The aim of this article is to get you up to speed with the basics of Cypher(the query language used for the Neo4j graph database) in just 5 minutes! So, without further ado, let's get started!
What is a graph data structure? How is it applied in database systems?
Since we are going to show the capabilities of a graph query language, we should get familiar with what a graph is first. If you already know what it is, you can simply move to the next section.
We will skip the formal mathematical definition of a graph intentionally, and just proceed with the graphic below.
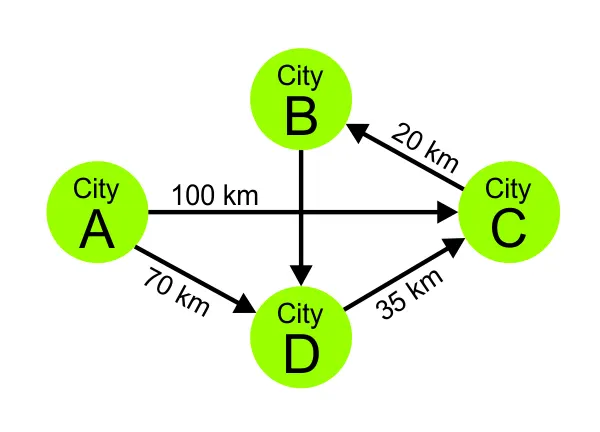
As you can see, we have a very simple map of some imaginary cities. They are marked with points or circles, and the distances between are represented by lines. This is actually a graph -- the cities are the nodes, the distances -- edges. Another way to think about it: if you know what a tree is, you can imagine the graph as a tree with loops where there is the possibility for its leafs to be connected.
Graph databases are just harnessing this data structure. Instead of tables, they make use of nodes and edges for modelling the relationship among the available data. Respectively, using a conventional query language won't be sufficient or relevant for such a database. That's where Cypher comes into play.
Our data
Since we need something to work on first, we will introduce the following graph database:
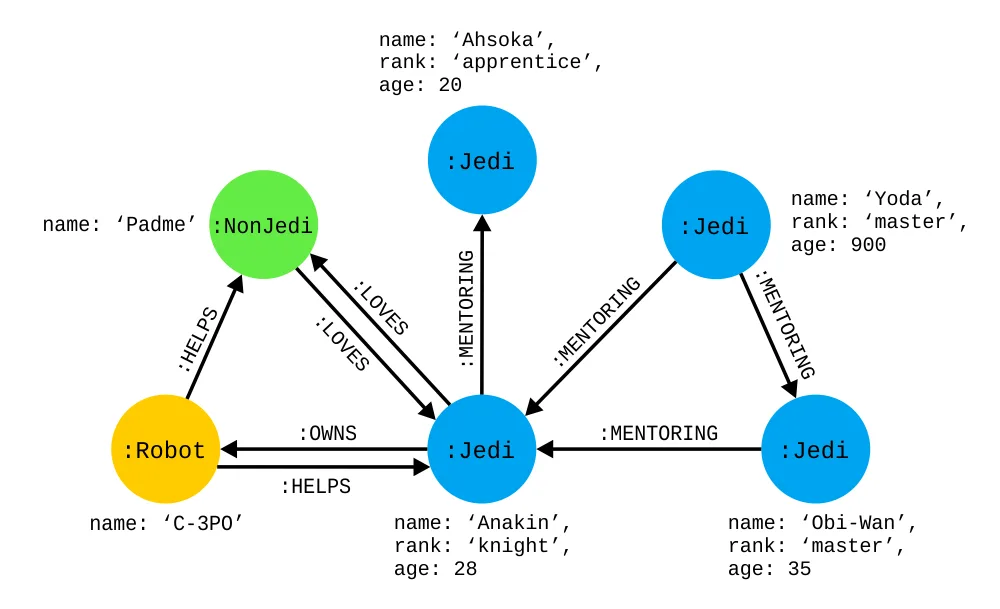
We'll use the relationship between a few of the main characters of Star Wars as an example. The blue circles represent the jedi, whereas green are non-jedi characters. Yellow, on the other hand, are the robots. All of the edges describe the relationship between these characters. As you can see, they can be both uni- and bidirectional.
Writing queries in Cypher
After having a basic understanding of what a graph is, and how the data is composed in the database, you'll find the syntax of Cypher very simple and intuitive to read and write. It is inspired by ASCII art, so you actually model your queries in a some graphical manner. Let's get started.
Nodes and relationships
Let’s start with the core structures of the graph -- nodes and relationships -- they are represented by () and [] plus < or >. For example, let's take a look at the relationship between Anakin and Padme, and how it can be represented with Cypher:
(:Jedi)-[:LOVES]->(:NonJedi)
Simple, isn't it? The arrows show how the nodes relate based on the relationship type that we have. Also, we have labels (or tags), which indicate the type of the nodes and the relationship.
Getting data with MATCH
We'll start with some basic examples of fetching data. I'll re-use the query from the previous section. Along with the MATCH keyword, we will be able to ask the database whether there are nodes that match our provided pattern, or subgraph.
