Decomposing a project using Nx - Part 1
Working on a large codebase brings multiple challenges that we need to deal with. One of them is how to manage the repository structure and keep it as clean and maintainable as possible. There are multiple different factors that can be considered when talking about project maintainability, and one of them, that is fundamental in my opinion, is how we structure the project.
When it comes to managing large scale project which may consist of many modules, or even separate applications, a Nx Workspace based mono-repository is a good candidate for managing such a project. If you don't know what an Nx Workspace is, I encourage you to read my previous article where I introduce it along with monorepo fundamentals.
In this article series, I'll show you:
- 2 approaches for decomposing a project
- How they can help you to better manage your project's codebase
- What tools Nx Workspace provides us with that help us enforce boundaries within a project
Modules vs libraries
It is a well-known good practice, especially when working with a complex Web Application, to divide the functionality into separate, self-contained, and, when possible, reusable modules. This is a great principle and many modern CLIs (ie. Angular, Nest) provide us with tooling for creating such modules with ease, so we don't waste time creating additional module structure by hand.
Of course, we could take it a step further, and instead of just creating a separate module, create a whole separate library instead. This seems to be a bit of an overkill at first, but when we consider that Nx CLI provides us with just as easy a way of creating a library as we did for a module, it doesn't feel so daunting anymore. With that in mind, let's consider what the benefits of creating a separate library instead of just a module are:
- libs may result in faster builds
- nx affected command will run the lint, test, build, or any other target only for the libraries that were affected by a given change
- with buildable libs and incremental builds, we can scale our repo even further
- libs enable us to enforce stricter boundaries
- code sharing and minimizing bundle size is easier with libs
- we can extract and publish reusable parts of our codebase
- with small and focused libraries we only import small pieces into the application (in the case of multi-app monorepo)
Decomposition strategies - horizontal
In this article, I want to focus on horizontal decomposition strategy, which is great not only for large, enterprise projects, but for smaller applications as well. Horizontal decomposition focuses on splitting the project into layers that are focused on a single technical functionality aspect of the module. A good example of libraries type in this case is:
- application layer
- feature layer
- business logic layer
- api/data access layer
- presentational components layer
As you may see in this example layering concept, each of the library types has a specific responsibility that can be encapsulated. I have created an example application that demonstrates how the aforementioned decomposition can be applied into even a simple example app. You can find the source code on my repository. Please check out the post/nx-decomposition-p1 branch to get the code related to this post. This application allows a user to see a list of photos and like or dislike them. It is a very simple use case, but even here, we can distinguish few layers of code:
- photo-fe - frontend application top layer
- photo-feature-list - this is a feature layer. It collects data from
data-accesslayer, and displays it usinguipresentational components. - photo-data-access - this is a layer responsible for accessing and storing the data. This is where we include calls to the API and store the received data using NgRx store.
- photo-ui - this library contains all the presentational components necessary to display the list of photos
- photo-api-model, photo-model - those are libraries that contain data model structure used either in the API (it's shared by FE and BE applications), and the internal frontend model. API and internal models are the same now but this approach gives us the flexibility to, for example, stop API breaking changes from affecting the whole FE application. To achieve this we could just convert from API to internal model, and vice-versa.
This application decomposition allows for easier modifications of internal layer implementation. As long as we keep the interface intact, we can add additional levels of necessary logic, and not worry about affecting other layers. This way we can split responsibility between team members or whole teams.
