
In today’s blog post, we’ll build an AI Assistant using three different AI models: Whisper and TTS from OpenAI and Llama 3.1 from Meta.
While exploring AI, I wanted to try different things and create an AI assistant that works by voice. This curiosity led me to combine OpenAI’s Whisper and TTS models with Meta’s Llama 3.1 to build a voice-activated assistant.
Here’s how these models will work together:
- First, we’ll send our audio to the Whisper model, which will convert it from speech to text.
- Next, we’ll pass that text to the Llama 3.1 model. Llama will understand the text and generate a response.
- Finally, we’ll take Llama’s response and send it to the TTS model, turning the text back into speech. We’ll then stream that audio back to the client.
Let’s dive in and start building this excellent AI Assistant!
Getting started
We will use different tools to build our assistant. To build our client side, we will use Next.js. However, you could choose whichever framework you prefer.
To use our OpenAI models, we will use their TypeScript / JavaScript SDK. To use this API, we require the following environmental variable: OPENAI_API_KEY—
To get this key, we need to log in to the OpenAI dashboard and find the API keys section. Here, we can generate a new key.
Awesome. Now, to use our Llama 3.1 model, we will use Ollama and the Vercel AI SDK, utilizing a provider called ollama-ai-provider.
Ollama will allow us to download our preferred model (we could even use a different one, like Phi) and run it locally. The Vercel SDK will facilitate its use in our Next.js project.
To use Ollama, we just need to download it and choose our preferred model. For this blog post, we are going to select Llama 3.1. After installing Ollama, we can verify if it is working by opening our terminal and writing the following command:
Notice that I wrote “llama3.1” because that’s my chosen model, but you should use the one you downloaded.
Kicking things off
It's time to kick things off by setting up our Next.js app. Let's start with this command:
npx create-next-app@latest
After running the command, you’ll see a few prompts to set the app's details. Let's go step by step:
- Name your app.
- Enable app router.
The other steps are optional and entirely up to you. In my case, I also chose to use TypeScript and Tailwind CSS.
Now that’s done, let’s go into our project and install the dependencies that we need to run our models:
npm i ai ollama-ai-provider openai
Building our client logic
Now, our goal is to record our voice, send it to the backend, and then receive a voice response from it.
To record our audio, we need to use client-side functions, which means we need to use client components. In our case, we don’t want to transform our whole page to use client capabilities and have the whole tree in the client bundle; instead, we would prefer to use Server components and import our client components to progressively enhance our application.