The following query will return all jedi that are in love with non-jedi characters.
MATCH (j:Jedi)-[:LOVES]->(:NonJedi)
RETURN j
You probably noticed that we introduced a j in the query. This is simply a variable used for referring to the jedi node. Note that we can use these for relationships as well.
Going back to the query, you might have guessed that, in the case of our current database, we'll end up with Anakin's node being returned. That being said, we can be a bit more specific when creating the pattern:
MATCH (j:Jedi)-[:LOVES]->(:NonJedi)-[:LOVES]->(j)
RETURN j
With it, we can get not only the jedi that are in love with a non-jedi, but all jedi who are in a romantic relationship with a non-jedi (i.e. both sides love each other).
Moving forward, let's try a different query:
MATCH (Jedi)--(Jedi)
You may ask whether it's a valid one, but it completely is. We don't have to necessarily specify the relationship, nor the direction (unless we want to). That being said, this will return every pair of jedis who have a relationship between them like Yoda and Obi-Wan, Obi-Wan and Anakin, and Yoda and Anakin.
Same applies to relationship types. We can specify the type of a relationship while abstracting from node type, like:
()-[:MENTORING]->()
Conditional fetching
Just like in a conventional relational database, we can specify some criteria when fetching data. With Cypher, we have two ways to do that:
1. Inlined JSON-like object
Let's take a look at the following query:
MATCH
(j1:Jedi { rank: 'master' })-[:MENTORING]->(j2:Jedi)
RETURN
j2.name
Note: Both single and double quotes are valid.
We can describe it as: "Return the names of all jedis who are mentored by a jedi master. Again, this results in getting Anakin's name, but not Ahsoka. Now, we'll write the same query but a bit differently:
2. Using WHERE
MATCH
(j1:Jedi)-[:MENTORING]->(j2:Jedi)
WHERE
j1.rank = 'master'
RETURN
j2.name
Using the WHERE clause is equivalent to inlining the JSON-like object in a node. However, it is a fuller and more powerful way of specifying our desired criteria compared to the latter. For example, we can perform a boundary check of a numerical data, whereas that would be impossible with the first approach:
MATCH
(j1:Jedi)-[:MENTORING]->(j2:Jedi)
WHERE
j1.age < 100
RETURN
j2.name
This will return all mentees' names whose mentors are less than 100 years old (i.e. Ahsoka and Anakin).
Keep in mind that we can apply all of these for the relationships as well!
Updating the existing data
After we have a good perception of how data is fetched from the database, we can spend a minute on how it can be updated. This happens with the help of the SET keyword:
MATCH
(j:Jedi { name: 'Anakin' })
SET
j.placeOfBirth = 'Tatooine'
j.dateOfBirth = '41 BBY'
RETURN
j
The explanation is obvious -- based on the provided search criteria, we perform an update via SET on the returned results. That's it!
Creating new data
In this sub-section, we will introduce two more keywords needed for adding new data to our database. These are CREATE and MERGE. Let's start with a simple example of "create":
CREATE (:Jedi { name: 'Qui-Gon' })
As you might have guessed, it simply adds a new node to our database. But what if we want to create a relation with this node? Well, here, MERGE comes in handy. It is intended for ensuring that the provided pattern exists in the database, which means that if it doesn't, it will be created.
Using the example we have, we can extend it so that Obi-Wan is an apprentice of Qui-Gon:
CREATE
(qg:Jedi { name: 'Qui-Gon Jinn' })
MERGE
(qg)-[:MENTORING]->(:Jedi { name: 'Obi-Wan' })
That'll ensure that the non-existent Qui-Gon node will be created, whereas the existing Obi-Wan node will be reused in the specified relation, or created if unavailable.
There are a lot more other use cases. For example, you can perform different updates on creation or on match when using MERGE:
MERGE
(j:Jedi { name: 'Qui-Gon' })
ON CREATE SET
j.created = timestamp()
ON MATCH SET
j.updated = timestamp()
RETURN
j
Removing data
Finally, we'll briefly go through removing of data from our database. There isn't a lot that needs to be explained, so let's move directly to the examples that we have:
Properties and labels
This is possible using REMOVE. We first search for a pattern, then we provide a property via a variable that has to be removed:
MATCH (r:Robot { name: 'C-3PO' })
REMOVE r.age
We can do the same for labels:
MATCH (r:Robot { name: 'C-3PO' })
REMOVE r:Robot
Deleting nodes and relationships
Let’s introduce yet another keyword called DELETE. With it, we can remove single nodes, like:
MATCH (j:Jedi { name: 'Anakin' })
DELETE j
or relationships:
MATCH (:Jedi { name: 'Anakin' })-[l:LOVES]->()
DELETE l
or a node with all of its relationships altogether, using the additional DETACH keyword:
MATCH (r:Robot { name: 'C-3PO' })
DETACH DELETE r
Further information
This is a simplified article, meant as an introduction. You can always get a deeper understanding of the query language from its official docs. Anyway, hopefully you were able to get an insight of how basic CRUD queries are being created, and how intuitive Cypher is!