Nx workspace comes with a great toolset for managing dependencies between the internal libraries. A great starting point to get a grasp of the repository structure is to visualize the repository structure, and its dependencies. The following command will show us all libraries within a monorepo and dependencies between those libraries:
nx dep-graph
It will open a dependency graph in a browser. From the left side menu, you can choose which projects you want to include in the visualization. After clicking Select all, you should see the following graph:
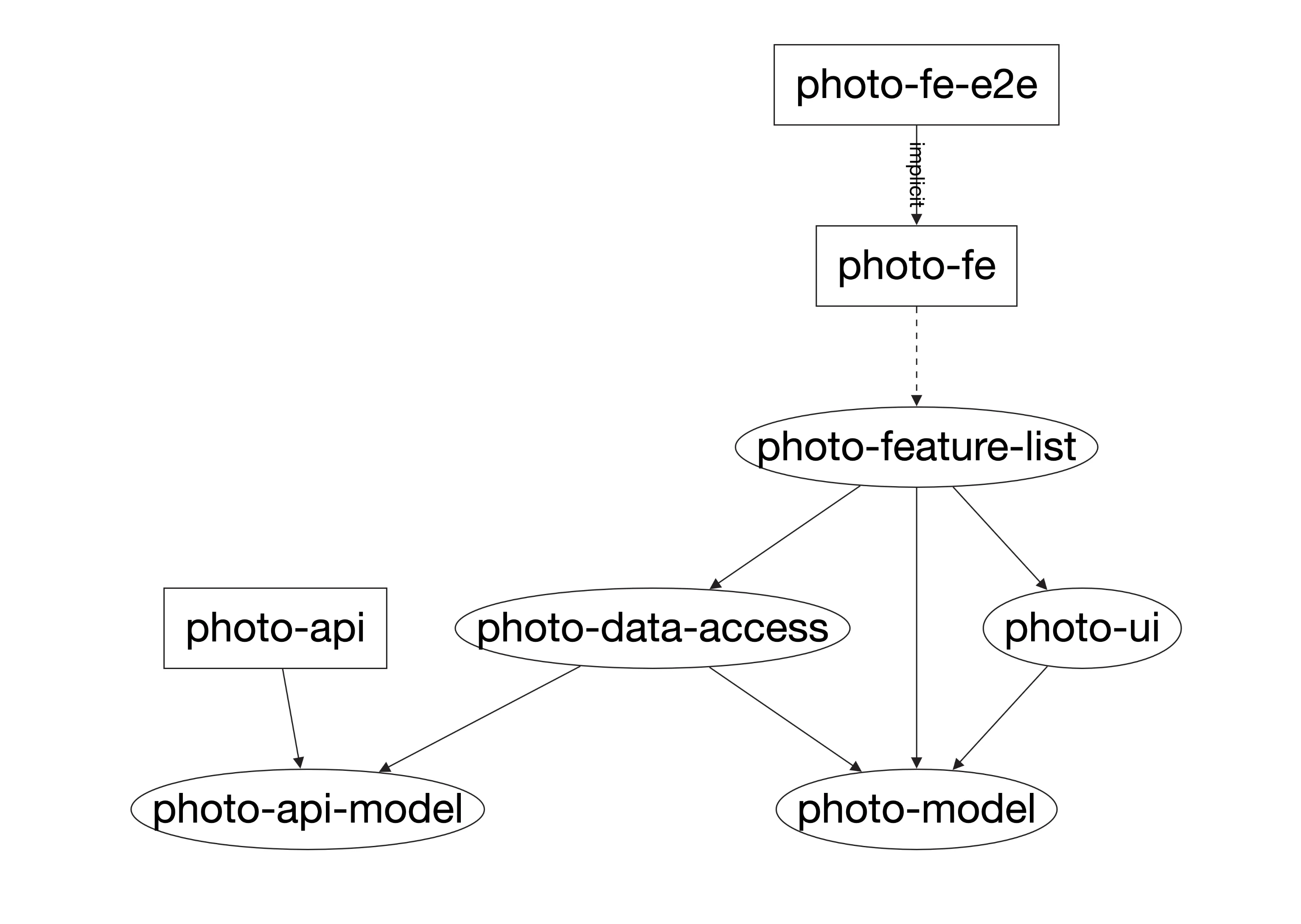
You can read more about dependecy graph here:
Enforce boundaries
As you may see in the dependency graph above, our application layer is accessing only certain other parts/libraries. As the project grows, we would probably like to make sure that the code still follows a given structure. I.e. we would not like UI presentational components to access any data access functionality of the application. Their only responsibility should be to display the provided data, and propagate user's interactions via output properties. This is where Nx tags comes in very handy. We can assign each library its own set of predefined tags, and then create boundaries base on those tags. For this example application, let's define the following set of tags:
- type:application
- type:feature
- type:data-access
- type:ui
- type:model
- type:api-model
- type:be
Now, within the nx.json file, we can assign those tags to specific libraries to reflect its intent:
"projects": {
"photo-api-model": {
"tags": [
"type:api-model"
]
},
"photo-data-access": {
"tags": [
"type:data-access"
]
},
"photo-feature-list": {
"tags": [
"type:feature"
]
},
"photo-model": {
"tags": [
"type:model"
]
},
"photo-ui": {
"tags": [
"type:ui"
]
},
"photo-fe": {
"tags": [
"type:app"
]
},
"photo-api": {
"tags": [
"type:be"
]
}
}
Now that we have our tags defined, we can use either an ESLint or TSLint rule provided by Nrwl Nx to restrict access between libraries. Those rules are named @nrwl/nx/enforce-module-boundaries and nx-enforce-module-boundaries for ESLint and TSLint respectively. Let's define our allowed libraries anteriactions as follows:
type:application- can only accesstype:featurelibrariestype:feature- can only accesstype:data-access,type:model,type:uilibrariestype:data-access- can only accesstype:api-model,type:modellibrariestype:ui- can only accesstype:ui,type:modellibrariestype:model- can not access other librariestype:api-model- can not access other librariestype:be- can only accesstype:api-modellibraries
