Next?
Lit-html doesn’t support SSR yet, so that’s in the works for the future. Lit-html will also eventually have streaming SSR, so that every static and dynamic chunk of lit-html can be streamed independently as it is resolved.
Developers are also working on incremental rehydration for lit-html. Build-time optimizations will decrease bootup time even further.
For Lit-Element, developers are adding ::part() support with a fall-back. Other goals include reducing bootup costs and adding SSR. There are also a number of Async Helpers in the queue for Lit-Element.
For the Native platform, template instantiation is moving forward. ::theme(), similar to ::part(), will also be implemented soon for more styling control. HTML Modules and CSS Modules are also likely in the works for the future.
On deck is also work with polyfills, making them easier to use and transparently implement the specs more accurately. This is one of the major roadblocks to Web Components adoption, so that will be a high priority going forward.