So, let’s create a separate component that will handle the client-side logic.
Inside our app folder, let's create a components folder, and here, we will be creating our component:
app
↳components
↳audio-recorder.tsx
Let’s go ahead and initialize our component. I went ahead and added a button with some styles in it:
// app/components/audio-recorder.tsx
'use client'
export default function AudioRecorder() {
function handleClick(){
console.log('click')
}
return (
<section>
<button onClick={handleClick}
className={`bg-blue-500 text-white px-4 py-2 rounded shadow-md hover:bg-blue-400 focus:outline-none focus:ring-2 focus:ring-blue-500 focus:ring-offset-2 focus:ring-offset-white transition duration-300 ease-in-out absolute top-1/2 left-1/2 -translate-x-1/2 -translate-y-1/2`}>
Record voice
</button>
</section>
)
}
And then import it into our Page Server component:
// app/page.tsx
import AudioRecorder from '@/app/components/audio-recorder';
export default function Home() {
return (
<AudioRecorder />
);
}
Now, if we run our app, we should see the following:
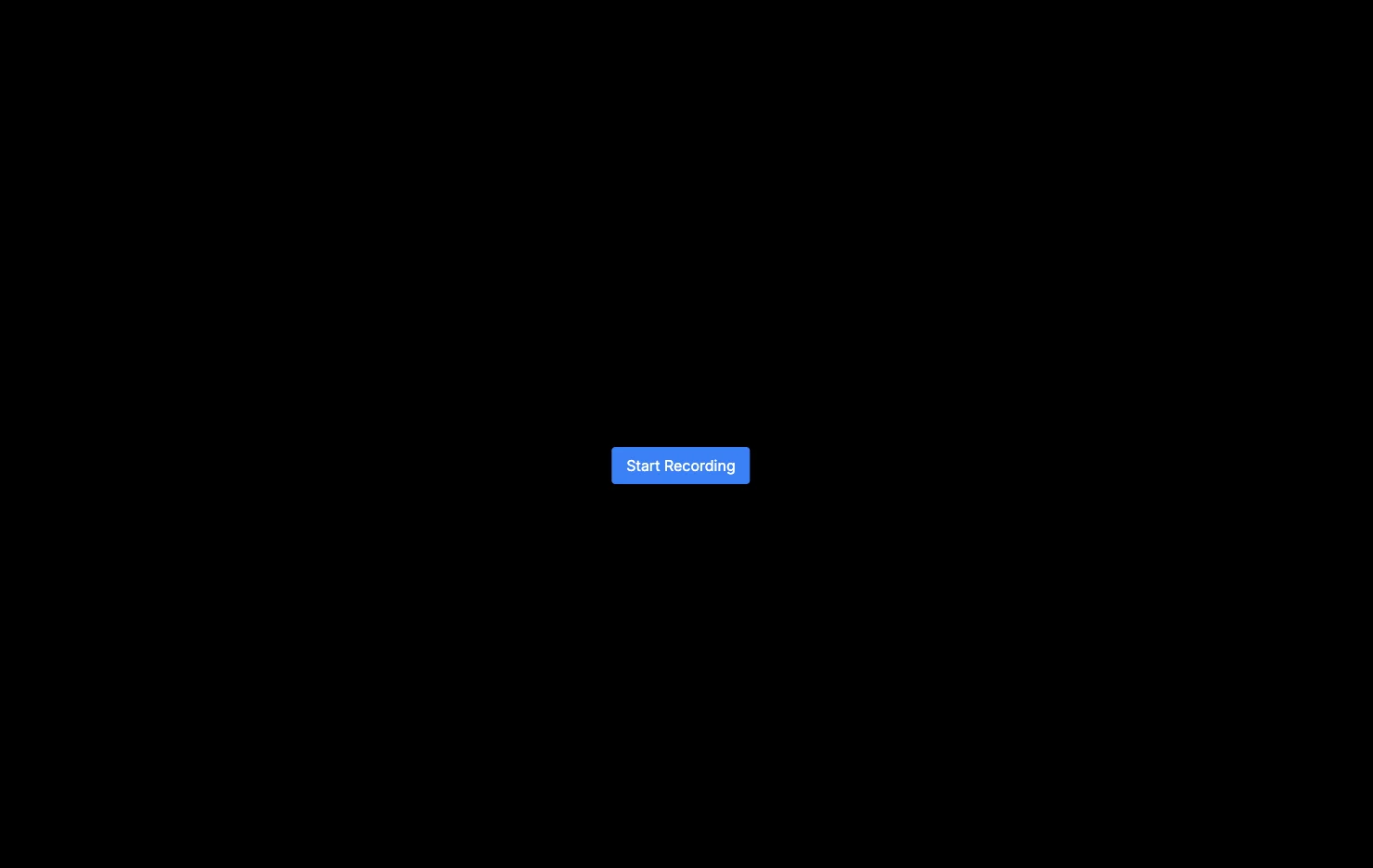
Awesome! Now, our button doesn’t do anything, but our goal is to record our audio and send it to someplace; for that, let us create a hook that will contain our logic:
app
↳hooks
↳useRecordVoice.ts
import { useEffect, useRef, useState } from 'react';
export function useRecordVoice() {
return {}
}
We will use two APIs to record our voice: navigator and MediaRecorder. The navigator API will give us information about the user’s media devices like the user media audio, and the MediaRecorder will help us record the audio from it. This is how they’re going to play out together:
// apps/hooks/useRecordVoice.ts
import { useEffect, useRef, useState } from 'react';
export function useRecordVoice() {
const [isRecording, setIsRecording] = useState(false);
const [mediaRecorder, setMediaRecorder] = useState<MediaRecorder | null>(null);
const startRecording = async () => {
if(!navigator?.mediaDevices){
console.error('Media devices not supported');
return;
}
const stream = await navigator.mediaDevices.getUserMedia({ audio: true });
const mediaRecorder = new MediaRecorder(stream);
setIsRecording(true)
setMediaRecorder(mediaRecorder);
mediaRecorder.start(0)
}
const stopRecording = () =>{
if(mediaRecorder) {
setIsRecording(false)
mediaRecorder.stop();
}
}
return {
isRecording,
startRecording,
stopRecording,
}
}
Let’s explain this code step by step. First, we create two new states. The first one is for keeping track of when we are recording, and the second one stores the instance of our MediaRecorder.
const [isRecording, setIsRecording] = useState(false);
const [mediaRecorder, setMediaRecorder] = useState<MediaRecorder | null>(null);
Then, we’ll create our first method, startRecording. Here, we are going to have the logic to start recording our audio.