To enforce those constraints we can add each of the rules mentioned above to the @nrwl/nx/enforce-module-boundaries, or nx-enforce-module-boundaries configuration. Let's open the top level .eslintrc.json or .tslint.json files, and replace the default configuration with the following one:
"@nrwl/nx/enforce-module-boundaries": [
"error",
{
"enforceBuildableLibDependency": true,
"allow": [],
"depConstraints": [
{
"sourceTag": "type:app",
"onlyDependOnLibsWithTags": ["type:feature"]
},
{
"sourceTag": "type:feature",
"onlyDependOnLibsWithTags": ["type:data-access","type:model", "type:ui"]
},
{
"sourceTag": "type:data-access",
"onlyDependOnLibsWithTags": ["type:api-model", "type:model"]
},
{
"sourceTag": "type:ui",
"onlyDependOnLibsWithTags": ["type:ui", "type:model"]
},
{
"sourceTag": "type:be",
"onlyDependOnLibsWithTags": ["type:api-model"]
}
]
}
]
For type:model and type:api-model, we can either not include any configuration, or explicitly add configuration with an empty array of allowed tags:
{
"sourceTag": "type:model",
"onlyDependOnLibsWithTags": []
},
{
"sourceTag": "type:api-model",
"onlyDependOnLibsWithTags": []
}
Now, you can run the following command to verify that all constraints are met:
nx run-many --target=lint --all
You can set up the CI to run this check for all the PRs to the repository, and therefore, avoid including code that does not follow the architectural pattern that you decided for your project.
If any of the aforementioned constrains were violated, the linting process would produce an error like this
A project tagged with "type:data-access" can only depend on projects tagged with "type:api-model" or "type:model".
This gives a clear message on what the problem is, and tells the developer that they are trying to do something that should not be done.
You can read more about Nx tags & constraints in the documentation.
Conclusion
When designing a software solution that is expected to grow and be maintained for a long time, it is crucial to create an architecture that will support that goal. Composing an application out of well-defined and separated horizontal layers is a great tool that can be applied to a variety of projects - even the smaller ones. Nx comes with a built-in generic mechanism that allows system architects to impose their architectural decisions on a project and prevent unrestrained access between libraries. Additionally, with a help of Nx CLI, it is just as fast and easy to create new libraries as with creating a new module. So why not take advantage of it?
In case you have any questions, you can always tweet or DM me @ktrz. I'm always happy to help!


![Quo v[AI]dis, Tech Stack? cover image](https://images.ctfassets.net/zojzzdop0fzx/28QIo74U7Nh8vFgxM7zrlJ/8b97153a1641a96380c6e9bfa32c1f95/Quo_v-AI-dis__Tech_Stack.png?fm=webp&w=3840&q=75)

