What is the NextJS App Router and why is it important?
Why are we talking about the NextJS App Router? What’s the big deal about another application router in the React ecosystem? On the surface level, it doesn’t seem that important or interesting, but it turns out that it’s not just another run-of-the-mill routing library.
Until now, React has been a client-side library that concerned itself only with the view layer. It has avoided having opinions on just about everything that isn’t rendering your UI. But with React Server Components (RSC) on the horizon, it’s become more difficult for them to not have a concern with some of our other application layers like routing. If React is now going to have a hand in our server it’s going to need to be more integrated with our stack to be able to coordinate work from the server all the way back to the client side of the application. So what is the plan for this?
Instead of shipping a router or an entire full-stack framework, they are going to provide an API that framework authors can integrate with to support Server Components and Suspense. This is the reason why the React team has been working closely with the NextJS team. They are figuring out the API’s that React will provide and what an implementation of it will look like. Queue drumroll… Meet the NextJS App Router.
So the App Router isn’t just your grandpa’s router. It’s the reference implementation of an integration with the new RSC architecture. It’s also a LOT more than just a routing library. Glancing at the documentation page on the Next beta docs it appears to span across almost all concerns of the framework. It turns out there’s a lot of pieces involved to support the RSC puzzle.
Pieces of the App Router puzzle
On the getting started page of the NextJS beta documentation, there’s a summary list of features in the new App Router. Let’s take a look at some of the important pieces.
Routing
This seems like the most obvious one given the name “App Router”. The routing piece is extremely important to the RSC implementation. It’s still a file-based routing setup like we’re used to with NextJS with some new features like layouts, nested routing, loading states, and error handling.
This is truly where the magic happens. The docs refer to it as “server-centric” routing. The routing happens on the server which allows for server-side data fetching and fetching RSC’s. But don’t worry, our application can still use client-side navigation to give it that familiar SPA feel.
With nested routing, layouts, and partial rendering a navigation change and page render might only change a small part of the page. Loading states and error handling can be used to apply a temporary loading indicator or an error message nested in your layout to handle these different states.
Rendering
Since the App Router is RSC based, it needs to know how to render both client and server components. By default, App Router uses server components. Client components are opt-in by placing a use client directive at the top of a file. One of the main selling points of using RSCs is that you don’t have to ship JavaScript code for your RSCs in your client bundles.
You can interleave server and client components in your component tree.
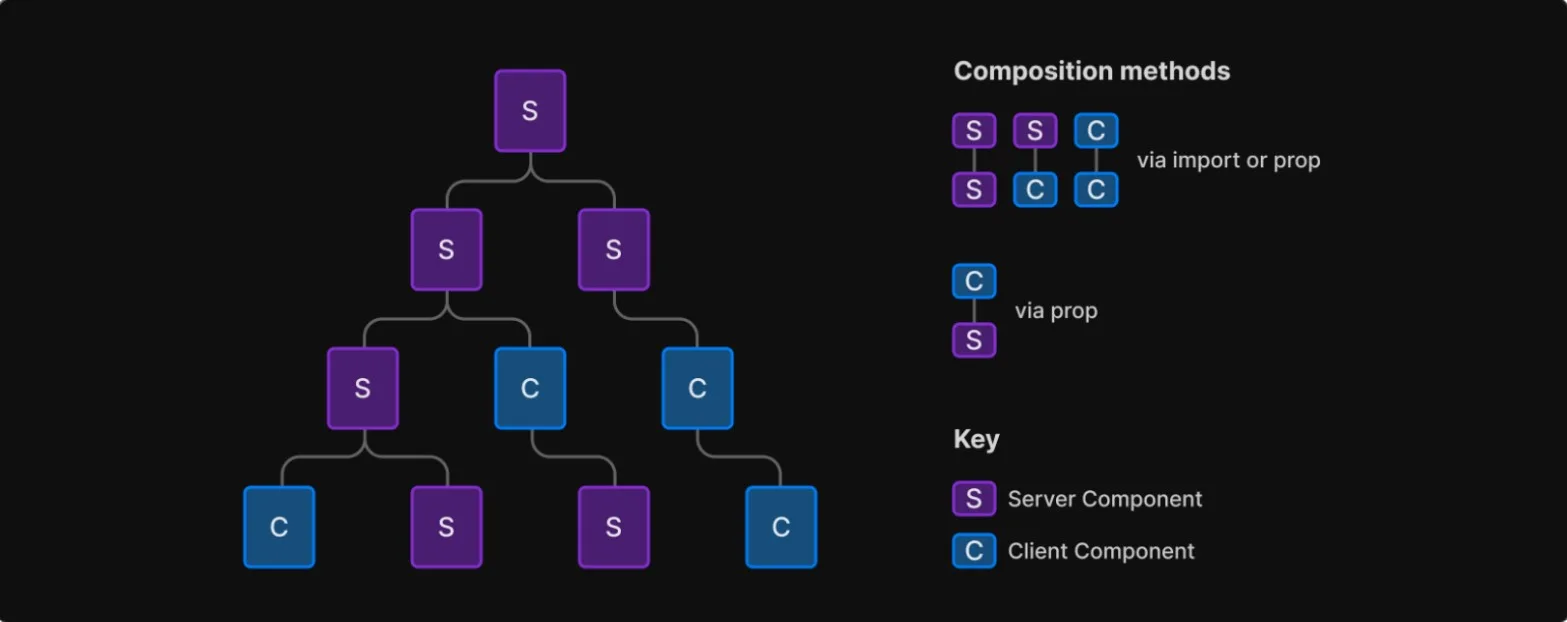
Your pages and components can still be statically rendered at build time or you have the option for dynamic (server) rendering using either node or edge runtimes.