We first check if the user has media devices available thanks to the navigator API that gives us information about the browser environment of our user:
If we don’t have media devices to record our audio, we just return. If they do, then let us create a stream using their audio media device.
// check if they have media devices
if(!navigator?.mediaDevices){
console.error('Media devices not supported');
return;
}
// create stream using the audio media device
const stream = await navigator.mediaDevices.getUserMedia({ audio: true });
Finally, we go ahead and create an instance of a MediaRecorder to record this audio:
// create an instance passing in the stream as parameter
const mediaRecorder = new MediaRecorder(stream);
// Set this state to true to
setIsRecording(true)
// Store the instance in the state
setMediaRecorder(mediaRecorder);
// Start recording inmediately
mediaRecorder.start(0)
Then we need a method to stop our recording, which will be our stopRecording. Here, we will just stop our recording in case a media recorder exists.
if (mediaRecorder) {
setIsRecording(false)
mediaRecorder.stop();
}
We are recording our audio, but we are not storing it anywhere. Let’s add a new useEffect and ref to accomplish this.
We would need a new ref, and this is where our chunks of audio data will be stored.
const audioChunks = useRef<Blob[]>([]);
In our useEffect we are going to do two main things: store those chunks in our ref, and when it stops, we are going to create a new Blob of type audio/mp3:
export function useRecordVoice() {
const audioChunks = useRef<Blob[]>([]);
...
useEffect(() => {
if (mediaRecorder) {
// listen to when data is available and store it as chunks in our ref
mediaRecorder.ondataavailable = (e) => {
audioChunks.current.push(e.data);
}
mediaRecorder.onstop = () => {
// Listen to when we stop recording audio
// Then, convert our data to a Blob of type audio/mp3 and reset the ref
const audioBlob = new Blob(audioChunks.current, { type: 'audio/mp3' });
audioChunks.current = [];
}
}
}, [mediaRecorder]);
...
}
It is time to wire this hook with our AudioRecorder component:
'use client'
import { useRecordVoice } from '@/hooks/useRecordVoice';
export default function AudioRecorder() {
const { isRecording, stopRecording, startRecording } = useRecordVoice();
async function handleClick() {
if (isRecording) {
stopRecording();
} else {
await startRecording();
}
}
return (
<div>
<button onClick={handleClick}
className={`bg-blue-500 text-white px-4 py-2 rounded shadow-md hover:bg-blue-400 focus:outline-none focus:ring-2 focus:ring-blue-500 focus:ring-offset-2 focus:ring-offset-white transition duration-300 ease-in-out absolute top-1/2 left-1/2 -translate-x-1/2 -translate-y-1/2`}>
{isRecording ? "Stop Recording" : "Start Recording"}
</button>
</div>
)
}
Let’s go to the other side of the coin, the backend!
Setting up our Server side
We want to use our models on the server to keep things safe and run faster. Let’s create a new route and add a handler for it using route handlers from Next.js. In our App folder, let’s make an “Api” folder with the following route in it:
We want to use our models on the server to keep things safe and run faster. Let’s create a new route and add a handler for it using route handlers from Next.js. In our App folder, let’s make an “Api” folder with the following route in it:
app
↳api
↳chat
↳route.ts
Our route is called ‘chat’. In the route.ts file, we’ll set up our handler. Let’s start by setting up our OpenAI SDK.
const openai = getOpenai();
export async function POST(req: Request) {
// our logic will go here
}
// inside a utils folder apps/utils/get-openai.ts
import OpenAI from 'openai';
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
});
export function getOpenai() {
return openai;
}
In this route, we’ll send the audio from the front end as a base64 string. Then, we’ll receive it and turn it into a Buffer object.
export async function POST(req: Request) {
const { audio } = await req.json();
const audioBuffer = Buffer.from(audio, 'base64');
}
It’s time to use our first model. We want to turn this audio into text and use OpenAI’s Whisper Speech-To-Text model. Whisper needs an audio file to create the text. Since we have a Buffer instead of a file, we’ll use their ‘toFile’ method to convert our audio Buffer into an audio file like this:
import { toFile } from 'openai';
export async function POST(req: Request) {
const { audio } = await req.json();
const audioBuffer = Buffer.from(audio, 'base64');
try {
// FileLike object
const audioFile = await toFile(audioBuffer, 'audio.mp3');
} catch (err) {
console.error(err);
return NextResponse.json(
{
err: err,
error: 'Error converting audio',
},
{
status: 500,
}
);
}
}
Notice that we specified “mp3”. This is one of the many extensions that the Whisper model can use. You can see the full list of supported extensions here: https://platform.openai.com/docs/api-reference/audio/createTranscription#audio-createtranscription-file
Now that our file is ready, let’s pass it to Whisper! Using our OpenAI instance, this is how we will invoke our model:
import { toFile } from 'openai';
const openai = getOpenai();
export async function POST(req: Request) {
...
const audioFile = await toFile(audioBuffer, 'audio.mp3');
const transcription = await openai.audio.transcriptions.create({
// here we specify the model
model: 'whisper-1',
// our audio file
file: audioFile,
});
...
}
That’s it! Now, we can move on to the next step: using Llama 3.1 to interpret this text and give us an answer. We’ll use two methods for this. First, we’ll use ‘ollama’ from the ‘ollama-ai-provider’ package, which lets us use this model with our locally running Ollama. Then, we’ll use ‘generateText’ from the Vercel AI SDK to generate the text. Side note: To make our Ollama run locally, we need to write the following command in the terminal:
ollama serve
import { toFile } from 'openai';
// new imports
import { ollama } from 'ollama-ai-provider';
import { generateText } from 'ai';
const openai = getOpenai();
export async function POST(req: Request) {
...
const audioFile = await toFile(audioBuffer, 'audio.mp3');
const transcription = await openai.audio.transcriptions.create({
model: 'whisper-1',
file: audioFile,
});
const { text: response } = await generateText({
// we specify our model running locally in the background
model: ollama('llama3.1'),
// we can set initial instructions to our model
system: 'You know a lot about video games',
// the text we want the model to interpret
prompt: transcription.text,
});
...
}
Finally, we have our last model: TTS from OpenAI. We want to reply to our user with audio, so this model will be really helpful. It will turn our text into speech:
import { toFile } from 'openai';
// new imports
import { ollama } from 'ollama-ai-provider';
import { generateText } from 'ai';
const openai = getOpenai();
export async function POST(req: Request) {
...
const audioFile = await toFile(audioBuffer, 'audio.mp3');
const transcription = await openai.audio.transcriptions.create({
model: 'whisper-1',
file: audioFile,
});
const { text: response } = await generateText({
model: ollama('llama3.1'),
system: 'You know a lot about video games',
prompt: transcription.text,
});
const voiceResponse = await openai.audio.speech.create({
// Specify here our tts model
model: 'tts-1',
// we pass in our response
input: response,
// We can choose a variety of different voices
// I chose 'onyx' but you can pick from this list: <https://platform.openai.com/docs/guides/text-to-speech/quickstart>
voice: 'onyx',
});
...
}
The TTS model will turn our response into an audio file. We want to stream this audio back to the user like this:
import { toFile } from 'openai';
import { getOpenai } from '@/utils/getOpenai';
import { ollama } from 'ollama-ai-provider';
import { NextResponse } from 'next/server';
import { generateText } from 'ai';
const openai = getOpenai();
export async function POST(req: Request) {
const { audio } = await req.json();
const audioBuffer = Buffer.from(audio, 'base64');
try {
const audioFile = await toFile(audioBuffer, 'audio.mp3');
const transcription = await openai.audio.transcriptions.create({
model: 'whisper-1',
file: audioFile,
});
const { text: response } = await generateText({
model: ollama('llama3.1'),
system: 'You know a lot about video games',
prompt: transcription.text,
});
const voiceResponse = await openai.audio.speech.create({
model: 'tts-1',
input: response,
voice: 'onyx',
});
// stream back our audio
return new Response(voiceResponse.body, {
headers: {
// we specify the content type
'Content-Type': 'audio/mpeg',
// we indicate that this is going to be streamed in chunks of data
'Transfer-Encoding': 'chunked',
},
});
} catch (err) {
console.error(err);
return NextResponse.json(
{
err: err,
error: 'Error converting audio',
},
{
status: 500,
}
);
}
}
And that’s all the whole backend code! Now, back to the frontend to finish wiring everything up.
Putting It All Together
In our useRecordVoice.tsx hook, let's create a new method that will call our API endpoint. This method will also take the response back and play to the user the audio that we are streaming from the backend.