Data Fetching
One of the main selling points of RSC is being able to collocate your data-fetching with your components. Components are able to do data fetching using async/await using the fetch API.
This will probably end up being a point of controversy since according to the documentation, both React, and NextJS “extend” the built-in fetch primitive to provide request deduping and caching/revalidation.
The docs recommend that you do your data-fetching inside server components for several different reasons.
Some of the main ones being:
- Reducing client-side waterfalls.
- Possible direct access to databases.
- Aggregating your data-fetching in requests to a single server call (think GraphQL resolvers).
This pattern is definitely becoming the norm in newer frameworks. These are similar benefits that you would reap when using something like data loaders in Remix. The big difference is that you will be able to do the fetching directly from your server components which is a nice win for co-location.
Caching
We touched on part of this in the Fetching section. It’s one of the reasons why NextJS is extending the fetch primitive. It’s adding support for caching your data using HTTP. If you’re used to client-side React, and tools like React Query, you can kind of think of this as the server version of that. If the data from a particular fetch request is already available in the cache, it will return right away, instead of making a trip to the origin server to get it.
The other piece of the App Router caching story has to do with server components specifically. NextJS App Router stores the result of RSC payloads in an in-memory client-side cache. If a user is navigating around your application using client-side navigation, and encounters a route segment that they have visited previously, and is available in the cache, it will be served right away. This will help to provide a more instantaneous feel to certain page transitions.
Tooling (bundler)
We still haven’t covered the entire App Router, and RSC story because in order to support RSC, you need a bundler that understands the server component graph. This is where Vercel’s new Webpack replacement Turbopack comes into play. It’s built on a modern low-level language named Rust. This provides improved build times and hot-module-reloading (HMR) times in development, which is fantastic. Since it’s a Webpack replacement, it will be able to handle a lot of different concerns like styles, static files, etc.
Goals of RSC and NextJS App Router
In this Twitter thread, Vercel CEO Guillermo Rauch highlights what he believes NextJS App Router brings to User Experience. The first one is that less JavaScript code gets shipped to the client. I don’t think anyone is arguing that this is not a good thing at this point. He also mentions fast page/route transitions that feel more like a SPA, and being able to quickly stream and render above-the-fold content like a hero section while the rest of the page below finishes loading.
I’ve heard a counter-argument from some RSC critics that aren’t as confident about these gains, and believe that RSC trades off UX for better DX (things like co-locating data fetching with components). Since RSC and NextJS App Router are still largely untested beta software, it’s really hard to say that this new, novel idea will be all that they are hyping it up to be.
There’s a major paradigm shift currently occurring in the community though, and there are a lot of new frameworks popping up that are taking different approaches to solving the problems brought on by the proliferation of large client-side JavaScript applications. I, for one, am excited to see if React can once again push some new ideas forward that will really change how we go about building our web applications.
Opening the black box
I don’t know about you, but I feel like I’ve been hearing about RSC for a long time now, and it’s really just felt like this fictional thing. It's as if nobody knows what it is or how it works. Its secrets are locked away inside these experimental builds that have been released by the React team. NextJS 13 Beta has finally started to give us a glimpse behind the curtain to see that it is a tangible thing, and what it looks like in practice. I’ll be honest, up to this point, I haven’t been interested enough to dig for answers to the half-baked questions and ideas about it swimming in my mind.
I know that I’m not the only one that has had this feeling. If you’re keen on learning more about what an RSC implementation looks like, there’s a good Tweet thread from Dan Abramov that highlights a lot of the important pieces and links to the relevant source code files.
Some other really curious people have also embarked on a journey to see if they could create an RSC implementation similar to App Router using Vite. The repo is a great reference for understanding what’s involved, and how things work.
What’s left?
Even if it does feel like a lot of things have been happening behind the scenes, to their credit, NextJS has provided a beta version of the new App Router that is still experimental, and very much a work in progress. We can try out RSC today to get a feel for what it’s like, and how they work. On top of that, the NextJS documentation includes a nice roadmap of the pieces that are completed, and things that are still in progress or not quite fleshed out.
As of the time of this writing, some of the major items on the list that look like blockers to a stable release are related to data fetching like use(fetch() and cache(). The most important one that I’m excited to see a solution for is mutations. They currently have a “temporary workaround” for mutations that basically involves re-running all of the data-loading in the component tree where the mutation happens. I think the plan is to have some sort of RPC built into the React core to handle mutations.
Final thoughts
It’s been a long time coming, but I for one am excited to see the progress and evolution of RSC through the new NextJS App Router. Since it’s still an experimental and incomplete product, I will wait before I do any real application development with it. But I will probably spend some time trying it out and getting more familiar with it before that day comes.