// app/hooks/useRecordVoice.tsx
...
export function useRecordVoice() {
// new state to track when our server is loading the response for us
const [loading, setLoading] = useState(false);
async function getResponse(audioBlob: Blob) {
// We transform our audio to base64 to send it to the endpoint
const audioBase64 = await transformBlobToBase64(audioBlob);
try {
setLoading(true);
// Calling out "chat" endpoint
const res = await fetch('/api/chat', {
method: 'POST',
// Sending our base64 audio here
body: JSON.stringify({ audio: audioBase64 }),
headers: {
'Content-Type': 'application/json',
},
});
if (!res.ok) {
throw new Error('Error getting response');
}
} catch (err) {
console.error(err);
} finally {
setLoading(false);
}
}
useEffect(() => {
if (mediaRecorder) {
mediaRecorder.ondataavailable = (e) => {
audioChunks.current.push(e.data);
};
mediaRecorder.onstop = () => {
const audioBlob = new Blob(audioChunks.current, {
type: 'audio/mp3',
});
// we call our method here
void getResponse(audioBlob);
audioChunks.current = [];
};
}
}, [mediaRecorder]);
...
// app/utils/transform-blob-to-base64.ts
export function transformBlobToBase64(blob: Blob): Promise<string> {
return new Promise((resolve, reject) => {
const reader = new FileReader();
reader.onloadend= () => {
resolve(reader?.result?.toString().split(',')[1] || '');
}
reader.onerror = reject;
reader.readAsDataURL(blob);
})
}
Great! Now that we’re getting our streamed response, we need to handle it and play the audio back to the user. We’ll use the AudioContext API for this. This API allows us to store the audio, decode it and play it to the user once it’s ready:
...
async function getResponse(audioBlob: Blob) {
const audioBase64 = await transformBlobToBase64(audioBlob);
try {
setLoading(true);
const res = await fetch('/api/chat', {
method: 'POST',
body: JSON.stringify({ audio: audioBase64 }),
headers: {
'Content-Type': 'application/json',
},
});
if (!res.ok) {
throw new Error('Error getting response');
}
// Create an instance of AudioContext
const audioContext = new AudioContext();
// Create a reader to read the streaming response
const reader = res.body?.getReader();
if (!reader) {
throw new Error('Error getting response');
}
// Create a buffer source to store the audio
const source = audioContext.createBufferSource();
// Array to hold the audio chunks received from the backend
let audioChunks: Uint8Array[] = [];
// Flag to check if the audio streaming has finished
let isDataStreamed = false;
while (!isDataStreamed) {
// Start reading the data
const { value, done } = await reader.read();
// If true, the stream has finished
if (done) {
isDataStreamed = true;
break;
}
// Add each data chunk to our list of audio chunks
if (value) {
audioChunks.push(value);
}
}
// Merge all buffer chunks into a single Uint8Array
const audioBuffer = new Uint8Array(
audioChunks.reduce(
(acc, val) => acc.concat(Array.from(val)),
[] as number[]
)
);
// Decode the audio data and store it in our source buffer
source.buffer = await audioContext.decodeAudioData(
audioBuffer.buffer
);
// Connect the source to the audio output (speakers or headphones)
source.connect(audioContext.destination);
// Start playing the audio
source.start(0);
} catch (err) {
console.error(err);
} finally {
setLoading(false);
}
}
...
return {
startRecording,
stopRecording,
isRecording,
// Return the loading state
loading,
};
And that's it! Now the user should hear the audio response on their device. To wrap things up, let's make our app a bit nicer by adding a little loading indicator:
// app/components/audio-recorder.tsx
'use client';
import { useRecordVoice } from '@/hooks/useRecordVoice';
export default function AudioRecorder() {
const { isRecording, stopRecording, startRecording, loading } =
useRecordVoice();
async function handleClick() {
if (isRecording) {
stopRecording();
} else {
await startRecording();
}
}
// New condition
if (loading) {
return <div>Loading...</div>;
}
return (
<div>
<button
onClick={handleClick}
className={`bg-blue-500 text-white px-4 py-2 rounded shadow-md hover:bg-blue-400 focus:outline-none focus:ring-2 focus:ring-blue-500 focus:ring-offset-2 focus:ring-offset-white transition duration-300 ease-in-out absolute top-1/2 left-1/2 -translate-x-1/2 -translate-y-1/2`}
>
{isRecording ? 'Stop Recording' : 'Start Recording'}
</button>
</div>
);
}
Conclusion
In this blog post, we saw how combining multiple AI models can help us achieve our goals. We learned to run AI models like Llama 3.1 locally and use them in our Next.js app. We also discovered how to send audio to these models and stream back a response, playing the audio back to the user.
This is just one of many ways you can use AI—the possibilities are endless. AI models are amazing tools that let us create things that were once hard to achieve with such quality. Thanks for reading; now, it’s your turn to build something amazing with AI!
You can find the complete demo on GitHub: AI Assistant with Whisper TTS and Ollama using Next.js




